青稞Talk 08预告!VideoBooth:文本和图像提示共同驱动的视频生成

青稞Talk 08预告!VideoBooth:文本和图像提示共同驱动的视频生成
青稞 近年来,文生视频的发展取得了巨大的进步。文生视频一般是通过一段文本来驱动视频生成。在定制化生成的任务下,用户往往想要指定生成某一特定主体的视频。
近年来,文生视频的发展取得了巨大的进步。文生视频一般是通过一段文本来驱动视频生成。在定制化生成的任务下,用户往往想要指定生成某一特定主体的视频。
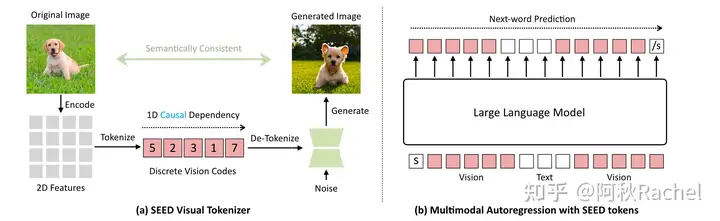
然而仅仅使用文本不足以描述主体的所有特征,因此来自南洋理工大学 MMLab 实验室和上海人工智能实验室的研究人员,在 CVPR 2024 的最新成果中,提出了一种由文本和图像提示共同驱动的视频生成方法:VideoBooth。

1
2
3paper:VideoBooth: Diffusion-based Video Generation with Image Prompts
arXiv:https://arxiv.org/pdf/2312.00777
code:https://github.com/Vchitect/VideoBooth
5月29日晚7点,青稞社区组织【青稞Talk】第八期,南洋理工大学
MMLab
实验室在读博士姜瑜铭,将直播分享《VideoBooth:文本和图像提示共同驱动的视频生成》。

直播信息
分享嘉宾
姜瑜铭,南洋理工大学 MMLab 实验室在读博士生。导师为刘子纬(Ziwei Liu)教授和吕健勤(Chen Change Loy)教授。本科毕业于电子科技大学英才实验学院。主要研究方向为内容生成和复原,在CVPR、ICCV、ECCV、SIGGRAPH、TPAMI等期刊会议上发表多篇论文。博士期间获得过Google PhD Fellowship、ICLR Notable Reviewer等荣誉。
主题提纲
VideoBooth:文本和图像提示共同驱动的视频生成
提纲:
1、视频生成技术概述
2、融合文本和图像条件视频生成框架
3、定性实验及效果展示
4、VideoBooth 的定制化训练使用
直播时间
5月29日(周三)19:00 - 20:00
参与方式
Talk
将在青稞·知识社区上进行,扫码对暗号:"0529",报名交流!