大白话说什么是“MLLM”多模态大语言模型
大白话说什么是“MLLM”多模态大语言模型
青稞作者:阿桂,13年软件行业老登,数字孪生,PMP,CSPO
声明:本文已经授权,版权归原作者
原文:https://zhuanlan.zhihu.com/p/717687637
1. 什么是MLLM多模态大语言模型
1.1 先来思考一个问题

如果上传了一张图片,并向大模型提问。“图片中绿色框框中的人是谁?”
大模型回答:“那是波多野吉衣老师”
请问,大模型是怎么做到的?
我们用常规的思路来想一下,难道是:
第一步:先对图片进行目标检测,先把绿色框的内容剪切出来;
第二步:在剪切后的图片中,把人脸标记出来,并读取其landmark转为向量;
第三步:在人脸向量库中进行比对,以便于确定其身份。
整套流程下来,需要用到目标检测,人脸识别,向量存储与比对。最重要的是,还得让人脸识别模型“阅片无数”不然他是不会认识波多野结衣老师的。
但其实,多模态大模型并不是这样处理的。所谓的多模态其实可以理解就是多种数据类型,包括但不限于图片,视频,音频等。它的工作模式并不是将原来的CV模型和NLP模型,通过MultiStage的方式简单粗暴的组合在一起。而是一个端到端的思维。
1.2 为什么会有多模态大语言模型
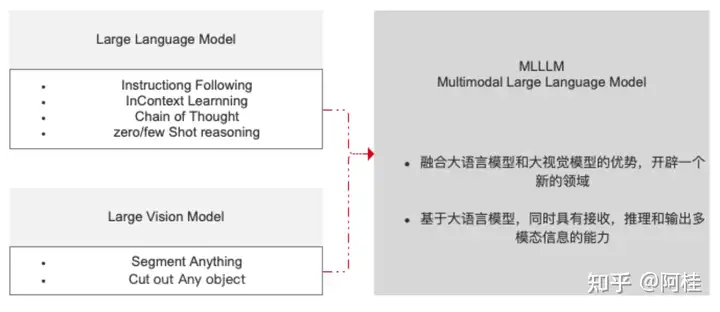
如上图所示,大语言模型有很多好处,例如指令跟随,上下文学习,思维链,少样本学习能力等。但是大语言模型天生就不是为视觉服务的,在所有的训练过程中也没有图像解释相关的数据输入。因此它天生就缺少“视觉”能力。所以,在这里我们把他比喻为知识渊博,逻辑推理能力超强,智商爆表的“瞎子”。
同时,大视觉模型也很牛逼。他可以识别&切分万事万物,但缺少逻辑推理能力。同样,这里我们也可以把它比喻成会火眼金睛的“傻子”。
为了更好的完成各类实际场景的任务,VL模型(多模态的一种,视觉&语言)就应运而生。一个“知识渊博的瞎子”&一个“火眼金睛的傻子”组合。但却实实在在的融合了两大优势,开辟了一个新的领域。
PS:我之前写过一篇基于YOLOv8目标检测,来完成物流行业人车合照的文章。当时就提出,一个完整的物流车辆人车合照流程,应该包括“目标检测(识别 人,车,车牌)”+“OCR识别(识别车牌号)”+“车牌号比对(COR识别结果与系统中登记的车牌是否一致)”+“人脸识别及比对(与驾驶证头像比对,判断是否为同一人)”这几项。
但是由于当时时间有限,只是做了“目标检测(识别 人,车,车牌)”+“OCR识别(识别车牌号)”+“车牌号比对(COR识别结果与系统中登记的车牌是否一致)”,并且还是分段调用实现的。
但,就在最近。阿里云发布了最新的Qwen-VL-Max 多模态模型。该多模态大模型理论上就可以一站式解决我上说的人车合照自动检测全部流程。
目前我这边也在测试中,如果后续有一个比较理想的结果也会跟大家分享一下整体操作的流程。

通过我上边举的“瞎子”&“傻子”的例子,再结合我遇到的人车合照自动检测的实际应用场景。希望可以帮您更好的理解MLLM。
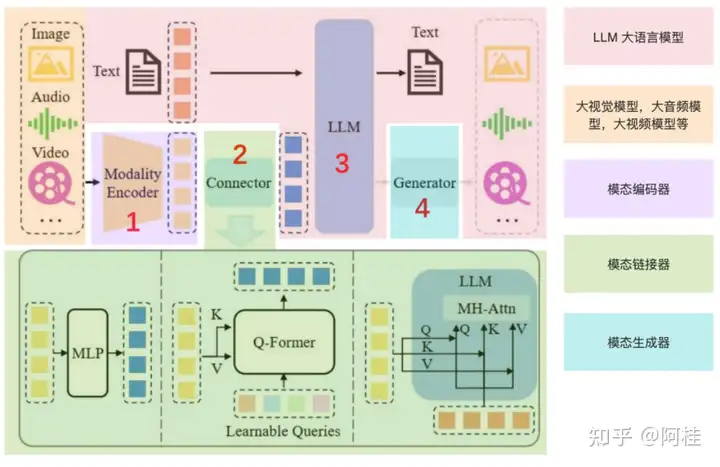
2. MLLM多模态大语言模型的核心架构
先说一下,这张图怎么去看能更方便你去理解MLLM的架构。
首先,原图是没有上图层的颜色覆盖的。这些颜色的图层覆盖,是我为了更好的理解自己添加上去的。
那么接下我们一个一个的说:
2.1 LLM大语言模型(浅粉色)
其本质就是传统的LLM,例如ChatGPT,Qwen等等。还是将文本进行向量化进行大模型,大模型输出文本结果。无论是你什么模态,大部分都是依托于大语言模型的。所以这就是为什么,我前边一直在叫MLLM为“多模态大语言模型”。
2.2 模态模型(浅黄色)& 模态编码器(浅粉色)
本来他们应该是一起的,但是了能单独的解释清楚“模态编码器”的 作用,所以在最开始的时候我选择单独标注。
其实这两个东西就是“探头模型”(大视觉,大音频等模型)的自身。
例如,一个视觉大模型。一张image输入,他本来就会调用自身的encoder进行特征抽取的,以便于后续的使用。
但是要注意,这里抽取出来的特征向量是视觉语义下的!!!
2.3 模态连接器(浅绿色)
如2.2中所说,模态模型和模态编码器输出的向量往往并不是文本语义的向量。这是需要一个连接器,你也可以理解你出国住宾馆用的插头转换器。作用是将非文本语义的特征向量转换成文本语义的特征向量。也就是将已经得到视觉或音频特征向量,转换成一个LLM(大语言模型)可以读懂的向量。
这样,这些特征就可以进入LLM了。
这里再说一下,常用的连接器有三种类型,我们可以大概了解一下:
- 基于投影的连接器:这种连接器将编码器输出的特征投影到与LLM的词嵌入相同的维度空间, 使得特征可以直接与文本令牌一起被 LLM处理
- 基于查询的连接器:这种连接器使用一组可学习的查询令牌来动态地从编码器输出的特征中提取信息。
- 基于融合的连接器:这种连接器在LLM内部实现特征级别的融合,允许文本特征和视觉特征在模型内部进行更深入的交互和整合。
2.4 模态生成器(蓝绿色)
简单来说是,根据语义生成对应的视频,音频,或者图像内容。
即,能够处理和生成特定类型数据(模态)的组件。通常用于将一种模态的信息转换为另一种模态,或者是在给定某种模态的输入时生成相应的输出。
说白话就是,我输入了一张波多野吉衣的图片,并要求大模型给我基于这张图片中的女人生成一段向我求婚的视频。那么就需要模态生成器,将输出转化为视频形式。
最后,我们来看一个多模态大语言模型,在处理任务时的一个流程示意图:
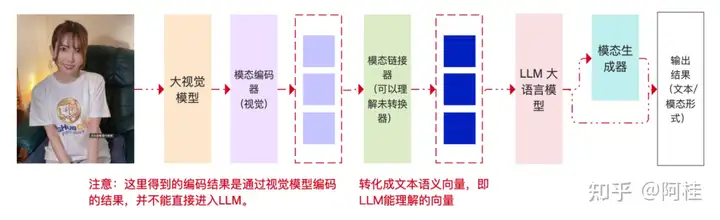
通过上图,能更明显的说明了一个事实:多模态 不等于 多阶段处理!!! 而是一种端到端的思想!!!
3. MLLM多模态大语言模型的训练
3.1 PT-预训练
让模型通过大量的未标注数据进行学习,从而获得对多种模态数据的理解能力和泛化能力。预训练的目标是使模型学会如何从不同的数据类型中提取有用的信息,并理解这些信息之间的关联。
其核心的本质是训练模态编码器。对齐不同的模态,提供世界知识。
训练的数据模版为:

其训练的本质,其实就是一个看图说话的过程。
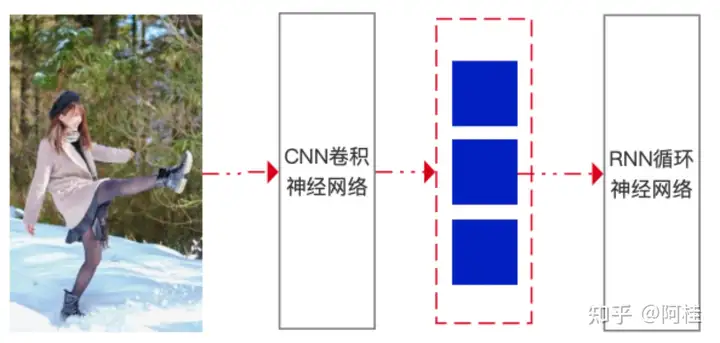
以上图为例,Input:
通过CNN进行图像数据处理,能够提取图像中的特征,如边缘、纹理等。经过CNN处理后,图像被转换为一系列的特征表示,这些特征通常以向量的形式存在,如图中红色虚线框内的蓝色矩形块。提取到的特征向量被输入到循环神经网络能够理解特征之间的顺序关系,从而生成有意义的文本输出。
最终训练完成后,在我输入这张图像以后,大模型可以通过训练得到最佳的 W和B,输出我想要的这句话。
3.2 SFT-指令微调
虽然预训练可以让模型获得广泛的知识和技能,但为了适应具体的下游任务,通常还需要一个微调的过程。在这个阶段,模型会在带有标签的数据上进一步训练,以便更好地执行特定任务,如图像分类、文本生成等。
可以让模型更好地理解用户的指令并完成所需的任务 。
提升整体泛化能力,和少(零)样本推理能力。
训练的数据模版为:

- instruction : 任务的描述
- input : image一张图像,text 一段描述的文本
- response: 提问的的输出
例如:

3.3 RLHF - 偏好对齐微调
- 对齐特定的人类偏好
- 基于人类反馈的强化学习 RLHF
- 直接偏好优化 DPO
与大语言模型的对齐微调,没有区别。就不在赘述了(主要是,我没怎么接触这块内容,不敢胡说)
4. MLLM的实操演练
前置说明:
体验平台:model scope 魔搭社区
体验模型:qwen/Qwen2-VL-2B-Instruct 2024年8月末发布的多模态模型
踩坑说明:由于我在写这篇文章时,该系列模型刚刚发布2B,7B,72B版本以及GPTQ的量化版本。整个环境依赖和与langchain的兼容还没有完善的很好。因此实际在魔搭上操作,可能会因为环境的相关依赖或版本冲突问题卡住。所以这里我指给大家做一个调用示例,供大家理解。
1 | # 下载模型 |
当然,魔搭官网上也提供了不用qwen-vl-utils工具包的使用方法。具体可以在魔搭社区查阅相关资料。
1 | #需要安装最近的torchvision |
注意:from transformers import Qwen2VLForConditionalGeneration 时可能会报错,我推测是在model scope的jupyter notebook中能引入的transformers不是最新的,并不包含Qwen2VLForConditionalGeneration。
因此,我的处理方式是,通过git clone将transformers下载至本地,然后压缩在上传至model scope的jupyter notebook。之后就是解压,进入到transformers的文件夹中,执行sudo pip install e。
但后变化的,应该逐步优化的,这里应该是直接from transformers import Qwen2VLForConditionalGeneration引入即可。
1 | #设置设备类型 |
注意:以上代码,仅是为了大家可以更好理解一下什么是多模态大语言模型,以及其核心架构和工作原理。具体调用示例,请以model scope上的相关示例为准。