青稞Talk 30期预告!OminiParser:基于纯视觉的 GUI Agent

青稞Talk 30期预告!OminiParser:基于纯视觉的 GUI Agent
青稞近年来,大型视觉-语言模型(VLMs)的发展(如GPT-4V和GPT-4o)在推动能够在用户界面(UI)中运行的智能代理系统方面展现出了巨大潜力。然而,这些多模态模型在现实应用中的全部潜力仍未得到充分挖掘,尤其是在仅依赖视觉输入,作为通用代理跨越多种操作系统和应用程序执行任务时。一项主要的限制因素是缺乏一种强大的屏幕解析技术,该技术需要能够:
- 1)可靠地识别用户界面中的可交互图标;
- 2)理解截图中各元素的语义,并能将目标操作准确地与屏幕上的对应区域关联起来。
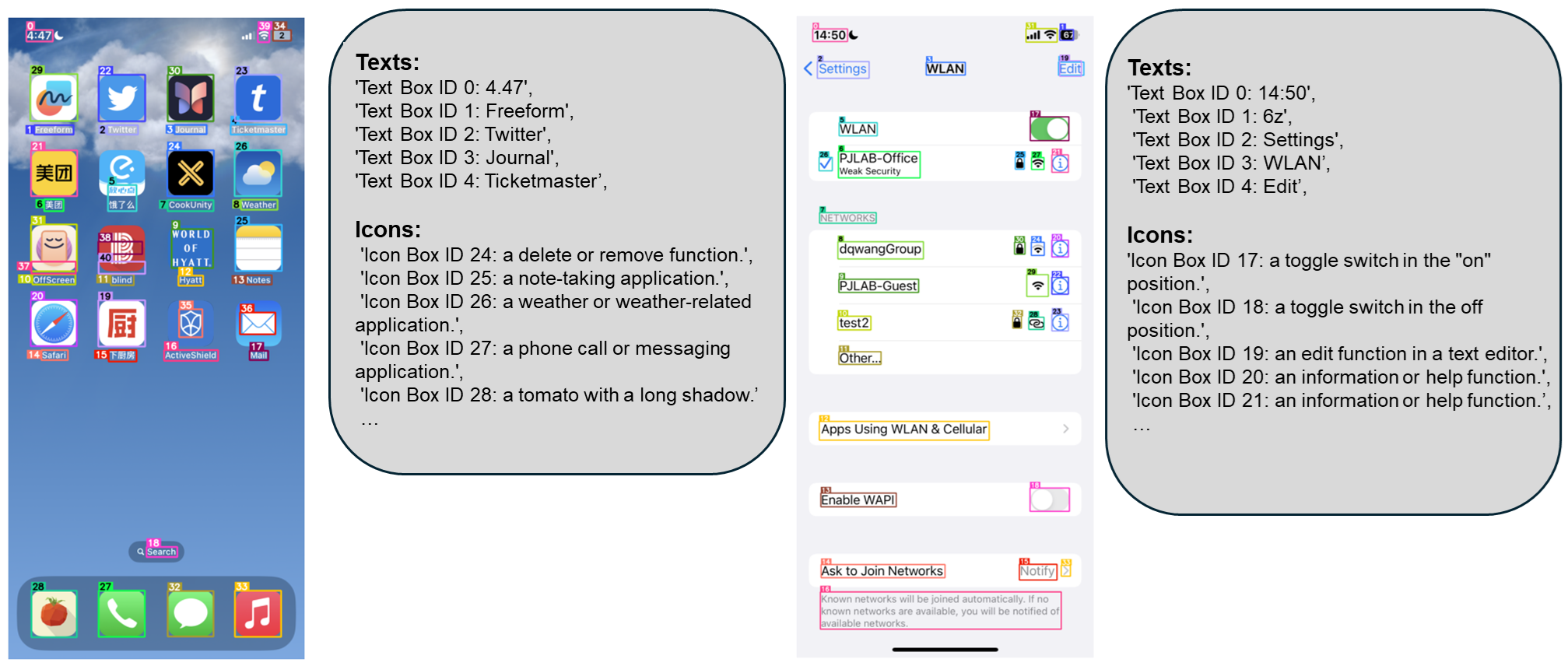
为此,微软研究院的研究员们开源了 OmniParser,一个紧凑的屏幕解析模块,能够将用户界面截图转化为大语言模型可以看懂的“结构化元素”。比如识别屏幕上所有可交互的图标和按钮,并用框框标出来,给每个框框一个独一无二的ID;用文字描述每个图标的功能,比如“设置”、“最小化”。识别屏幕上的文字,并提取出来等等。
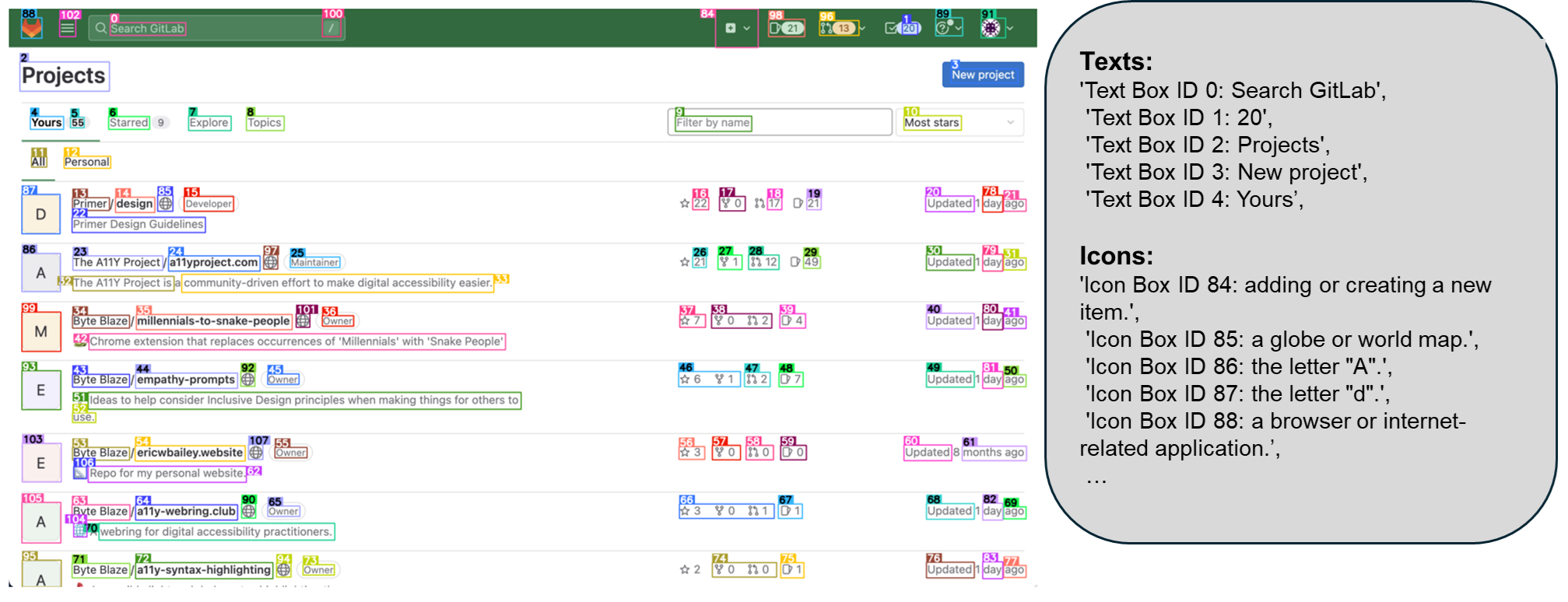
OmniParser 可以与多种模型配合使用,以创建能够在用户界面上执行操作的智能代理,比如 Phi-3.5-V、Llama-3.2-V 等。OmniParser 可以作为一种通用且易于使用的工具,能够在 PC 和移动平台上解析一般用户屏幕,而无需依赖 Android 中的 HTML 和视图层次结构等额外信息。

11月30日上午11点,微软研究院 AI Frontiers 实验室高级研究员鲁亚东,将直播分享《OminiParser:基于纯视觉的 GUI Agent》。
主讲嘉宾
鲁亚东,微软研究院 AI Frontiers 实验室高级研究员。研究兴趣主要集中在大型视觉语言模型上,专注于构建能够在图形用户界面上完成任务的多模态代理;在加入微软之前,于 2021 年获得加州大学欧文分校博士学位。
主题提纲
OminiParser:基于纯视觉的 GUI Agent
1、VLMs 的研究及 GUI Agent 的应用难点
2、OminiParser:将屏幕 UI
解析为结构化文件
3、OmniParser 增强下的 GPT-4V 操作能力提升
4、与open source VLM的结合应用实践
成果链接
- Paper:OmniParser for Pure Vision Based GUI Agent
- Abs:https://arxiv.org/pdf/2408.00203
- Code:https://github.com/microsoft/OmniParser
- hugging face demo:https://huggingface.co/spaces/microsoft/OmniParser
直播时间
11月30日上午11点
参与方式
Talk 将在青稞·知识社区上进行,扫码对暗号:" 1130 ",报名进群!