青稞Talk 17期!SEED-Story:生成长篇图文故事的多模态大型语言模型

青稞Talk 17期!SEED-Story:生成长篇图文故事的多模态大型语言模型
青稞
生成图文并茂的多模态故事已成为一个具有广泛应用前景的任务。然而,这一任务带来了巨大的挑战,因为它需要模型理解文本和图像之间复杂的相互关系,并具备生成长序列连贯且情境相关的文本和视觉内容的能力。

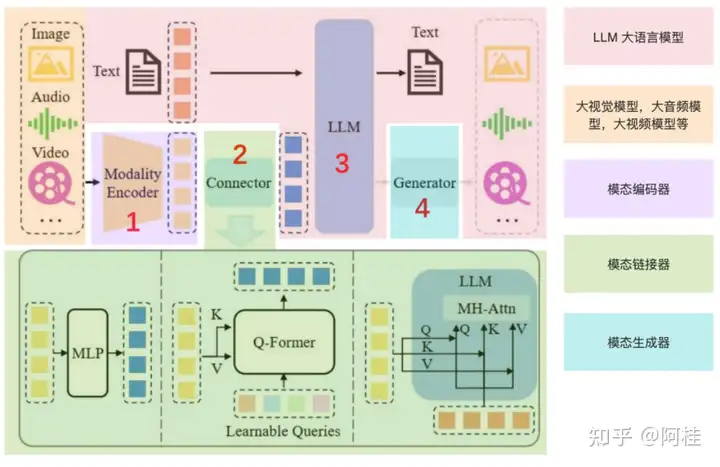
来自香港科技大学(广州)、腾讯的研究者提出了SEED-Story,这是一种利用多模态大语言模型(MLLM)生成长序列多模态故事的新方法。该模型基于MLLM强大的理解能力,预测文本token和视觉token,这些token随后通过visual de-tokenizer处理,生成具有一致角色和风格的图像。推理阶段,研究者们提出了多模态注意力汇聚机制,使得能够高效自回归地生成长达25个序列(训练时仅为10个序列)的故事。

此外,研究者们还推出了一个名为StoryStream的大规模高分辨率数据集,用于训练模型并在各个方面定量评估多模态故事生成任务。
1 | Paper:SEED-Story: Multimodal Long Story Generation with Large Language Model |
7月30日晚7点,青稞Talk第17期,香港科技大学(广州)博士生杨帅,将直播分享《SEED-Story:生成长篇图文故事的多模态大型语言模型》。

Talk信息
主讲嘉宾
杨帅,香港科技大学(广州)人工智能方向的博士研究生,导师是陈颖聪博士。他的研究方向是高效深度学习和生成模型,相关成果已发表在ICCV,ICLR,CVPR,ECCV等国际顶级会议中。详见个人主页:https://andysonys.github.io/。
主题
SEED-Story:生成长篇图文故事的多模态大型语言模型
提纲:
1、多模态内容生成的挑战
2、SEED-Story 架构及训练方法
3、大规模高分辨率数据集 StoryStream
4、SEED-Story 微调及多模态故事生成实践
直播时间
7月30日(周二)19:00 - 20:00
参与方式
Talk 将在青稞·知识社区上进行,扫码对暗号:" 0730 ",报名进群!