从O1模型聊聊低延迟LLM推理加速器的设计
从O1模型聊聊低延迟LLM推理加速器的设计
青稞作者:知返
原文:https://zhuanlan.zhihu.com/p/764498716
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
在今年年初写的一篇文章里面,我曾经分析过当时大热的Groq LPU 加速器的LLM推理性能,现在看来里面分析的方法论稍微有些稚嫩,不过大体结论都还是对的。
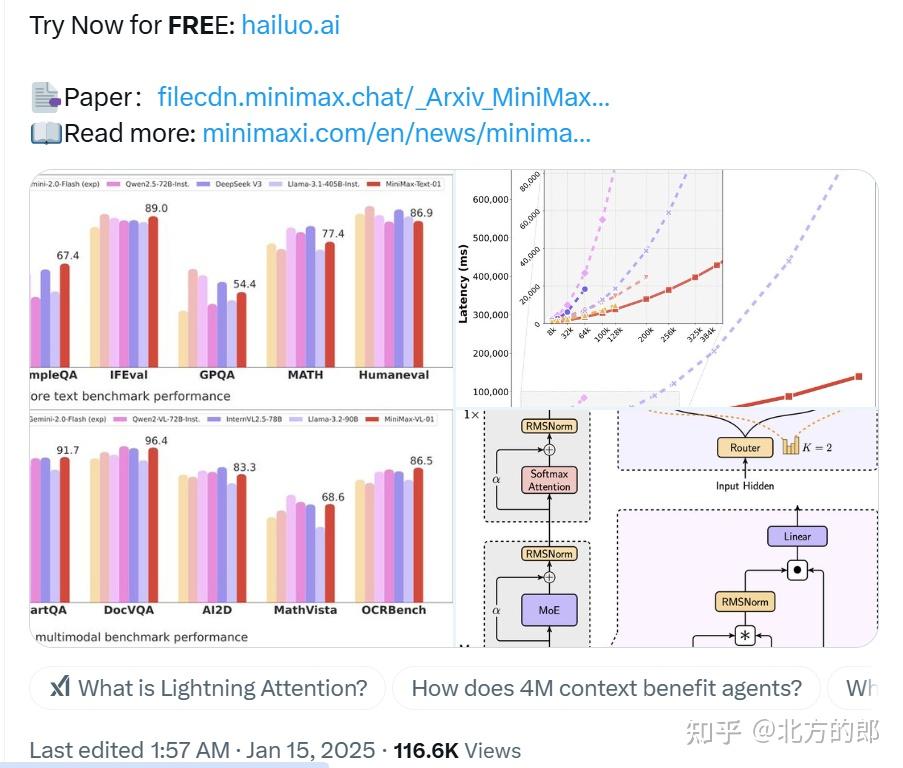
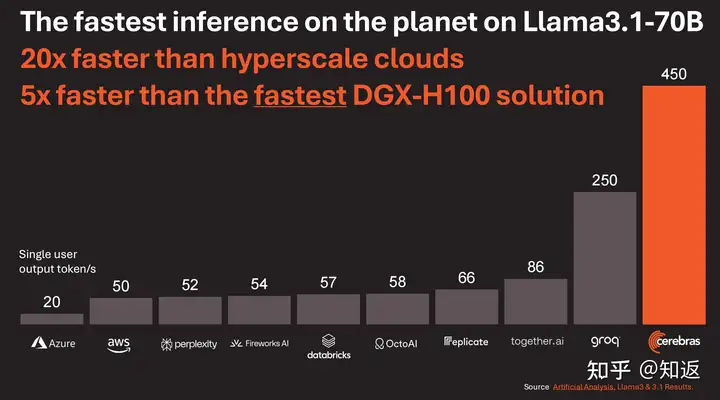
如果你还不了解Groq当时搞了什么大新闻,可以再回顾一下下面这张图。在LLAMA2 70B模型下,Groq LPU以接近200Token/s 的单用户推理性能冠绝群雄。注意,这是单用户的吞吐,而不是整个系统通过组大Batch打满算力带宽得到的吞吐。可以换算一下每token的延迟(TBT)可以打到5ms左右。作为对比,通常GPU推理实例能达到的TBT一般在15-50ms。
在文章的结尾我做了几个预测与分析,一方面是当时看来,低延迟推理的商业模式还没有没有跑通,低延迟推理意味着什么还是个大大的问号。二是显然LPU的分布式SRAM卡+确定性互联和调度的方案只能算是“青春版”解法,这个赛道上一定会有晶圆级大SRAM加速器玩家给出自己的DEMO。

果不其然,在上个月刚结束的Hotchips 上,晶圆级AI加速器玩家Cerebras也公布了其WSE3加速器以及LLAMA3.1 70B 模型的推理性能。其每用户的输出吞吐相对Groq 的方案确实要更进一步,达到了450 Token/s,是H100解决方案的5倍多!
Groq和Cerebras 这两兄弟通过SRAM+数据流的方式登上了LLM低延迟推理性能之巅,一览众山小。然而,大家似乎仍然很难回答那个棘手的问题,也就是 超低延迟的LLM推理到底意味着什么?
业界普遍认为50ms 的TBT延迟就已经可以覆盖绝大多数场景了,毕竟一个人和LLM交互时,主要影响体验的还是首Token延迟,也就是TTFT,这决定了我需要等待多久能得到LLM的回复。而50ms的TBT已经可以一分钟生成1200个词(假设1Token=1词),这已经超出了人类阅读的平均速度(200-500词)。这么看,超低延迟的LLM推理是否是屠龙之术?
我认为上个月发布的OpenAI O1模型可能是屠龙勇士苦苦寻找的那条龙。
虽然O1模型的具体技术细节目前没有被官方公开,但是已经被大家猜的七七八八了。知乎上关于O1的推理过程介绍也很多,这里贴一个我感觉比较靠谱的讲解:OpenAI o1 self-play RL 技术路线推演
O1模型的核心技术是内在的思维链(CoT)。简单说,O1在回答一个问题的时候,会自动对问题进行多步分解,一步一步地写出问题的思考过程,甚至在思考错误时会进行反思和修正。而“思考”的过程就是在做一长串的Decode。在上面这个帖子里面贴了一个官方展示的完整样例,有兴趣可以点进去看看。在那个例子里面,O1模型思考了43秒后进行了问题的输出,并且思考过程用了2930个Token(算一下是每Token 15ms,66 Token每秒)。
这是个很有意思的范式转变。对于普通模型来说,单用户请求的处理时延是 \(TTFT+N\times TBT\) ,其中 \(N\) 表示输出的token数。而对于O1这种可以模拟人类思考的模型来说, 端到端的时延变成了 \(TTFT + M \times TBT + N\times TBT\) ,其中 \(M\) 表示内在CoT消耗的Token数。也就是说,用户等待输出的时长增加了 \(M\times TBT\) 这么多。
原先我们认为TTFT(也就是Prefill阶段处理Prompt的时间)是一个比较影响用户体验的指标,所以才有了各种Context Cache 之类的“以存代算”优化,以及序列并行压低TTFT的各种操作。但是对于传统GPU实例上20ms的TBT性能,进行一个4000 Token的CoT 需要的时间是 80秒,这是显著高于Prompt阶段的TTFT时间的(不是超长序列的话一般小于10秒)。O1式的推理把请求响应的主要瓶颈从Prefill阶段转移到了Decode阶段。
想睡觉来枕头是不?用上Groq或者WSE,就可以把O1的推理延迟提升个5倍甚至更多,原来等一分钟的请求现在花不了10秒,是不是很合理?
事情如果分析到这里为止的话其实还没有那么有意思。我们不妨再深入思考一下,如果想用GPU也实现超低延迟LLM推理来加速O1,到底能不能搞?
事情如果分析到这里为止的话其实还没有那么有意思。我们不妨再深入思考一下,如果想用GPU也实现超低延迟LLM推理来加速O1,到底能不能搞?
假设我希望在GPU上把TBT加速10倍,对于20ms TBT来说,10倍的提速即LLAMA 70B的每TBT要达到2ms。LLAMA 70B 有 80层,粗算一下每层的处理延迟要达到 2000/80 = 25μs。
因为Decode阶段主要卡访存带宽,我们可以算一下为了实现2ms的端到端延迟,需要至少提供多大的内存带宽。假设权重用Int8 进行量化,模型权重是70GB。考虑32K 的上下文长度,KV-Cache 为 \(128 (Head Size)\times 8(KVHeads) \times 2 \times 80(Layers) \times 32768 (Tokens) \times 2(Byte)= 10.7GB\) ,那么解码过程中FFN层+Attention层至少需要的内存带宽为 $ (70+10.7)/(2e-3)=40350GB/s$ 也就是大概40TB/s。按H100的3TB/s HBM带宽算,需要至少14张卡,取个整算16张H100吧,好像也不多是不是?
我们再看另一个维度,为了将模型切分到16张H100上并且发挥出HBM带宽,需要采用Tensor Parallel 和Sequence Parallel (按FA方式切分)并行。通过TP切分,MLP层+Attention层需要4次集合通信(2AG+2RS),Attention 层按FA方式进行序列并行计算,RingAttention也需要进行多次P2P通信。这里先不考虑SP,只考虑TP的情况,即每层至少使用4次集合通信来进行多卡数据同步。为了达到25μs的延迟,即使认为计算和通信完全掩盖,每次集合通信的时间最多为25/4 = 6.25μs。
然而,目前GPU上的集合通信性能并不能满足要求。这里贴几个论文上的数据:8卡基于NVLINK的集合通信延迟在60μs左右。
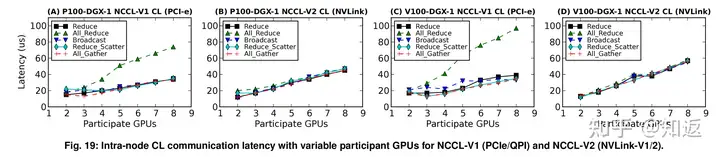
即使只测P2P的延迟,也在10μs以上的量级。而且可以发现,只有当传输的数据量大到一定的程度,(比如,2^18Byte)延迟才真正开始上升。说明在小数据量传输下,并非卡在数据包真正在链路上传输的时间上。当然,这篇论文benchmark的平台有点老,只测到V100。如果有A100或者H100的数据也欢迎网友们贴出来。不过即使是新平台,集合通信操作一次在10μs以上是大概率的。
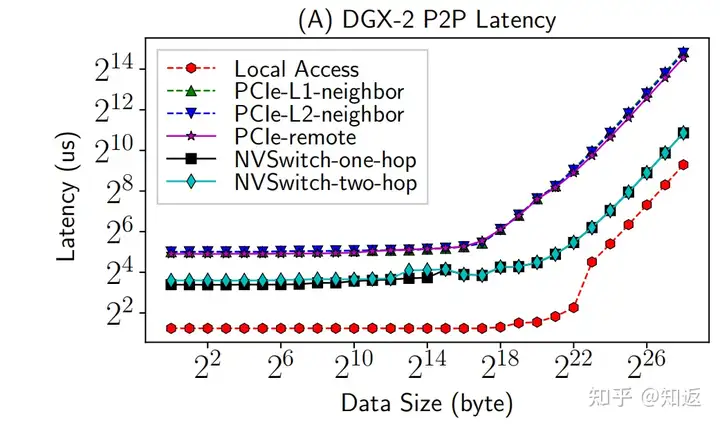
考虑到TP在Decode阶段每次传输的数据量是 \(HiddenSize \times BatchSize\) ,即使是按BS=10算,每次P2P的传输量是8129x10x2 = 0.16MB,卡间按450GB/s的带宽算,满带宽下链路上进行传输的P2P延迟只是0.35μs,考虑链路本身的延迟(没记错的话NVLINK应该是600ns左右?),数据在链路上传输本身的延迟小于1μs。如果为了压低延迟按BS=1进行设置,链路传输延迟完全可以忽略。
合理推测,Kernel Launch和卡间同步的开销是大头。
当然,Kernel Launch的时间也有技术可以优化,比如通过算子融合或者算子图下发的方式进行优化。卡间通信的同步可能是比较难处理的问题。这里涉及前同步和后同步。前同步需要确保对方的数据准备完毕,可以进行传输,后同步需要通过Barrier确保传输完成。特别是当卡变多了还容易存在快慢卡问题,需要等最慢的卡结束操作。本人对这块研究并不深入,暂且抛砖引玉一下。
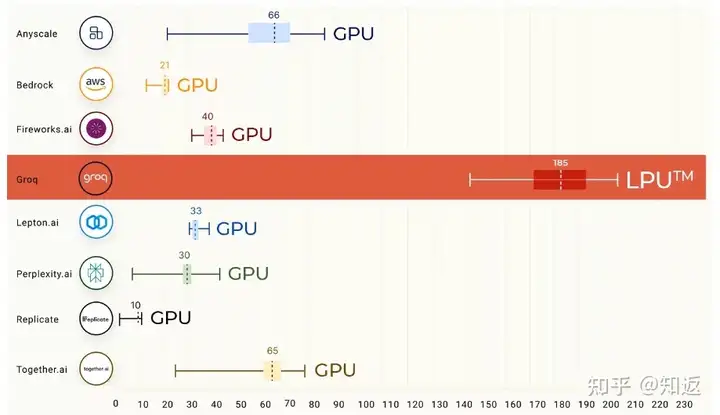
总之,目前基于GPU架构进行分布式推理,其实很难实现Strong Scaling。Cerebras的PPT里面也狠狠地对比了一把。当GPU进行多卡TP并行,内存带宽利用率严重降低,因为都卡在通信(延迟)上了。
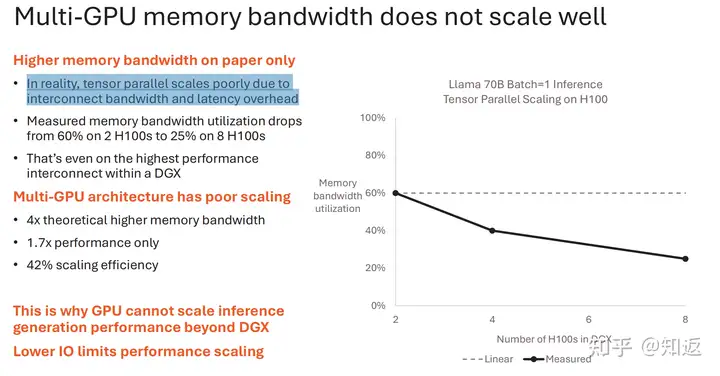
不过GPU本身就是瞄着吞吐进行的架构设计。CUDA的SIMT编程模型和GPU黑盒调度方式并不能让程序员进行细粒度的控制计算通信指令的执行,所以很难像Groq这种基于确定性调度的架构一样进行挤Bubble 优化延迟,也很难像WSE这种Dataflow 架构一样可以通过在小核上编排算子图进行细粒度的调度优化。这么看的话,超低延迟推理,确实是GPU的软肋。
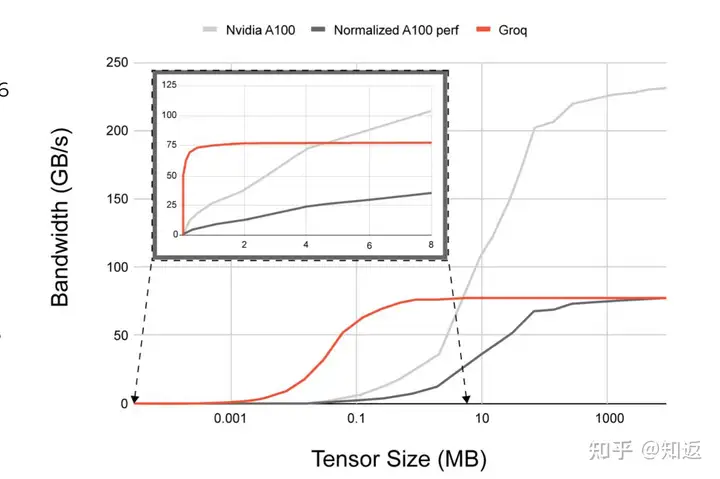
我一直有个观点,提升Bandwidth往往是靠的是Serdes、封装等底层工艺的进步,而降低Latency才是可以从体系结构的角度玩花活的地方,所以AI加速器也许从低延迟推理的角度努力才是正道?毕竟拼吞吐肯定很难体现自己的独特价值呀。
难道GPU就没有对策?
悲观地看,由于目前整个AI算法的生态圈其实都是基于老黄的硬件孕育出来的,如果某个算法在NV的GPU上跑的不够好,更可能的事情是这个算法本身会进行改进,而不是逼老黄出一个新硬件,或是将整个生态迁移到第三方的新硬件上来解决问题。
比如说传统的基于MHA的Attention算子过于卡访存带宽,从而导致了后面GQA 到MLA等提计算访存比的算法出现。Speculative Decoding ,FlashAttention等算法也是尽量地去提升计算访存比,让LLM算法在老黄的GPU上面跑的不那么尴尬。或许未来的O2、O3模型搞了更合理的算法来提升并行度,降低CoT的延迟呢?(比如并行推理多条短链,Best-of-N, 而不是在一条长链上通过增量Decoding修修改改)我觉得站在目前的时间节点看,算法朝着Hardware-efficient的方向继续演进是大概率的事情。所以如果硬件只是追着当代的算法做总是容易陷入局部最优,毕竟芯片从设计到流片周期实在是太长了,等芯片出来,算法都在老黄的硬件上迭代N版了。但是这并不妨碍做硬件的同学思考如何弯道超车是不是?万一有一天算法真的收敛到一个全局最优解了,而这个解不是落在GPU的甜点区,那就赚大了不是?

注:以上内容皆为纸上谈兵