K-Sort Arena:探索高效竞技场算法,根据人类偏好快速评估视觉生成模型
K-Sort Arena:探索高效竞技场算法,根据人类偏好快速评估视觉生成模型
青稞视觉生成模型的快速发展需要高效可靠的评估方法。Arena 平台收集用户对模型比较的投票,可以根据人类偏好对模型进行排名。
然而,传统的 Arena 需要进行过多的投票才能收敛排名,并且容易受到投票中偏好噪声的影响。
为此,来自自动化所和伯克利的研究团队提出K-Sort Arena,采用 K-wise 比较,允许 K 个模型参与自由混战,提供比成对比较更丰富的信息,并设计基于探索-利用的匹配算法和概率建模,从而实现更高效和更可靠的模型排名。

K-Sort Arena已经历数个月的内测,期间收到来自Berkeley, NUS, CMU, Stanford, Princeton, 北大, Collov Labs, 美团等数十家机构的专业人员的技术反馈。目前,K-Sort Arena 已收集几千次高质量投票并有效地构建了全面的模型排行榜,已用于评估几十种最先进的视觉生成模型,包括文生图和文生视频模型。
研究背景
在生成任务中,传统指标难以反映人类的偏好,无法提供公正而全面的评价。为此, Chatbot Arena构建LLMs的模型竞技场,并根据用户投票反馈建立模型排行榜,已成为评估LLMs的权威工具之一。然而,传统Arena的成对对比方式、模型匹配策略以及模型能力建模方法使其在效率和可靠性上面临挑战,这会潜在地浪费宝贵的人工投票资源,并影响对新模型能力的快速评估和排行榜的及时更新。
方法解析
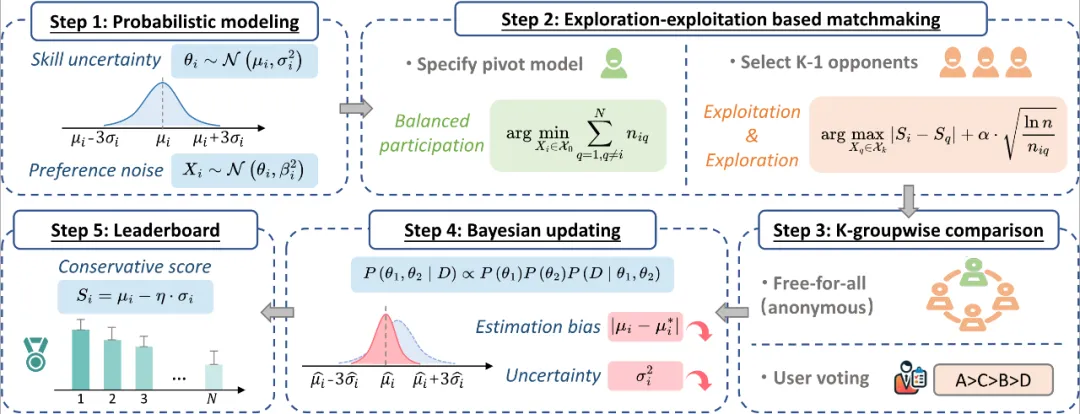
针对上述背景,研究者提出了K-Sort Arena来提升排行榜的效率和可靠性,如下图所示。

K-wise对比:K-Sort Arena 同时评估 K 个模型(K>2),这自然比成对比较提供了更多信息,从而提高了整体排序的效率。这种方法基于一个实用的生物学原理:图像和视频比文本具有更高的感知直观性,可以在类似的时间内一次快速评估多个样本。
概率建模: 通过使用概率分布来表示能力,可以捕获和量化固有的不确定性,从而比单个数值建模(如 ELO)具有更强的灵活性和适应性。研究者把每个模型的能力建模为 \(θ_i∼N(μ_i,σ_i^2 )\) ,并通过增加额外的随机性来模拟偏好噪声,即模型真实表现为 \(X_i∼N(θ_i,β_i^2 )\) 。在收集每一轮投票后,将胜负结果作为观测,通过贝叶斯定理 \(P(θ_1,θ_2∣D)∝P(θ_1 )P(θ_2 )P(D∣θ_1,θ_2 )\) 更新模型能力的后验概率。
模型匹配: 传统Arena采用ELO机制的完全随机匹配,这可能会导致排名最低的玩家与排名最高的玩家配对,从而提供极少的信息量。为此,研究者提出了一种基于探索-利用的匹配策略。将玩家的选择建模为多臂老虎机问题,其中每对玩家被视为一个臂,目标是在 n 次比较后为整体排名提供最多的信息。多臂老虎机问题通过上置信边界 (UCB) 算法求解,在当前利用的情况下以最乐观的态度进行探索,其公式如下: \(U^((n)) (X_i,X_q )=|S_i^((n))-S_q^((n)) |+α⋅√(lnn/n_iq )\)
排行榜


实验结果
- K-Sort vs. ELO-based Arena
下表显示了 ELO 系统和 K-Sort Arena 达到收敛(即 MSE 始终为零)所需的比较次数,K-Sort Arena 的效率是 ELO 系统的 16.3 倍,大大减少了所需的用户投票数。

- Probabilistic vs. Numerical Modeling
首先验证概率建模相对于 ELO 系统中采用的数值建模的优势,如下图所示。数值建模表现出剧烈的振荡,即使经过 3000 次比较也无法收敛。这一结果凸显了现有 Arena 平台的不可靠性,尽管已经收集了大量投票。相反,在有噪声和无噪声的情况下,概率建模都可在大约 1500 次比较后提供了快速收敛。


- K-wise vs. Pairwise Comparison
下图验证不同K值(2,4,6)对排序收敛的影响。当 K 增加到 4 时,每轮多个模型进行自由比较,这比 K=2 的情况产生更丰富的信息,从而实现更快的收敛速度(大约快两倍)。

- UCB vs. Traditional Matchmaking
UCB 匹配策略的优势如下图所示。由于随机匹配可能会导致低信息量比较,因此在 3,000 次比较后仍会继续震荡。基于技能的匹配(TrueSkill)的目标是比较中的玩家技能尽可能相等,这可能会促进单个玩家进行有趣的比赛,但它忽略了探索,因此无法确保从全局角度来看整体排名的收敛和稳定性。UCB 匹配策略通过平衡开发和探索解决了这个问题,以最少的比较实现了排名收敛。

- Specified vs. Random Pivot
在现有排名中添加新模型的情况如下图所示。当采用提出的平衡引导规范方法时,由于新模型参与的比较次数最少,它总是在初始阶段被选为Pivot,最终仅需大约 30 次比较即可在50个模型中确定新模型的排名。