多模态大模型的预训练策略探究
多模态大模型的预训练策略探究
青稞作者:阿秋Rachel
原文:https://zhuanlan.zhihu.com/p/722324120
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
多模态大模型预训练探究主要指的是在视觉指令微调前的训练阶段,让模型学会理解图像及其视觉概念,在多个模态上进行joint modeling的过程。
本文主要内容来自下列文章,探索了视觉语言预训练阶段如何设计更有利于下游任务。
- VILA: On Pre-training for Visual Language Models
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
- NVLM: Open Frontier-Class Multimodal LLMs
VILA
结论
- 好的预训练阶段可以让模型具有多图推理能力、更强的in-context learning能力、更广泛的世界知识。
- 预训练时冻结LLMs就可以实现不错的zero-shot能力,但是在in-context learning能力上会有所下降。
- 预训练阶段加入图文交替数据对性能有所提升,交替这种格式很重要。
- 在指令微调阶段加入text-only的指令数据可以弥补纯文本任务的性能退化,同时提升视觉语言任务的性能。
Updating LLM
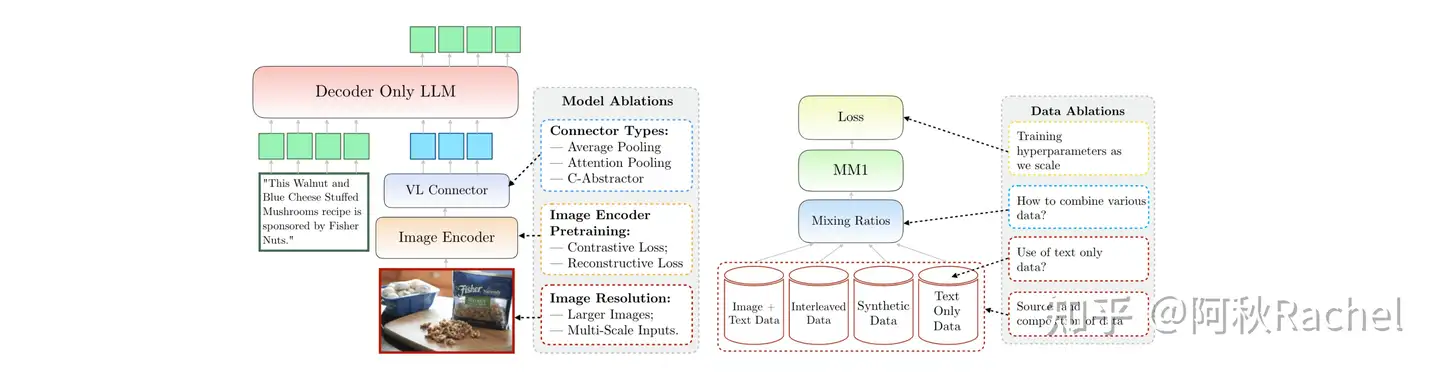
- VILA发现更新 base LLM对于MLLM获得in-context learning的能力是比较重要的(PreT和SFT代表在哪个阶段更新LLM)
- 如果只训练projector不足以实现视觉-语言理解能力,在zero-shot和few-shot的设置下性能都不太好。
- 更简单的projector效果更好,更简单的projector在输入端的text-image相似度低于复杂的projector,但是在深层的相似度会更高(相似度会有一段走低再走高的过程?)

- 因此VILA最后选取了在预训练和指令微调阶段都训练LLM,并且采用一层简单的线性层作为projector的设置。
Interleaved Visual Language Corpus
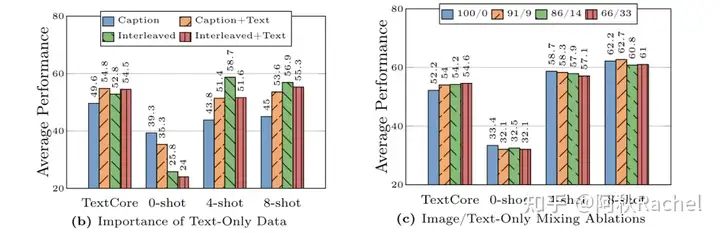
chatbot MLLM需要实现两个能力,一个是image-to-text generation能力,另一个是text-only generation能力。为了同时保证两个能力,数据融合是非常关键的。对于第一个能力,VILA主要探究了image-text pair(COYO、MMC4-pairs)和interleaved image-text dataset(MMC4)的影响。在interleaved image-text dataset上进行训练收敛地更快更好,让模型能够学会自己去挑选图像相关的信息来进行生成文本,可以提供更好的视觉语言生成的能力,由于其数据形式也更贴合纯文本预训练时预料,因此对text-only generation的能力影响也更小,但还是会造成性能退化。混合使用风味更加。
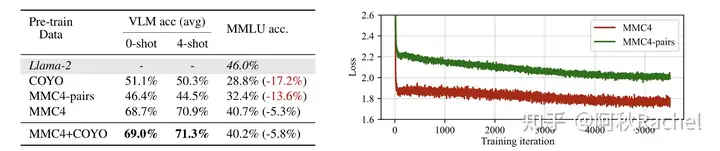
Recover LLM Degradation with Joint SFT
对于第二个text-only generation能力的维持,VILA主要通过在SFT阶段加入text-only的指令数据来实现,同时对VL任务也有提升。
搭上上述所有结论,VILA在右图text-only benchmark上13B能超过一些基座LLM(image带来了更多的知识?)
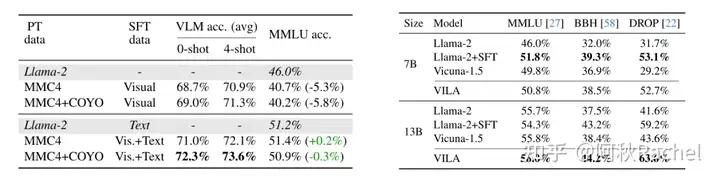
另外保留text-only generation能力的还有通过在LLM里插入额外的可训练参数来专门处理图像token或者LoRA微调LLM,但是这样对于VL任务性能提升就很有限了。

MM1
结论
- 在vision encoder部分,按照重要程度排序为:图像分辨率、视觉编码器训练任务、视觉编码器容量、视觉编码器预训练数据。
- projector结构设计不怎么重要。
- 预训练数据需要混合多种类型:interleave text-image、text-image pair、text-only。
Image Encoder & Projector
- 提高分辨率可以增加3%性能(CLIP-DFN+VeCap ViT L在224和336分辨率下比较),增加合成caption数据可以提升高于1%,增加参数量提升少于1%。
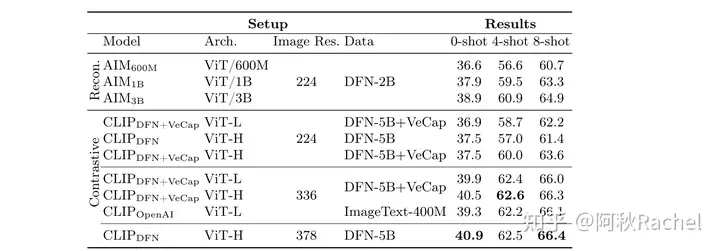
- 高分辨率的输入 + 最后保留的token数量比较重要,而projector如何压缩视觉token相对那么来说并不那么重要(few-shot任务下可能就更重要一些)
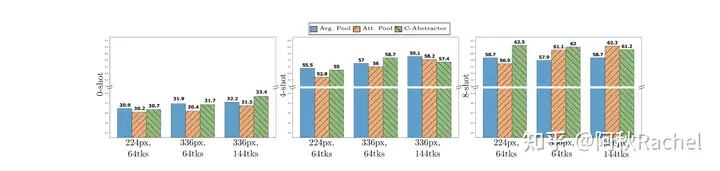
Pretraining Data
- interleave格式的数据本身就符合few-shot的格式,同时其中text信息很长,符合LLM预训练的文本分布,所以对于模型in-context learning和text-only generation能力提升有比较大的好处。
- 但是只有interleave格式的数据对in-context learning的表现并不是最佳,而且也不是占比越高越好。
- 目前大多数的benchmark evaluation都是caption problem,因此image-text pair可以提高zero-shot的能力。但zero-shot能力上反而随着interleave数据的加入越来越弱。
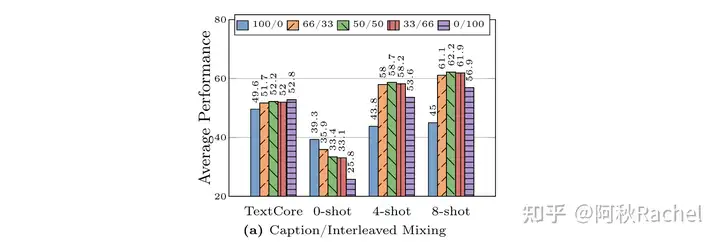
- 合成caption数据可能因为比较detailed,所以对文本性能没什么影响,但对zero-shot性能会造成明显下降,对few-shot性能提升不错。
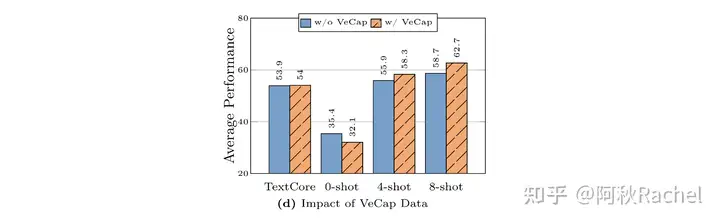
- 加入文本数据会提升text-only generation的能力,和caption数据组合会提升其in-context learning的能力,但是和interleave数据组合会损害其带来的in-context learning能力。zero-shot能力上加入text都是会掉点。
- 直接混合三者,并调整三者的混合比例仍然在zero-shot能力上有所损害但不大了,同时text-only generation能力维持的比较好。
NVLM
结论
- 数据质量和任务的多样性比数据量更重要。
- 当vision encoder比较弱且预训练数据比较丰富的时候,第一阶段放开vision encoder和projector是有增益的。
- decoder-only的架构会优于Flamingo-like的cross attention架构,尤其是在OCR&Chart类型数据上,对于text-only generation也是更好的。
Different Structure
NVLM探究了三种不同的MLLM架构——Decoder-only、cross-attention、hybrid在相同training setting下的效果。
Decoder-only架构指的是LLaVA-like,将vision token直接和text token拼接到一起,然后送入llm中。Cross-attention架构指的是Flamingo-like,将vision token通过gated cross attention模块注入信息到text token中(此处没有使用Perceive sampler作为projector)。Cross attention由于引入了额外的模块,因此参数量更多,但是输入训练长度比Decoder-only更短,因此训练更高效。
为了同时保有训练高效和joint modeling图像和文本的特性,提出了hybrid架构,对于高分辨率处理中的thumbnail提取到的视觉特征直接和text token拼接,其他子图的特征通过cross attention注入到分支。

所有架构vision encoder都采用InternViT-6B-448px-V1-5,projector均采用MLP结构,高分辨率图片都采用tile分子图的方式。

对于decoder-only结构,每个子图展平前会插入一个text-based tile tag;对于Cross attention架构,在进行高分辨率处理的时候会将text-based tile tag插入到文本序列中,通过attention mask机制保证其在cross attention部分只关注其子图内的image token;对于Hybrid架构,text-based tile tag会被插入到其cross attetion的子图视觉特征中;text-based tile tag具有如下几个形式:

经过实验decoder-only和cross attention架构下都是tile tag以1D形式组织最好,表示从左往右,从上到下是第几个子图。

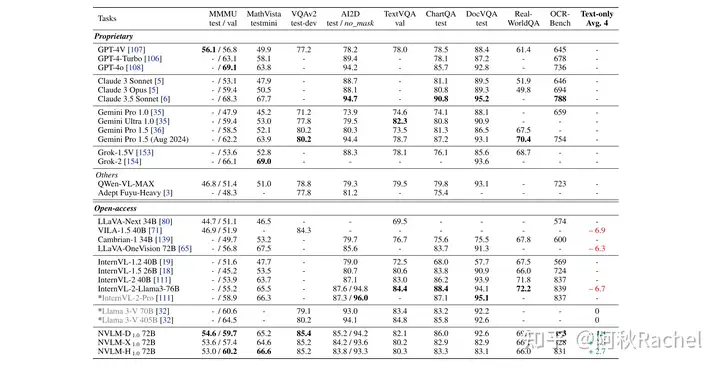
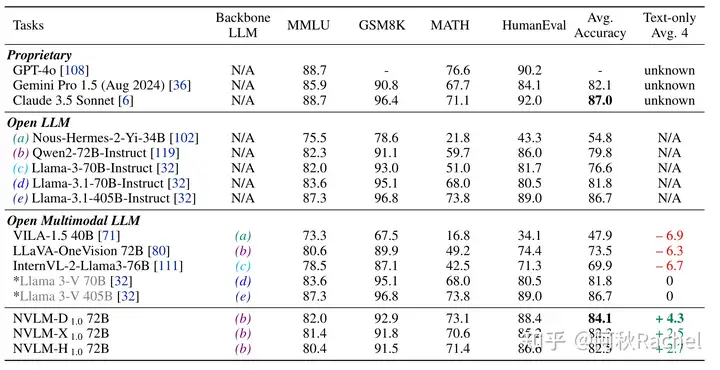
各个benchmark看下来还是decoder-only架构的比较好,尤其是在OCR & Chart benchmark上,文本保持能力也更好。
Data blend
数据质量和任务的多样性优于数据量。任务可以考虑五类分组:Caption、自然图像VQA、图表VQA、OCR和场景文字识别、数学推理。插入足量的task-oriented datasets也可以提升性能,如果知识插入少量的sft阶段的task-oriented datasets反而会导致在这些数据上过拟合。
text-only的指令数据可以被插入到SFT阶段去防止灾难性遗忘,保留text-only generation生成能力。NVLM采集了开源的text-only SFT dataset,并且补充了math category、code category的text数据。并且使用GPT-4o和GPT-4o-mini去增强了这些文本数据的质量。
decoder-only架构下保留最好,math上提升显著。
总结
Q1:预训练的关键要素。
A1:训练策略上确定不同阶段冻结的组件应该是哪些 + 数据类型和配比。预训练通常都是需要先经过一个阶段的视觉概念学习,然后再经过一个多任务学习阶段。如果vision encoder足够强了,在视觉概念学习阶段就无需放开训练,否则可以考虑和projector一起训。llm在视觉概念学习阶段通常是frozen的,但有时候两个阶段也可以合在一起,可以采用比较强的vision encoder,就不用纠结是否打开vision encoder训练了,如果不够强数据量又足够,就三个组件都打开一起训练。数据类型分两个方面,大的来说是interleave、pair、text,小的来说是多种任务。对于大的方面数据配比上来说,MM1给出的结论5:5:1。小的方面配比来说,任务尽可能的越通用越丰富越好,似乎没有看到强调任务间的配比,最多是loss权重 / 采样权重依据数据量占比确定。
Q2: Interleave数据对于预训练性能的影响。
A2:可以提升text-only generation和few-shot image-to-text generation的性能,想要发挥更好的增幅需要合适的配比。但它会对zero-shot image-to-text generation性能造成较大的危害。究竟Interleave是怎么起作用的感觉还是缺少一些更deep dive的研究。
Q3:维持text-only generation的性能
A3:先回答问题就是考虑插入高质量的text instruciton到SFT阶段,但是要注意数据配比。之前一直对这种胶水多阶段训练的范式并不是很感冒,因为早期刷到了一些文章说文本能力会下降,加之这种胶水层给人的感觉就是将visual signal当成了prompt而不是knowledge去学,想要对齐又困难,就怪怪的。直到NVLM和LLaMA-3.2 vision正式把text benchmark这件事拿出来说,并且相比语言基座有明显提升,这条路才算让我看到点希望。但也不禁让人去想,为什么都是胶水训练就他们做到了提升。
由于LLaMA-3.2 vision并没有详细的technical report,只给出结构上的说明,因此还是主要从NVLM角度思考,给出一个猜想:提高了text-only generation的性能,大概率是学习到新的知识,这种知识大概率的抓手是math reasoning、code reasoning为抓手,因为这些是模态间的common sense。对于通用的VQA任务,他能为模型带来的新知识大概是物体的位置、颜色、形状等信息,而这些信息是需要置身于”情境内“的,或者说没有图片情况下text-only就是在随机猜测,这样新知识的引入对于text-only benchmark是意义不太大的。而在VQA任务中,学会的数字理解和计算法则等是无需在情境内进行交互的,只要模态对齐的好,就能够复用。
NVLM在多模态预训练阶段让模型在math reasoning中从图像中学习识别数字和计算法则进行推理,而SFT阶段让模型NVLM引入了高质量的math数据,让模型从文本中学习识别数字和计算法则进行推理,为了让两个模态都能做好,自然需要寻找到一个对齐的特征空间,这个空间包含了图像模态学来的数学知识和文本模态的数学知识,图像模态学来的数学知识相当于一个补充,丰富了数学能力,这也和math的性能提高是最大的相呼应。