多模态视觉token压缩方法
多模态视觉token压缩方法
青稞作者:葡萄是猫
原文:https://zhuanlan.zhihu.com/p/8776092026
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
简要
为提升MLLM对图像、视频的理解能力,最有效的方式就是提升visual token的个数,随之而来的则是训练、推理耗时的增加。因此,对视觉token进行压缩以提取最有用的信息至关重要。下文基于个人理解,进行梳理。
已知技术方案概览:
- 1.线性映射:采用多层MLP进行压缩,如Qwen2-VL中
- 2.下采样:采用Pooling(可以是不同的pool采样方式),如LLaVA-OneVision
- 3.Pixel-Shuffle:用通道换空间,如InternVL1.1及后续系列
- 4.Q-former:新增learned query实现视觉token压缩,如Flamingo、BLIP2
- 5.模型动态压缩:利用模型指导视觉token采样,如FocusLLaVA、MustDrop
- 6.注意力改造:改造注意力机制,不直接压缩token,但仍能达到提升推理速度的目的,如mPlug-owl3
其中,线性映射、下采样方法较易理解,不展开赘述
Pixel-Shuffle
该方案是用通道换空间,即减少空间增加通道,数据维度变化:[N, W, H, C] -> [N, Ws, Hs, C//(s^2)](当s>1时,则实现上采样;当s<1时,则实现下采样)
在InternVL1.1,利用此方案,将视觉token从1024压缩到256个(分辨率448x448,patch_size 14,s=0.5),代码片段:
1 | def pixel_shuffle(self, x, scale_factor=0.5): |
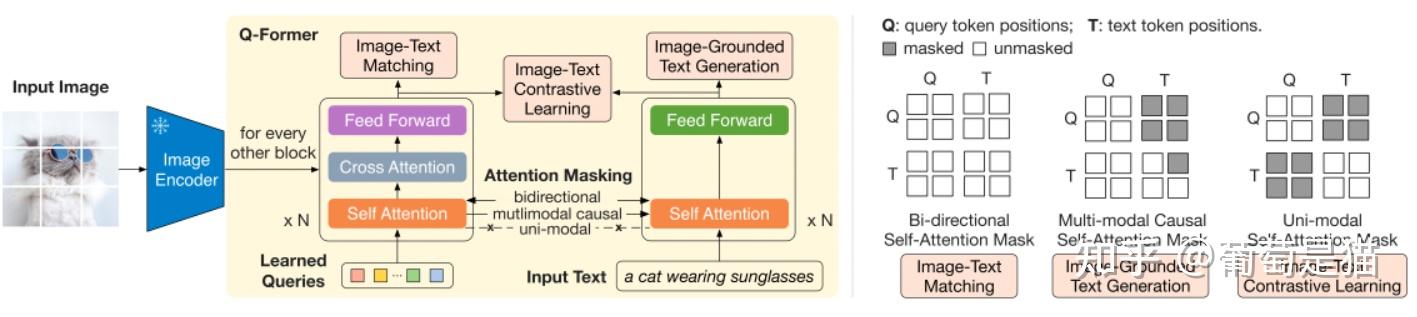
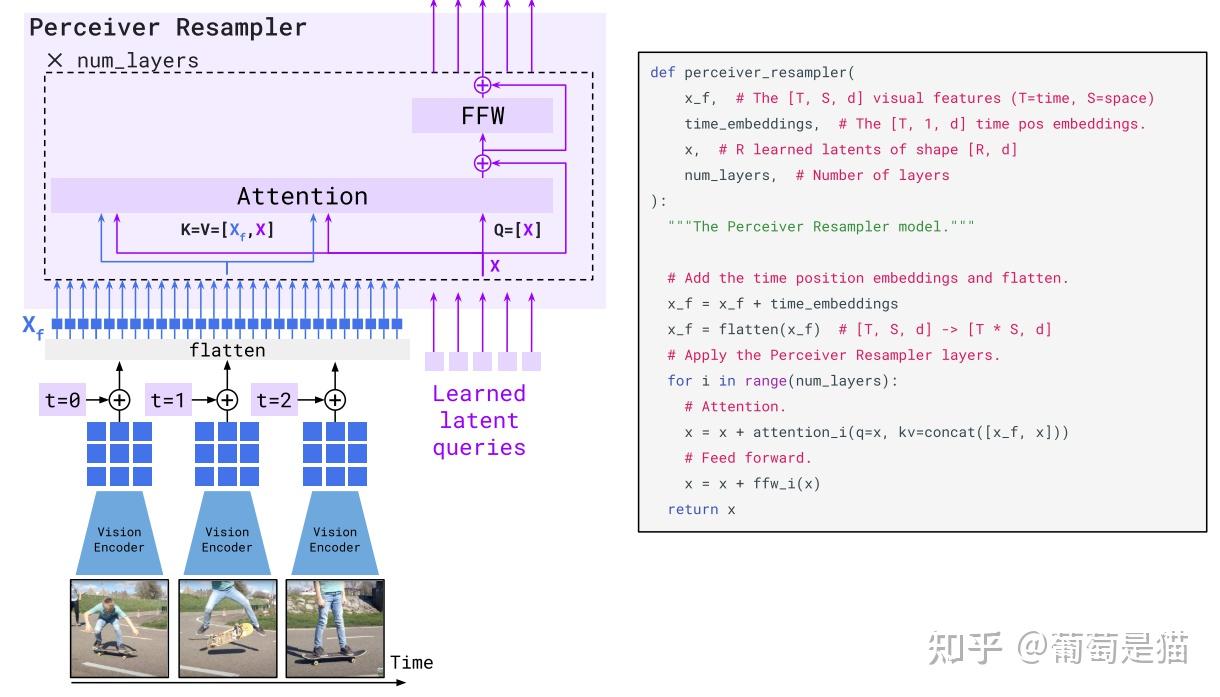
# Q-Former
该类方案是引入可学习的embedding(learned query),和视觉token计算注意力,以实现token压缩。最早在Flamingo中是Perceiver Resampler,BLIP2中是Q-Former(注意,在视觉token和文本交互时,blip2更简化直接拼接视觉token和文本token,而flamingo中采用了gated xattn-dense)
模型动态压缩
该方案也是通过改造模型,让模型在端到端训练中,自适应抉择最重要的token,实现视觉token的动态压缩。
FocusLLaVA
1 | Paper:FocusLLaVA: A Coarse-to-Fine Approach for Efficient and Effective Visual Token Compression |
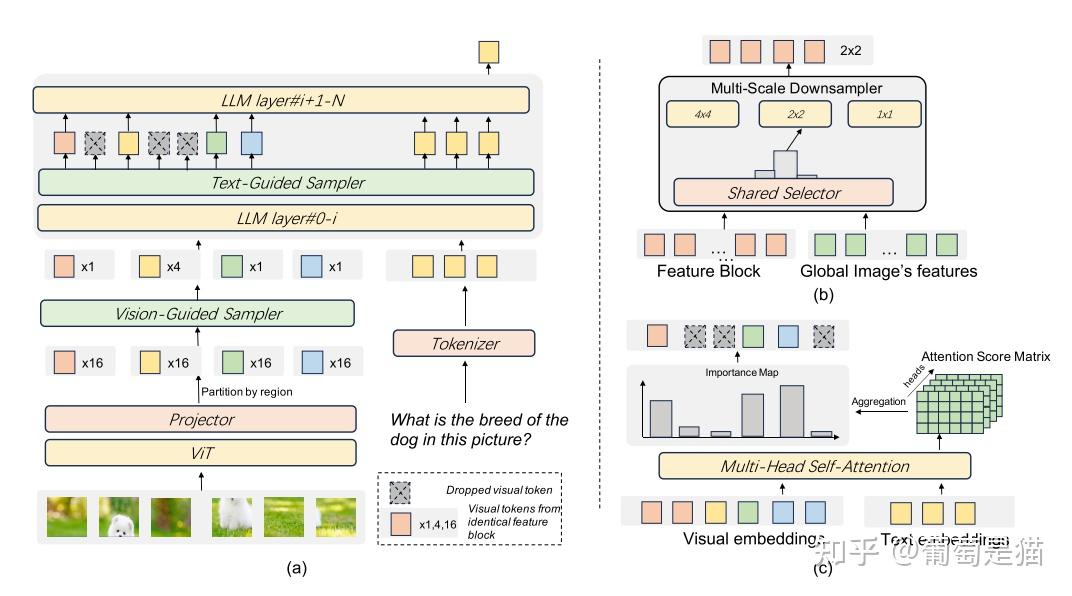
方案:提出vision-guided sampler(下图b)实现视觉token压缩(LLM中也提出了text-guided samper,下图c),其中vision-guided sampler分成两步: - 1.多尺度降采样:将vit后的全局feature map X再按window切分,对切分后的子特征图按照不同的max-pool(如4x4,2x2,1x1,类似SPP操作)得到出一组token集合 - 2.多尺度选择:引入MoE思想,将不同尺寸的降采样当做专家模型,对上一步的token集合拉平后计算其和vit后的全局feature map X计算相似度,并保留top的token,即实现token压缩
MustDrop
1 | Paper:Multi-Stage Vision Token Dropping: Towards Efficient Multimodal Large Language Model |
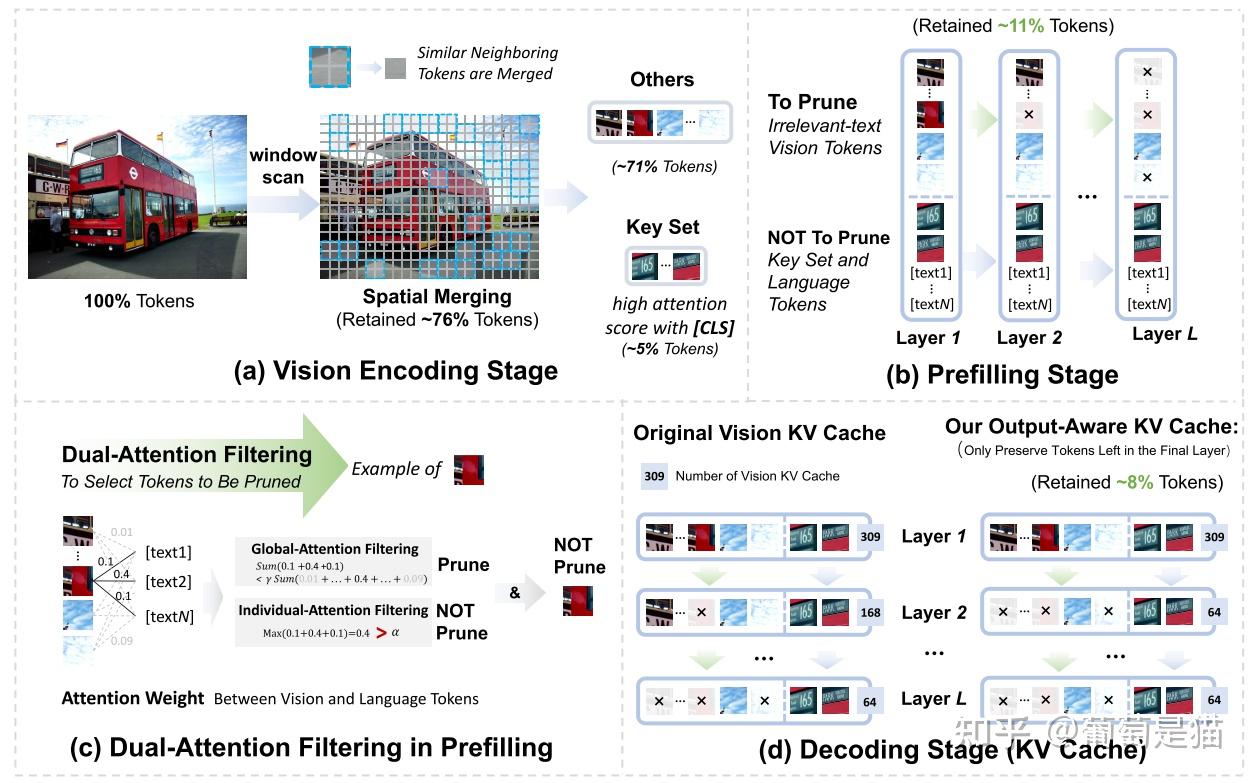
方案:该方案侧重在推理时对token进行压缩,在MLLM推理的各个阶段提出相应的压缩方案 - 1.Visual-encode stage:计算相邻token的相似度 - 2.Prefill stage:dual-attention estimation,先通过global-attention filtering(计算视觉token和所有text token的相似度)过滤出“可能不相关的token集合”,再通过individual-attention filtering(计算视觉token和单个文本token的相似度)过滤出“真正不相关的token集合” - 3.Decode stage:output-aware cache策略,在decode时对模型不同层进行不同尺度的剪枝,最后保留最少的token输出
注意力改造
mPlug-owl3
1 | Paper:mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models |
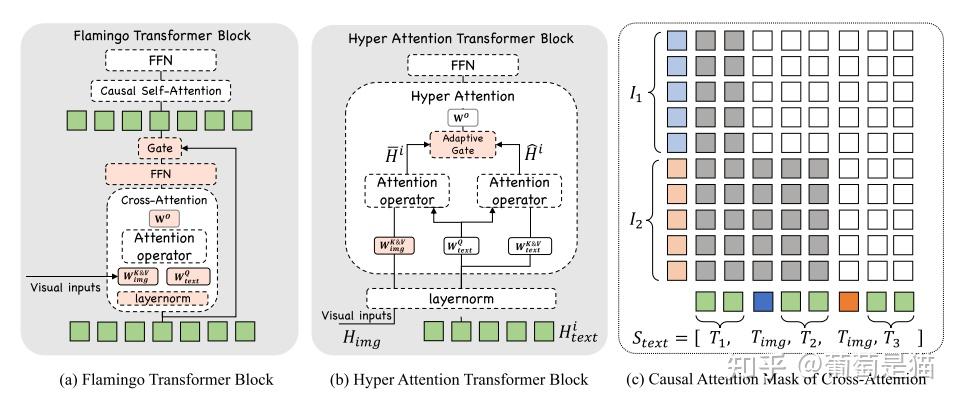
方案:该方案不是直接压缩token,改造注意力机制为HyperAttnTransformer,视觉和文本共享q矩阵,并各自保留k&v矩阵,实现整个模型参数量降低,提升推理速度
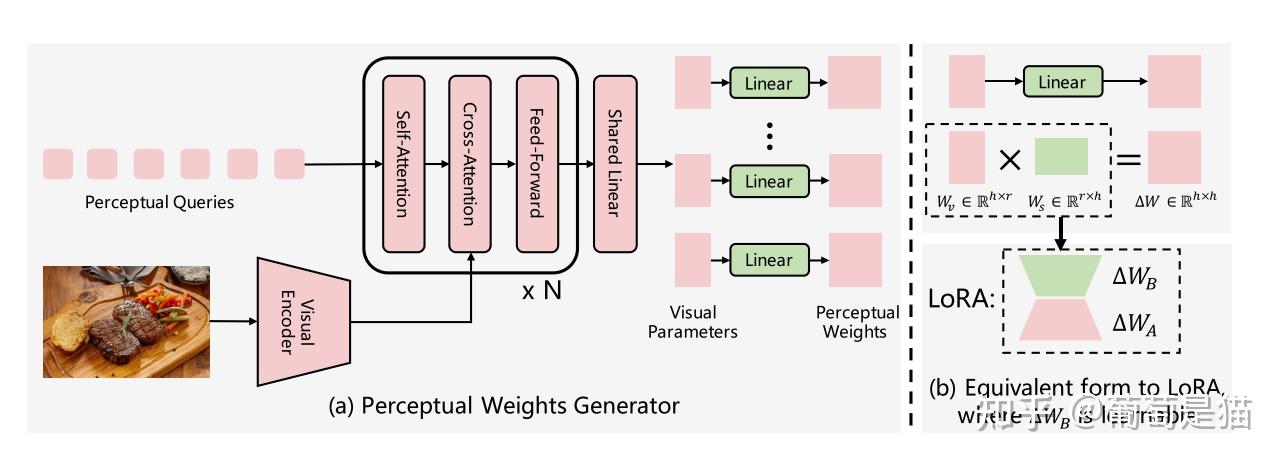
VLoRA
1 | Paper:Visual Perception by Large Language Model's Weights |
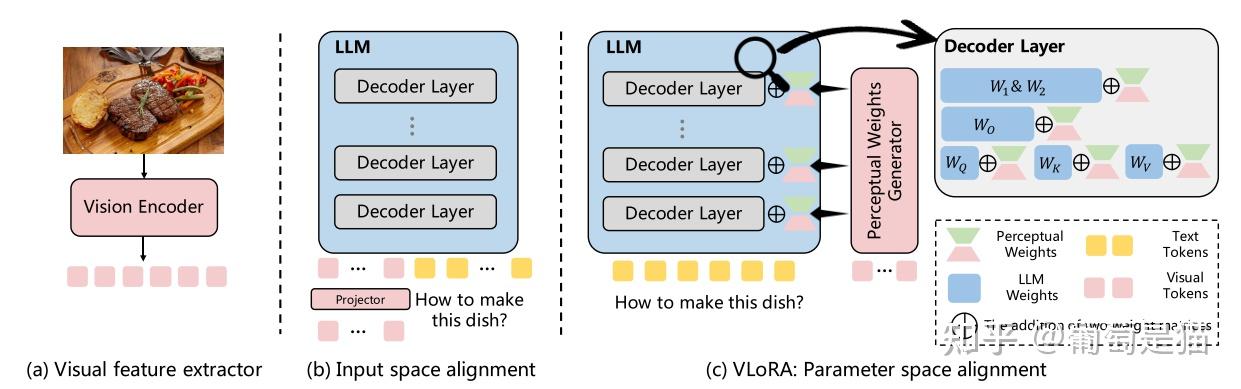
方案:该方案不直接将视觉token输入到LLM中,而是通过类似LoRA的方式将Visual token作为参数权重,引入到LLM中
Training-free
MustDrop
1 | Paper:Multi-Stage Vision Token Dropping: Towards Efficient Multimodal Large Language Model |
方案:该方案侧重在推理时对token进行压缩,在MLLM推理的各个阶段提出相应的压缩方案 - 1.Visual-encode stage:计算相邻token的相似度 - 2.Prefill stage:dual-attention estimation,先通过global-attention filtering(计算视觉token和所有text token的相似度)过滤出“可能不相关的token集合”,再通过individual-attention filtering(计算视觉token和单个文本token的相似度)过滤出“真正不相关的token集合” - 3.Decode stage:output-aware cache策略,在decode时对模型不同层进行不同尺度的剪枝,最后保留最少的token输出
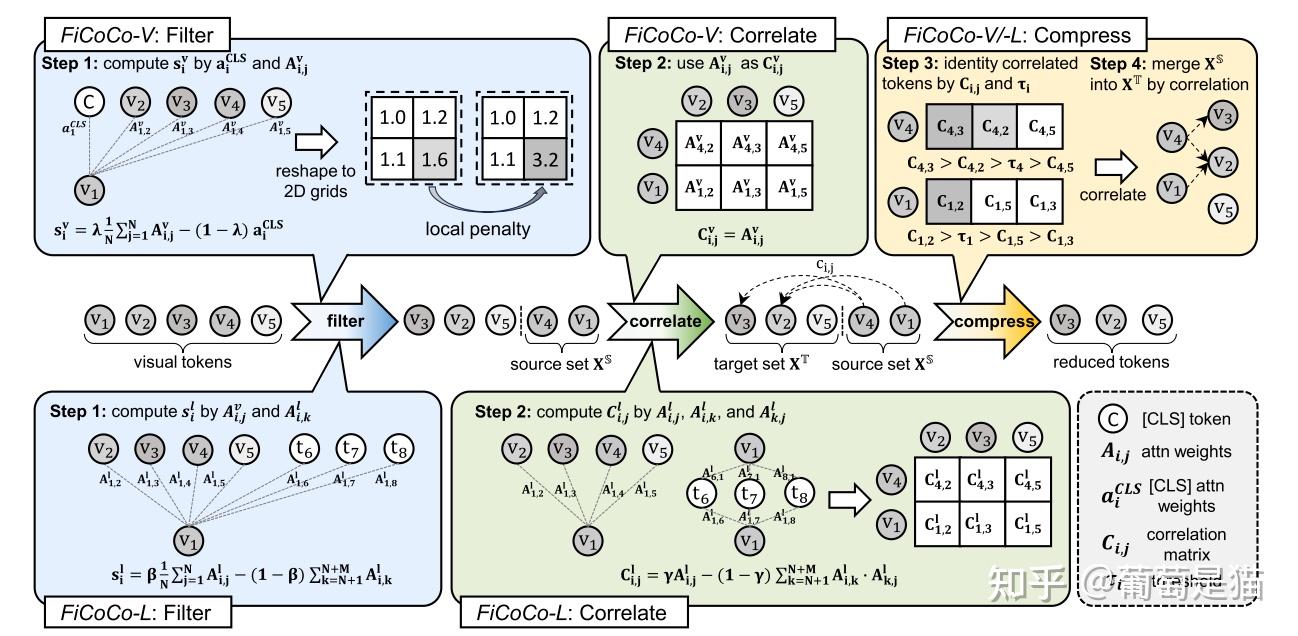
FiCoCO
1 | Paper:Rethinking Token Reduction in MLLMs: Towards a Unified Paradigm for Training-Free Acceleration |
方案:将token的压缩方式分解成Filter-Correlate-Compress三个阶段,实现training-free的token压缩框架,并将该框架分别应用于模型的不同部分,即Visual encode阶段(即FiCoCo-V)、LLM decode阶段(即FiCoCo-L)、visual encode和LLM decode(即FiCoCo-VL),不同部分的实现略有不同。该框架的三个阶段具体情况如下: - 1.filter阶段:解决要丢弃哪些token的问题,通过attention矩阵和cls token计算得到token冗余度,再筛选topK - 2.Correllate阶段:解决被丢弃的信息要保留到哪里的问题,通过计算topK token和剩余token的相关性实现 - 3.Compress阶段:解决如何融合token以保留相关信息的问题,通过相关性计算token-wise的压缩权重实现