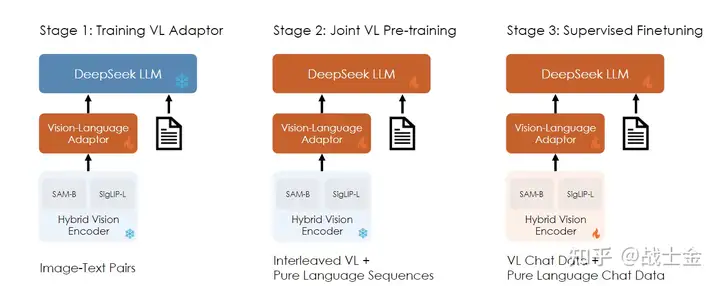
视觉语言融合新范式MemVP:基于记忆空间的多模态大模型高效微调方法

视觉语言融合新范式MemVP:基于记忆空间的多模态大模型高效微调方法
青稞作者:唐业辉,华为 · 算法研究员
声明:本文已经授权,版权归原作者!
原文:https://zhuanlan.zhihu.com/p/697627446
传统多模态模型将视觉特征和输入文本拼接起来,作为大语言模型的输入。这种方式显著增加了语言模型的输入长度,大幅拖慢了语言模型的推理速度。大语言模型中的前馈神经模块(FFN)作为记忆单元来存储学到的知识,我们提出了一种视觉模态和语言模态融合的新范式,将视觉特征直接注入到FFN的参数中,基于记忆空间来实现多模态大模型的高效微调(MemVP)。相比LoRA、VL-Adapter等现有方法,训练&推理加速2倍,在下游任务依然可以取得更高精度。
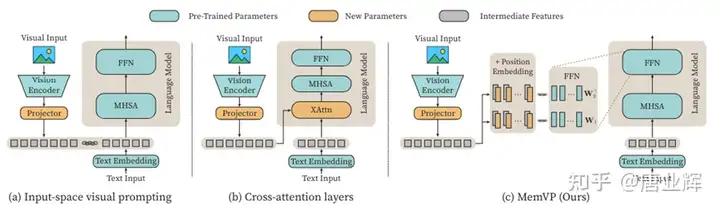

1 | paper:Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning |
` # 引言
随着视觉模型和大语言模型的发展,视觉-语言模型的构建也变得更加方便:不需要大规模的多模态预训练,只需要将视觉模型提取的视觉特征,通过projector映射到语言模型的输入token空间,并拼接到语言模型的文本tokens上作为视觉提示(prompt),在视觉-语言的下游任务上对模型进行微调即可。这一训练范式的好处在于,其引入的新参数只有轻量的projector。这意味着在微调时,只有少量的projector是必须要训练的,而预训练的视觉模型和大语言模型的微调则可以借助参数高效微调(PEFT)技术,例如LoRA,使得模型整体的训练参数量极低,大大减少了训练的显存开销。
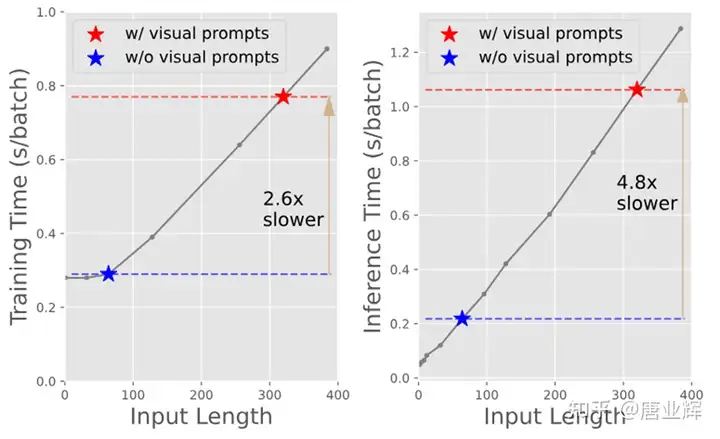
然而,这种输入空间的视觉提示方法也存在弊端。例如,LLaVA使用了CLIP-ViT-L提取的特征作为视觉提示,其长度为256。而作为比较,常用的多模态下游任务,例如VQAv2的文本输入长度仅为7左右,即使是ScienceQA这种输入复杂的数据集,平均的文本token数量也只有81。这意味着,语言模型的绝大部分计算量在于处理拼接的视觉tokens,显著减慢了训练和推理速度,并增加了训练时的显存需求。如下图,我们在V100上评测了不同输入长度下LLaMA-7B的LoRA微调和推理速度,对于输入文本tokens数量为64,输出token数量为1的样本,拼接256个视觉tokens将减慢训练速度2.6倍和推理速度4.8倍。
其他引入视觉信息的方法,例如Flamingo和BLIP使用的交叉注意力层,以及BLIP2的Q-former则引入了大量的新参数,需要进行多模态预训练,且训练过程无法实现参数高效。综上,我们需要一个既轻量,又不延长语言模型的输入长度的方法来拼接视觉和语言模型。
背景与方法
近期一些在语言模型上的研究发现,语言模型的FFN实际上作为语言模型的key-value memory来储存知识。具体而言,FFN的两个全连接层可以写成
\[\boldsymbol{W}_1 = (\boldsymbol{k}_1, \boldsymbol{k}_2, ..., \boldsymbol{k}_D), \boldsymbol{W}_2 = (\boldsymbol{v}_1, \boldsymbol{v}_2, ..., \boldsymbol{v}_D)^\intercal\]
使得
\[FFN(x)=∑i=1Dϕ(⟨x,ki⟩)⋅vi.\]
其中, \(\boldsymbol{k}_i\in\mathbb{R}^{d}\) 和 \(\boldsymbol{v}_i\in\mathbb{R}^{d}\) 就是memory的一个条目。现有的一些工作通过对FFN中memory条目的增删改可以实现对语言模型的知识更新与编辑。
受到这些工作的启发,我们认为视觉信息可以视作语言模型完成视觉-语言任务的外部知识,因此可以通过将视觉信息融入FFN层来将这些知识注入语言模型。具体而言,我们假设视觉模型提取的特征为 \(\boldsymbol{Z}=(\boldsymbol{z}_1, \boldsymbol{z}_2,..., \boldsymbol{z}_n)^\intercal\in\mathbb{R}^{n\times d'}\) ,而插入了新的视觉相关memory条目 \(\boldsymbol{k}_i\in\mathbb{R}^{d} \boldsymbol{v}_i\in\mathbb{R}^{d}\) 后的FFN层可以表示为
\[\small\texttt{FFN}(\boldsymbol{x}) = \sum^D_{i=1}\phi(\langle \boldsymbol{x}, \boldsymbol{k}_i\rangle)\cdot\boldsymbol{v}_i + \sum_{i=1}^n\phi(\langle\boldsymbol{x}, \mathcal{K}(\boldsymbol{z}_i)\rangle)\cdot \mathcal{V}(\boldsymbol{z}_i)\]
注意到,在现有的视觉-语言模型中,往往满足D远大于n,例如在LLaVA-7B中,D=11008,n=256,因此所增加的计算量是可忽略的。具体对于 \(\mathcal{K}\) 和 \(\mathcal{V}\) 的实现,我们主要实现两个功能,1)对齐 \(x_i\) 和 \(z_i\) 的维度,2)区别不同 \(z_i\) 在图片中的位置。因此我们简单地使用由一个或多个全连接层组成的projector f, 以及位置编码 \(\boldsymbol{p}^{k}, \boldsymbol{p}^{v}\in\mathbb{R}^{n\times d}\) 来实现 \(\mathcal{K}\) 和 \(\mathcal{V}\):
\[\mathcal{K}(\boldsymbol{z}_i) = \lambda f(\boldsymbol{z}_i) + \boldsymbol{p}^{k}_{i}, \quad \mathcal{V}(\boldsymbol{z}_i) = \lambda f(\boldsymbol{z}_i) + \boldsymbol{p}^{v}_{i}\] 相当于将FFN的权重修改为
\[\small\boldsymbol{W'}_1 = (\boldsymbol{k}_1, \boldsymbol{k}_2, ..., \boldsymbol{k}_D, \lambda f(\boldsymbol{z}_1) + \boldsymbol{p}^{k}_{1}, ..., \lambda f(\boldsymbol{z}_n) + \boldsymbol{p}^{k}_{n})\]
\[\small\boldsymbol{W'}_2 = (\boldsymbol{v}_1, \boldsymbol{v}_2, ..., \boldsymbol{v}_D, \lambda f(\boldsymbol{z}_1) + \boldsymbol{p}^{v}_{1}, ..., \lambda f(\boldsymbol{z}_n) + \boldsymbol{p}^{v}_{n})^\intercal\]
对于像LLaMA这样FFN使用GLU的语言模型,我们将其FFN层写为
\[\texttt{FFN}(\boldsymbol{x}) = (\texttt{SiLU}(\boldsymbol{x} \boldsymbol{W}_1) \otimes \boldsymbol{x} \boldsymbol{W}_{3}) \boldsymbol{W}_2\]
其中 \(\boldsymbol{W}_{3} = (\boldsymbol{g}_1, ..., \boldsymbol{g}_D)\) 。在此基础上,我们仍使用上述方案插入新的key-value条目,将FFN修改为
\[\texttt{FFN}(\boldsymbol{x}) = \sum^D_{i=1}\texttt{SiLU}(\langle \boldsymbol{x}, \boldsymbol{k}_i\rangle) \cdot\langle \boldsymbol{x}, \boldsymbol{g}_i\rangle\cdot\boldsymbol{v}_i+ \sum^n_{i=1}\texttt{SiLU}(\langle \boldsymbol{x}, \lambda f(\boldsymbol{z}_i) + \boldsymbol{p}^{k}_{i}\rangle) \cdot (\lambda f(\boldsymbol{z}_i) + \boldsymbol{p}^{v}_{i})\]
在这一范式下,只有projector和位置编码是新引入的参数,这相对于预训练模型参数而言是微不足道的。在下游视觉-语言任务上,我们可以冻结全部或大部分预训练的视觉和语言模型的参数,实现参数高效训练。我们将这种范式称作MemVP。整体框架以及与其他范式的对比如下图所示:
实验
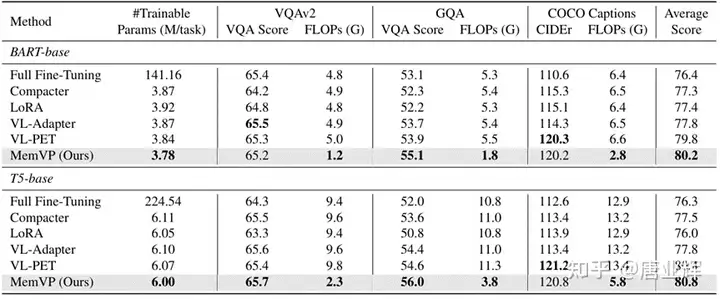
我们首先在BART-base和T5-base上进行实验,使用CLIP-ResNet101提取的视觉特征。比较的baseline是各种输入空间视觉提示框架下的PEFT方法。如下表所示,我们的MemVP方法在VQAv2,GQA,COCO Captions三个任务上的平均表现优于现有方法,且受益于较短的输入长度,语言模型具有更低的FLOPs。
如下图所示,我们还在T5-base上评测了VQAv2任务的训练时间、显存需求、以及推理时延,发现MemVP均显著优于现有的其他方法。
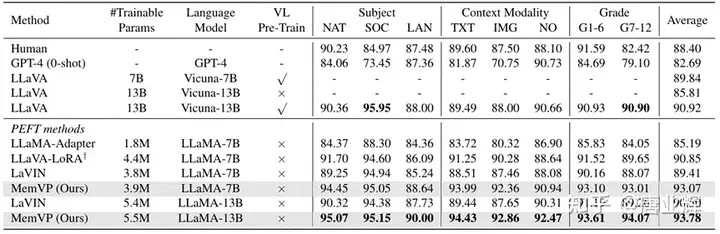
我们还在CLIP-ViT-L和LLaMA上使用ScienceQA数据集进行实验。我们的方法显著优于现有的其他方法,如LLaMA-Adapter,LLaVA-LoRA,LaVIN等。
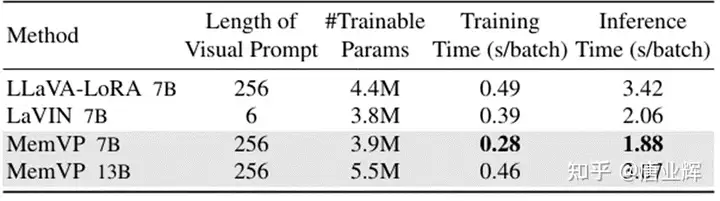
MemVP的训练和推理速度也快于其他方法。特别地,在LLaMA-13B上的MemVP实现了比LLaMA-7B上的LLaVA-LoRA更快的训练和推理速度。
总结
基于预训练视觉和语言模型,在视觉-语言下游任务上进行微调是一种高效的构造视觉-语言模型的方法。我们提出的MemVP在训练的显存开销、训练和推理的速度、微调的参数量上均实现了高效,并在多个任务上的表现优于传统的输入空间视觉提示范式。