以DeepSeek-VL为例,详解视觉语言模型原理及代码
以DeepSeek-VL为例,详解视觉语言模型原理及代码
青稞来源: 炼钢AI@公众号
最近开始看看视觉语言模型(VLM)相关的东西了,之前没特别仔细看过代码。翻了几篇比较知名的开源VLM技术报告,感觉DeepSeek-VL算是写的比较好的,因此本文就以DeepSeek-VL为例,结合代码写一写VLM的细节。VLM和LLM比较共性的东西比如Self Attention之类的本文就不过多介绍了,重点讲一讲VLM独有的内容。
DeepSeek-VL github链接 1
https://github.com/deepseek-ai/DeepSeek-VL/tree/main
原理
模型训练
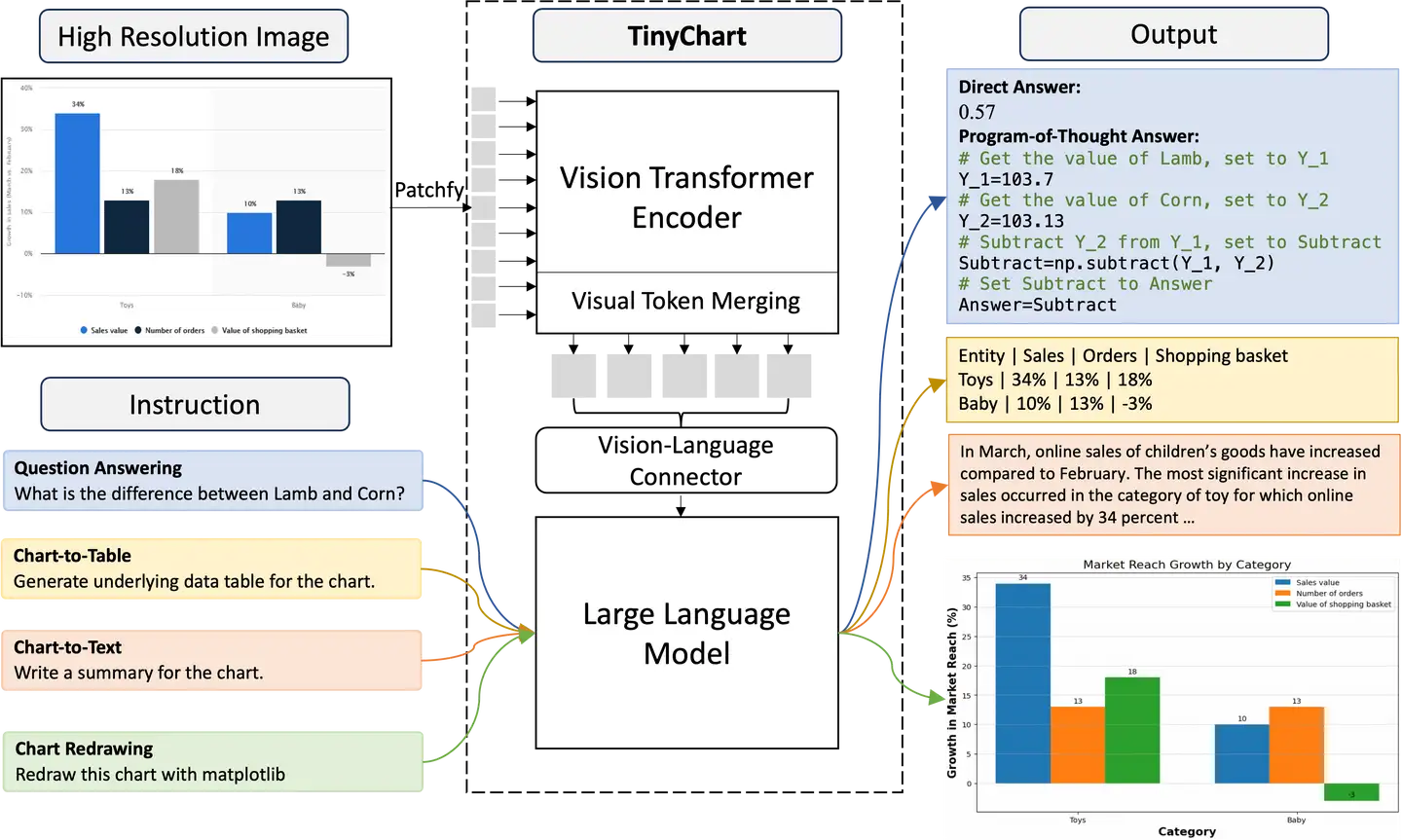
VLM通常分为3个部分:视觉编码编码器、视觉适配器和LLM。
视觉编码器用于将图像转换为向量表示,在DeepSeek-VL中,图像被视觉编码器转换为576个向量(图像的token embedding)。VLM的视觉编码器直接使其他模型预训练好的参数,普遍使用的视觉编码器结构为ViT(Vision Transformer),但可能是不同方式训练出来的,例如DeepSeek-VL使用的是Siglip和SAM训练出来的ViT,而Qwen-VL使用的是OpenCLIP的ViT。
视觉适配器用于将用于将ViT的输出图像的token embeeding映射到与文本embedding相同的空间,便于让LLM理解图像中的内容。常见的结构有多层MLP、cross attention等。
LLM是VLM的核心,视觉编码器和适配器最终产出的图像的token embedding都是要输入到LLM进行理解的,并由LLM输出关于图像的回答。
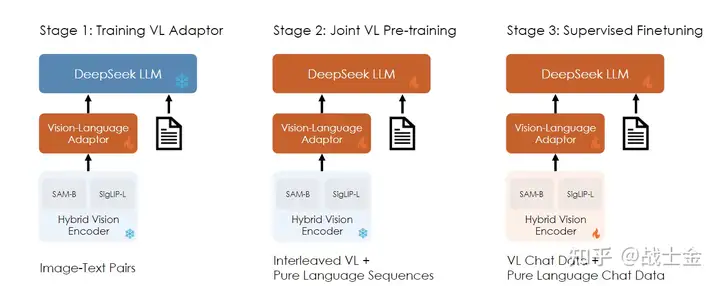
DeepSeek-VL训练可分为3个阶段(不同VLM训练的阶段数和每个阶段里训练哪部分参数会有所不同),如下图所示:
阶段1:这一阶段的主要目标是将视觉和语言信息在embedding空间建立联系,从而促进LLM能对图像中的实体有所理解。该阶段只对视觉适配器部分的参数继续进行训练,LLM和视觉编码器的参数冻结。该阶段训练了从ShareGPT4V 获得的 125 万个图像-文本对,以及 250 万个从文档OCR出来的图像文本对。
阶段2:该阶段主要目标是让LLM理解图像输入,保持图像编码器参数冻结,训练图像适配器以及LLM。如果单纯使用图像-文本对来训练LLM的话,会使LLM的语言能力下降,因此训练数据中也混合了纯文本数据,多模态数据:纯文本数据=7:3。
阶段3:该阶段是指令微调阶段,增强模型的指令遵循与对话能力。该阶段对视觉编码器、视觉适配器和LLM进行联合训练。和LLM的SFT过程类似,输入的instruct部分不计算loss。和阶段2类似,除了多模态数据外,该阶段也使用了纯文本数据进行训练。
模型结构
具体的模型结构方面,DeepSeek-VL的LLM部分使用的是自家的DeepSeek LLM模型,具体结构上也没啥特别的,本就不再过多介绍了。
视觉编码器方面,DeepSeek-VL使用了两个ViT模型:SigLIP的ViT接收384484低分辨率的图像,用来提取粗粒度的图像信息;SAM-B的ViT接收10241024的高分辨率图像,用来提取更加细致的图像信息。在介绍SigLIP和SAM之前,先简单介绍一下ViT的结构。
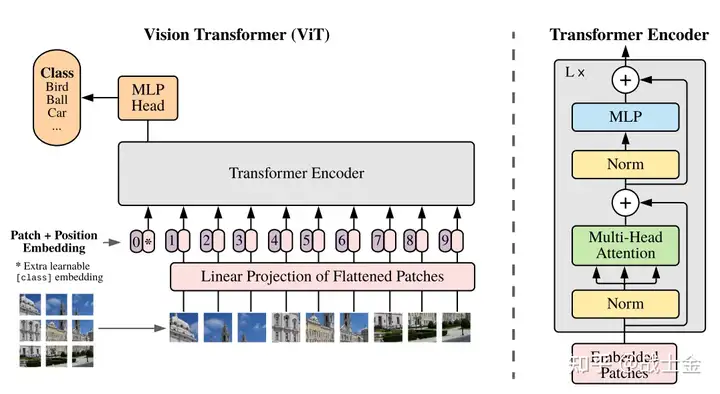
如上图所示,ViT的原理非常简单,就是将一张PP大小的图像,切分为(P/p)(P/p)个大小为pp的patch,然后用d个卷积核为pp大小的CNN将每个小patch转换为d维token embedding,并铺平成序列、加入位置编码后,就能输入到常规的Transformer Block里边了。
介绍完ViT的原理后,我们也来简单看下SigLIP和SAM的ViT结构是怎么训练的。
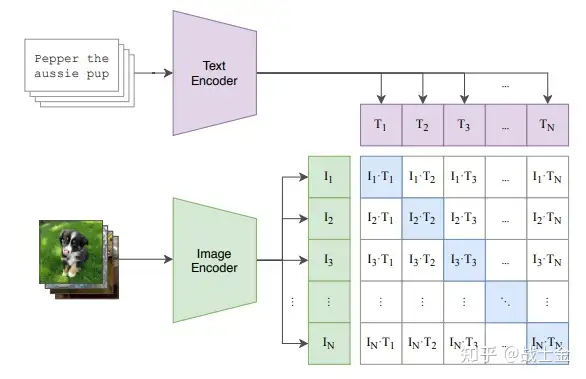
SigLIP相当于是CLIP的改进,训练范式示意图都可用下图表示。训练数据是图文对,图片和文本分别通过各自的编码器变成向量(图像编码器就是我们VLM需要ViT),然后通过训练,使图像向量和他对应的文本向量不断接近、和他不相关的文本向量不断推远。
CLIP使用的是对比学习领域的InfoNCE Loss,如下公式所示,x,y分别表示图像向量或者文本向量,和某一图片不相关的文本来自于同一个batch里其他图片相关的文本。这种负例来自于同一个batch里其他数据对的训练方式有个规律是,batch越大,训练效果越好。为了不断加大batch大小,可以采用多卡分布式训练,每次在计算loss前,做一次all gather操作,即将每张卡上的图文向量互相传播出去,这样就等价于增大batch size了,因为算softmax需要收集到所有的worker的向量,有比较大的通信开销。
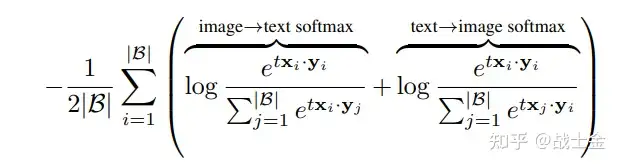
SigCLIP改进了CLIP的loss,如下公式所示,因为不涉及到softmax,不用做all gather操作,只需要进行多次两卡之间的通信,分块计算各卡之间的图像和文本的loss即可,减少了通信量及内存访问量,增加了计算效率。
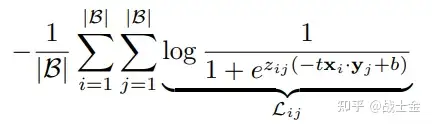
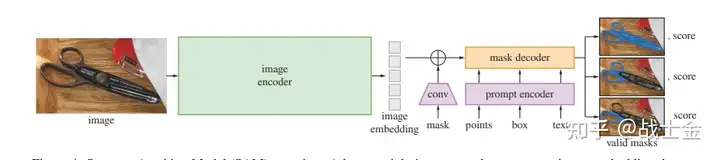
SAM是一个通用分割模型,可根据prompt(这块的prompt不只是文本,也可以是一个点,或者是图像框)对图像中的物体进行分割,整体结构如下图所示。使用图中的结构为ViT的“image encoder”当作DeepSeek-VL的图像编码器。
视觉适配器方面,DeepSeek-VL仅使用了MLP将SigLIP和SAM的ViT输出进行了融合变换,第二份部分“代码讲解”给出结构图,此处便不再赘述。
代码讲解
以deepseek-ai/deepseek-vl-7b-chat为例进行讲解,需要用到两个地方的文件/代码:
1 | 模型配置及权重文件:https://huggingface.co/deepseek-ai/deepseek-vl-7b-chat/tree/main |
从上文模型结构的相关内容可以看出,VLM和LLM在生成原理上并没有什么不同,只不过输入中引入图像token罢了。本文默认读者对LLM有一定了解,代码讲解重点放到VLM独有的一些功能上。放上官方提供的推理demo,以此为主要线索进行讲解。
1 | import torch |
首先来看一下VLM的模型文件有哪些
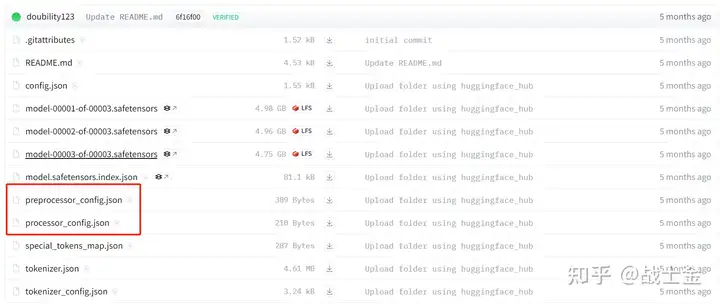
1、VLChatProcessor.from_pretrained会读取如下三个配置文件,都是和数据处理相关的,返回用于数据处理的类对象vl_chat_processor:
- tokenizer_config.json: 这个了解LLM的同学应该比较熟悉,描述了和文本相关的tokenizer信息,包括新加入词表的单词等。
- preprocessor_config.json:描述了详细的预处理图像时的数值,归一化图像数值的均值、方差,输入模型的图像大小,图像背景颜色等。
- processor_config.json:描述了图像在输入VLM
prompt中的占位符(deepseek-vl为“
”)、图像转换为token的数量(deepseek-vl为576)等。
2、DeepSeek-VL的输入数据格式如下,和LLM很像,用dict表示,除了包含角色(role)和prompt文本(content)外,还包含图像的路径(images)。“
1 | conversation = [ |
3、load_pil_images:加载图像,支持base64格式和正常的图像格式,调用比较常用的PIL.Image.open接口。
4.、DeepSeek-VL/deepseek_vl/models/processing_vlm.py 文件中的process_one函数是数据预处理的主逻辑,首席按会调用apply_sft_template_for_multi_turn_prompts接口将上述dict格式的输入转换为一个字符串,如下所示,包含system prompt,role等。然后直接使用tokenizer把字符串转换未token id。
1 | You are a helpful language and vision assistant. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. |
5、目前图像占位符(
1 | image_token_mask: torch.BoolTensor = input_ids == self.image_id |
最终的token id list如下所示:
1 | [100000, 2054, 418, 245, 9394, 4706, 285, 10046, 20308, |
6、然后调用VLMImageProcessor类对图像进行预处理,都是图像领域比较常规的一些操作:
- 图像resize:通过如下计算方法,将图像等比例的进行缩放,令图像的高或宽(较大的那个)变为self.image_size大小,防止图像畸形,然后调用expand2square方法用背景色将图像填充成self.image_sizeself.image_size(10241024)大小。
1 | width, height = pil_img.size |
- 像素值归一化:原始像素值为0-255,转换为0-1。
- 像素值标准化:均值为[0.48145466,0.4578275,0.40821073],方差为[0.26862954,0.26130258,0.27577711]
7、VLChatProcessor类还提供了batchify方法,可将多个输入打包成一个batch,用于后续进行batch推理。基本原理是将一个batch里短的序列pad到batch里最长序列的长度(左边补pad id)。通过构造attention mask,防止pad id对最终输出造成影响。
8、至此我们拿到了需要的所有token id,对于纯以文本当作输入的LLM来说,直接将token id传入LLM的调用接口就可以了,LLM会用token id去索引embedding层,得到每个token的embedding。但是对于VLM来讲,输入中有图像,图像对应的token是用另外一个视觉模型提取出来的,DeepSeek-VL设计了prepare_inputs_embeds去统一提取文本和图像的embedding。prepare_inputs_embeds调用HybridVisionTower类对象去生成图像的embedding,HybridVisionTower调用如下两个模型,两个模型输入图像分辨率不同,但是都是同一张图像,分别提取图像的粗粒度和细粒度信息。
| 模型名称 | 输入图像大小 | |
|---|---|---|
| 低分辨率模型 | siglip-ViT | 384*384 |
| 高分辨率模型 | SAM-ViT | 1024*1024 |
每张图像使用了2个视觉模型转换,输出的tensor维度均为(batchsize,image token num(576), dim(1024))还需要考虑如何进行合并,DeepSeek-VL的HybridVisionTower类提供了如下几种方法,按顺序依次为在dim维度拼接、在序列维度拼接、embedding相加,以及不处理直接返回tuple(后续别的模块处理,DeepSeek采用这种方式)。
1 | if self.concat_type == "feature": |
9、对于低分辨率模型siglip,将输入为384384大小的图像分为576(2424)个大小为1616的图像patch,然后使用1024个卷积核大小为1616,步长也为16的二维卷积,将图像转为(576,1024)大小,具体实现上,DeepSeek使用的是timm库的PatchEmbed类,感兴趣的同学可通过以下代码import之后点进类的定义看看:
1 | from timm.layers import PatchEmbed |
位置编码是可学习的位置编码,形状也为(576,1024),具体使用方式如下:
1 | # 定义位置编码 |
然后就是过12层VIT的block了,最终的输出形状也为(576,1024)。因为在推理时我们只需要用VIT拿到图像的表征,即VIT最后一层block的输出,因此DeepSeek-VL的代码中并没有体现siglip模型的sigmoid loss。
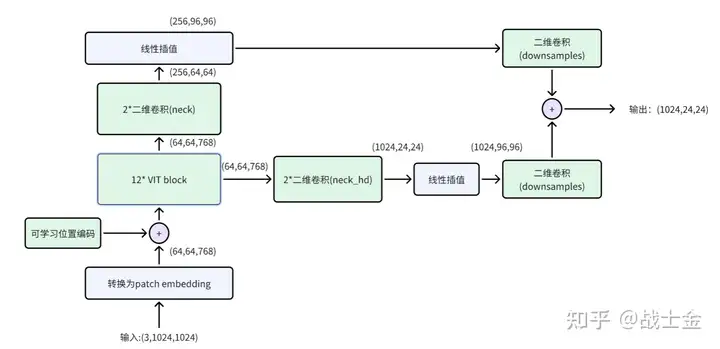
10、高分辨率模型SAM(其实只有SAM的视觉编码器部分)的结构如下图所示,比siglip结构更复杂一些。sam的一个patch依然是16*16的,使用768个2维卷积核将图像patch转换为patch embedding,因此patch embedding的形状为(64,64,768)。VIT block基本是一个transformer block,包含self attention层和FFN层。虽然输入中加入了可学习位置编码,但是在计算self attention时,依然加入了相对位置编码(代码及比较长,就不贴了,在deepseek_vl/models/sam.py的get_rel_pos和add_decomposed_rel_pos函数中实现)。sam的输出形状为(1024,24,24),reshape之后形状就和siglip输出的形状一致了,均为(576,1024)。
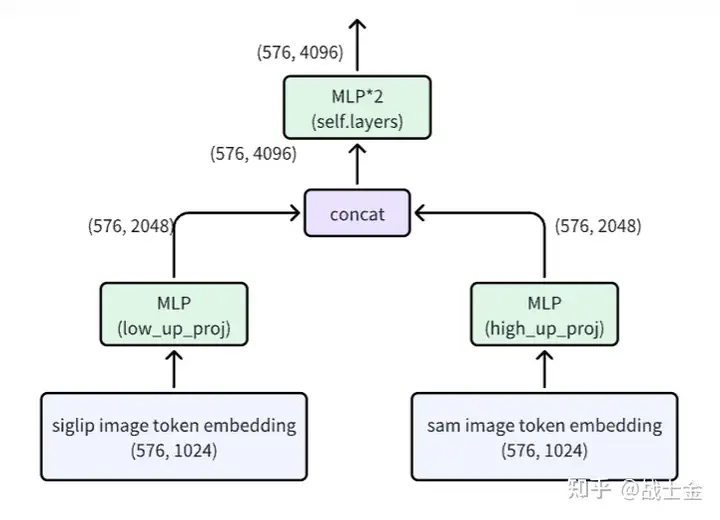
11、分别使用siglip和SAM的VIT结构得到图像的token embedding(维度都为(576,1024))表示之后,需要使用适配器(由MlpProjector类实现)将图像token embeding映射到和文本token embedding对齐。具体结构如下:
12、在最终的token id list中,id为100015(图像占位符)的位置放入适配器输出的图像的token embedding,其他token id直接从LLM的 embedding table中进行索引得到token embedding。然后将得到的所有token embedding传入LLM generate接口的inputs_embeds参数中。如果传入inputs_embeds参数,LLM内部代码就不会去用token id去索引embedding table了。
1 | outputs = vl_gpt.language_model.generate( |