青稞Talk 23预告!CogVideoX 视频生成开源模型上手实践

青稞Talk 23预告!CogVideoX 视频生成开源模型上手实践
青稞![]()
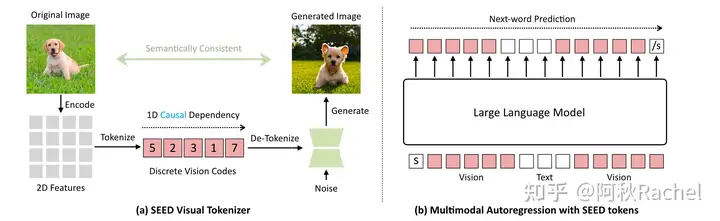
CogVideoX是智谱开源的与 清影 同源的开源版本视频生成模型,是一个大规模DiT(diffusion transformer)模型。其主要采用了以下技术:
- 3D causal VAE:通过压缩视频数据到latent space,并在时间维度上进行解码来实现高效的视频重建。
- 专家Transformer:将文本embedding和视频embedding相结合,使用3D-RoPE作为位置编码,采用专家自适应层归一化处理两个模态的数据,以及使用3D 全注意力机制来进行时空联合建模。
渐进式训练技术,让 CogVideoX 能够根据文本提示生成具有显著运动特征、连贯且长时间的高质量视频。

| 模型名 | CogVideoX-2B | CogVideoX-5B |
|---|---|---|
| 模型介绍 | 入门级模型,兼顾兼容性。运行,二次开发成本低。 | 视频生成质量更高,视觉效果更好的更大尺寸模型。 |
| 推理精度 | FP16(推荐), BF16, FP32,FP8,INT8,不支持INT4 | BF16(推荐), FP16, FP32,FP8*,INT8,不支持INT4 |
|
单GPU显存消耗 |
SAT FP16:
18GB diffusers FP16: 4GB起* diffusers INT8(torchao): 3.6G起* |
SAT BF16:
26GB diffusers BF16 : 5GB起* diffusers INT8(torchao): 4.4G起* |
| 多GPU推理显存消耗 |
FP16: 10GB* using diffusers |
BF16: 15GB* using diffusers |
|
推理速度 (Step = 50) |
FP16: ~90* s | BF16: ~180* s |
| 微调精度 | FP16 | BF16 |
| 微调显存消耗(每卡) |
47 GB (bs=1, LORA) 61 GB (bs=2, LORA) 62GB (bs=1, SFT) |
63 GB (bs=1, LORA) 80 GB (bs=2, LORA) 75GB (bs=1, SFT) |
| 提示词语言 | English* | |
| 提示词长度上限 | 226 Tokens | |
| 视频长度 | 6 秒 | |
| 帧率 | 8 帧 / 秒 | |
| 视频分辨率 | 720 * 480,不支持其他分辨率(含微调) | |
| 位置编码 | 3d_sincos_pos_embed |
3d_rope_pos_embed |
1 | Paper:CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer |
9月23日20点,青稞Talk 第23期,智谱AI算法工程师,CogVideoX作者之一张昱轩,将直播分享《CogVideoX 视频生成开源模型上手实践》

Talk 信息
主讲嘉宾
张昱轩,智谱AI算法工程师,CogVideoX作者之一;智谱多个开源仓库的核心贡献者。
主题提纲
CogVideoX 视频生成开源模型上手实践
1、CogVideoX-2B / 5B 模型详解
2、CogVideoX 代码架构解析
3、基于 CogVideoX 的基础调用及微调
4、CogVideoX-2B / 5B
工程适配实践
直播时间
9月23日(周一)20:00-21:00
参与方式
Talk 将在青稞·知识社区上进行,扫码对暗号:" 0923 ",报名进群!