浙大开源ZipAR:自回归图像生成开销降低91%

浙大开源ZipAR:自回归图像生成开销降低91%
青稞
1 | 论文地址:https://arxiv.org/pdf/2412.04062 |
问题背景
近年来,大型语言模型(LLMs)在文本生成任务中取得了显著进展,尤其是基于“下一个词预测”(next-token prediction)范式。这一范式不仅在文本生成中表现出色,还被广泛应用于视觉内容的生成,推动了自回归(AR)视觉生成模型的发展。这些模型能够生成高质量的图像和视频,甚至在某些方面超越了最先进的扩散模型。然而,自回归模型在生成高分辨率图像或视频时,需要逐个生成数千个视觉标记,导致生成速度缓慢,成为其广泛应用的主要障碍。
针对大语言模型的解码问题,研究者们已经提出了多种方法来减少生成过程中的前向传递次数。例如,“下一个集合预测”(next-set prediction)范式通过引入多个解码头或小型Draft模型来生成多个候选标记,但这些方法通常需要额外的模型或训练成本。此外,Jacobi解码方法通过迭代更新标记序列来加速生成,但在实际应用中,这类方法的加速效果有限。然而,这些方法都为LLM而设计,没有利用视觉内容的独特特性。专门针对 AR 视觉生成的并行解码框架还有待研究。
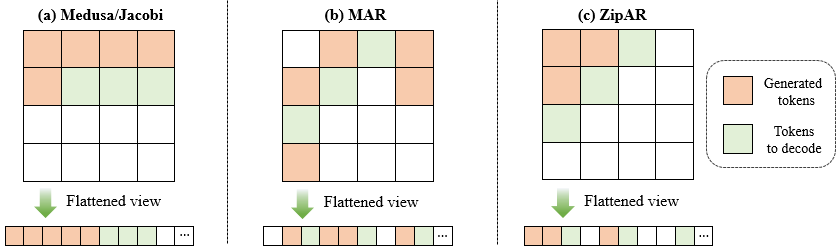
核心创新
在这篇论文中,作者提出了ZipAR,一种无需训练、即插即用的并行解码框架,用于加速自回归视觉生成。ZipAR的核心思想是利用图像的空间局部性,即图像中相邻区域之间的依赖性较强,而空间上较远的区域之间的依赖性较弱。基于这一观察,ZipAR允许在同一前向传递中并行解码多个空间相邻的视觉标记,从而显著减少生成图像所需的前向传递次数。
ZipAR解码过程
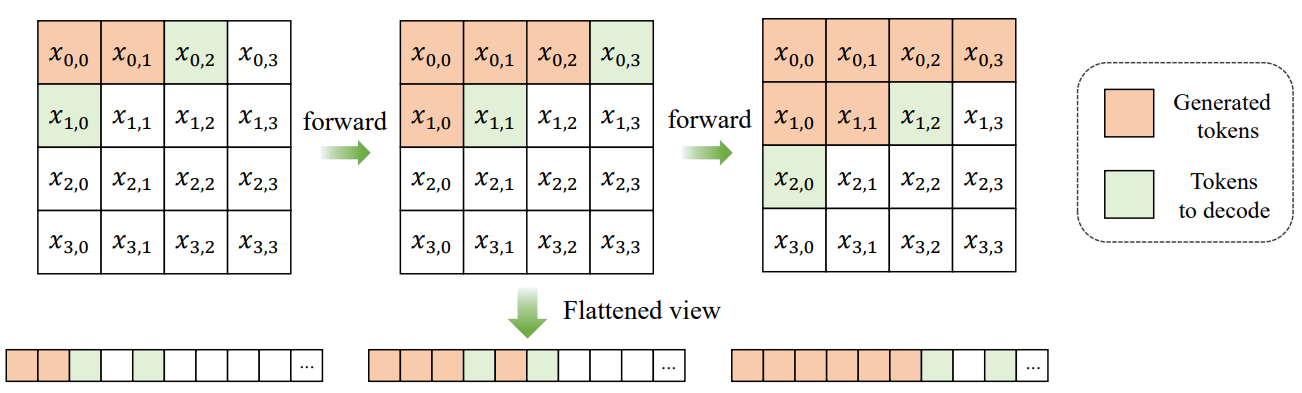
传统的AR视觉生成模型按行顺序逐个生成视觉标记,即每一行的标记必须在前一行完全生成后才能开始生成。然而,图像本身具有强烈的空间局部性,即相邻行之间的标记具有较强的相关性。基于这一观察,ZipAR提出了一种新的解码策略:
1.定义窗口大小:首先,定义一个局部窗口大小 $s $。对于位于行 $ i $ 和列 $ j $ 的标记 $ x_{i,j} \(,假设前一行中位于\) x_{i-1,j+s} $之后的标记对 $ x_{i,j} $的生成影响可以忽略不计。
2.并行解码条件:基于上述假设,当当前行中生成的标记数量超过窗口大小 $s $时,下一行的解码可以并行开始。具体条件如下:
1 | \[ |
其中,$ \(表示已解码的标记集合,\) C(i,j)=1 $表示标记 $ x_{i,j} $ 可以开始生成。
3.并行解码策略:一旦当前行中生成的标记数量超过窗口大小 $s $,下一行的解码就可以并行开始。具体来说,当生成当前行的第一个标记 $ x_{i,0} $ 时,需要前一行最后一个标记 $ x_{i-1,n}$ 作为输入。对于支持动态分辨率的模型,可以通过提前插入行结束标记来解决这一问题;对于不支持动态分辨率的模型,可以通过寻找最邻近的,已经被解码的标记,将其值临时赋给前一行最后一个标记 $x_{i-1,n} $。
实验亮点
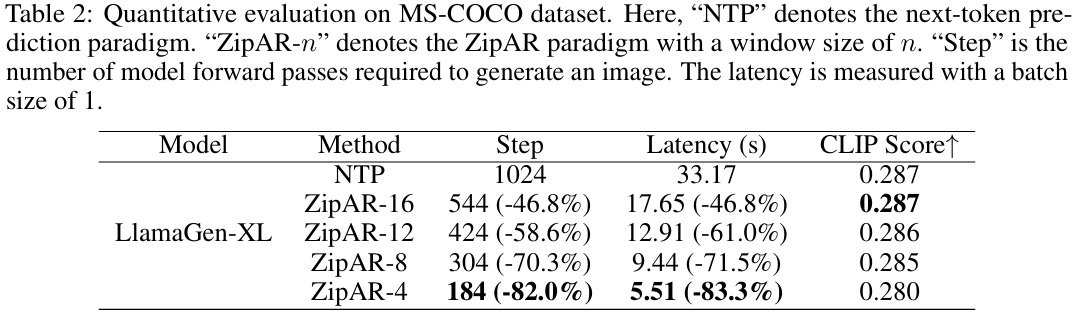
定量结果
在MS-COCO数据集上,使用LlamaGen-XL模型进行文本引导图像生成实验。结果显示,ZipAR-12在CLIP评分仅下降0.001的情况下,推理延迟减少了61.0%。ZipAR-4在前向传递次数减少83.3%的同时,CLIP评分为0.280,保留了良好的语义信息。
定性可视化
在Emu3-Gen、LlamaGen和Lumina-mGPT模型上,ZipAR分别将前向传递次数减少了91%、82%和67%,同时生成的图像仍然保持高保真度和丰富的语义信息。
可视化,第一列为原始模型,右三列为ZipAR加速后的结果。