ICLR 8分论文:模型自身也可以标注偏好数据
ICLR 8分论文:模型自身也可以标注偏好数据
青稞作者:yearn
原文:https://www.zhihu.com/question/588325646/answer/3422090041
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
1 | Paper:Spread Preference Annotation: Direct Preference Judgment for Efficient LLM Alignment |
大语言模型(LLMs)的成功在很大程度上依赖于与人类偏好的对齐。然而,这种对齐通常需要大规模的人工标注偏好数据,成本非常高昂。现有方法如通过外部奖励模型或利用 LLM 的上下文学习能力来模拟偏好标注,但这些方法存在以下问题:
- 需要大规模的人工标注数据,成本高。
- LLM-as-judge 方法依赖模型规模大且预先对齐性良好,应用范围有限。
- 使用外部奖励模型时可能因分布不匹配导致无效,且容易产生标签噪声。
因此,本文提出了一种新的框架,称为 Spread Preference Annotation (SPA),通过直接偏好判断(direct preference judgment)在仅依赖少量人工标注数据的情况下提升 LLM 的对齐性能。
主要贡献
- 1.直接偏好标签生成:通过 LLM 的 logits 显式提取模型的固有偏好,与依赖外部奖励模型或隐式上下文学习的方法相比更高效。
- 2.基于置信度的偏好标签优化:引入一种噪声感知算法,降低由生成偏好数据引入的低质量标签的风险。
- 3.线性外推预测:在当前模型和参考模型之间进行线性外推,模拟更强对齐模型的预测能力,从而更好地识别噪声。
实验表明,SPA 框架在小规模偏好数据的基础上,显著提升了 LLM 的对齐性能,且无需额外的人工标注数据即可实现强大的性能提升。
技术细节
预备知识
1.目标:给定一个输入序列 \(x\)(如提示词),大语言模型(LLM) \(\pi_\theta\)生成输出序列\(y\)(如回复),即 \(y \sim \pi_\theta(\cdot|x)\)。目标是通过偏好学习使 \(\pi_\theta\) 的回复与人类偏好对齐。
2.偏好数据集:假设有一个偏好数据集 \(D = \{(x, y_l, y_w)\}\),包含输入提示$ x$、偏好回复 \(y_w\) 和不偏好回复\(y_l\),这些偏好标签通常由人类专家标注。
3.奖励建模与强化学习微调(RLHF): - 偏好建模通过 Bradley-Terry 模型定义:
\(p(y_w \succ y_l | x) = \frac{\exp(r(x, y_w))}{\exp(r(x, y_w)) + \exp(r(x, y_l))} \\\)
- 奖励函数 \(r_\phi(x, y)\) 参数化后,通过最大似然目标优化: $L_R(r_) = -_{(x, y_w, y_l) D} [(r_(x, y_w) - r_(x, y_l))] \ $其中 \(\sigma\) 是 sigmoid 函数。
- 使用奖励函数$ r_$微调 \(\pi_\theta\),同时加入 KL 正则化避免过拟合:
直接偏好优化(DPO):
- 通过将奖励函数和强化学习微调整合为单一的优化目标,DPO 提供了更简单高效的对齐方法。
- 偏好概率定义为:
\(p_\theta(y_w \succ y_l | x) = \sigma\left(\beta \log \frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)}\right) \\\)
- DPO 的优化目标为:
\(L_{DPO}(\pi_\theta) = \mathbb{E}_{(x, y_w, y_l) \sim D}[-\log p_\theta(y_w \succ y_l | x)] \\\)
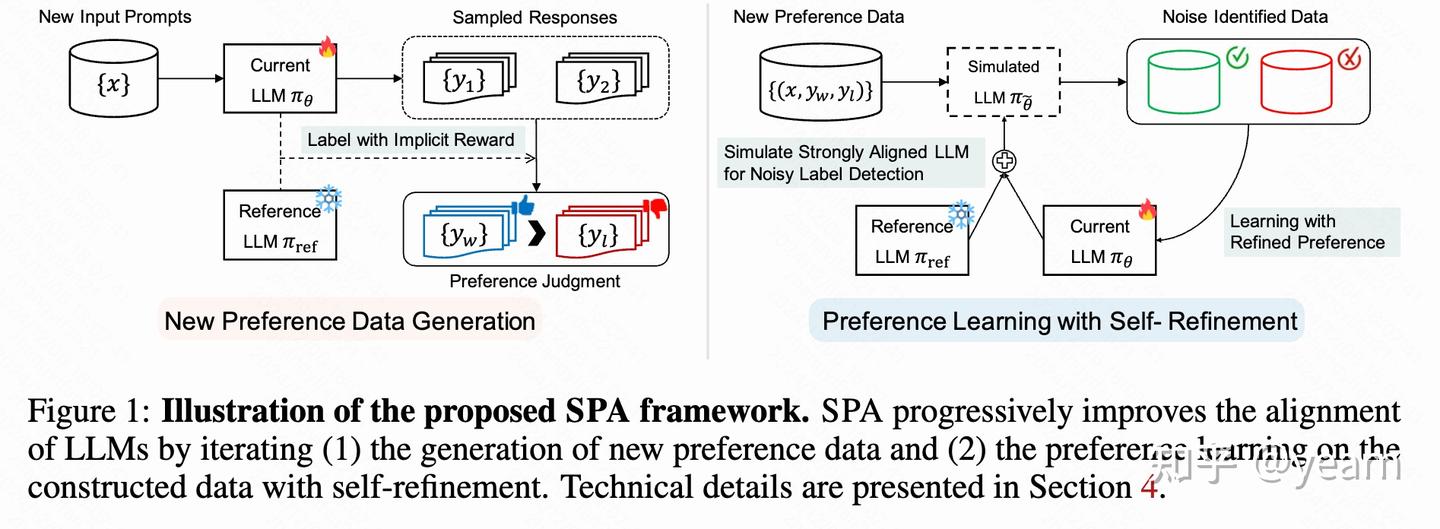
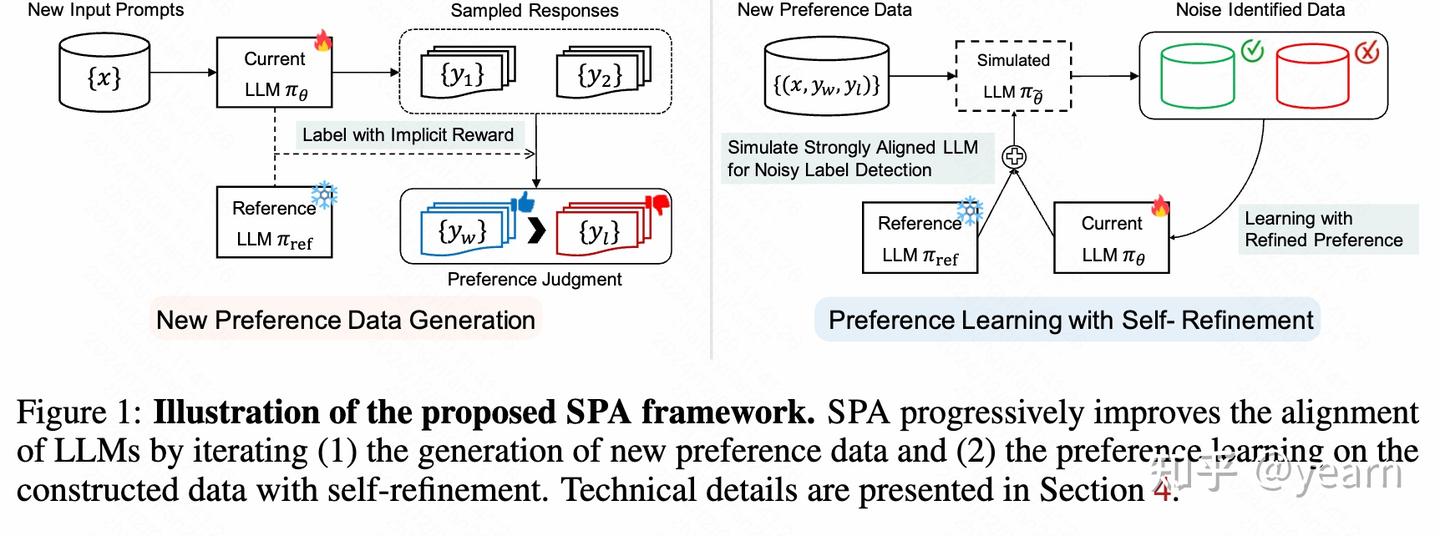
SPA 方法框架
SPA(Spread Preference Annotation)框架通过直接偏好判断和自生成数据扩展的方式,迭代提升 LLM 的对齐性能,同时降低大规模偏好数据标注的成本。
总览
1.初始阶段:
- 给定一个小规模的种子偏好数据集$ D_0 \(和初始模型\) _{init}$(通常为经过监督微调的模型)。
- 使用 DPO 方法在 \(D_0\) 上微调 \(\pi_{init}\),得到初步对齐的模型 \(\pi_0\)。
两步迭代流程: - 数据扩展:利用模型生成新的偏好数据。 - 模型微调:在生成的数据上进行自我优化,同时引入噪声处理机制。
数据扩展:使用自生成偏好数据对齐 LLM
1.新提示生成: - 在第$ i $次迭代中,假设有一组新的提示集合 \(X_i = \{x\}\),这些提示与之前的提示集合不重叠。 - 对于每个提示 \(x \in X_i\),从模型$ {i-1} \(中采样两个回复\) y_1\(,\) y_2\(,即\) y_1, y_2 {i-1}(|x)$。
偏好判断: - 使用模型 \(\pi_{i-1}\) 和初始模型$ _{init} \(的奖励函数计算偏好概率: - 根据偏好概率直接判断偏好标签:\) (y_w, y_l) = \[\begin{cases} (y_1, y_2), & \text{若 } p_{i-1}(y_1 \succ y_2 | x) > 0.5 \\ (y_2, y_1), & \text{否则} \end{cases}\]\$ - 构造新的偏好数据集 \(D_i = \{(x, y_l, y_w) | x \in X_i\}\)。
自我优化:生成偏好数据的噪声处理与学习
1.噪声检测与标签优化: - 通过模型 \(\pi_\theta\) 的偏好概率检测不确定样本(噪声标签):
$z_= \[\begin{cases} 1, & \text{若 } p_\theta(y_w \succ y_l | x) < \tau \\ 0, & \text{否则} \end{cases}\]\ $
其中 \(\tau\) 是噪声样本的置信度阈值。 - 对噪声样本进行标签平滑处理,优化目标为:
$L_{rf}() = {(x, y_w, y_l) D_i}[-(1 - z_) p_(y_w y_l | x) + z_p_(y_l y_w | x)] \ $
其中 \(\alpha\) 是平滑系数。
解耦噪声检测: 在这部分内容中,作者介绍了一种解耦的噪声偏好检测技术,以提高偏好标签精炼框架的有效性。尽管通过精炼的偏好标签进行学习可以降低学习到噪声偏好的风险,但由于噪声检测的模型来自于标签生成模型,其效果可能会受到限制。为此,作者引入了解耦噪声检测技术来改善大型语言模型的对齐。
具体而言,作者通过模拟一个更强对齐的语言模型 $_e^$的偏好预测来识别偏好噪声。公式如下:
- 当 \(p_e^\theta(y_w \succ y_l|x) < \tau 时,z_e^\theta = 1\),否则$ z_e^= 0$。
通过这种解耦的识别方式,模型$ ^$使用精炼后的偏好标签进行训练,即用 \(z_e^\theta\) 替代公式中的 \(z^\theta\)。为了获得$ _e^\(的预测,作者通过线性组合\) ^$ 和参考模型 \(\pi_{\text{ref}}\) 的logit来近似其logit \(h_e^\theta\),公式如下:
\(h_e^\theta(x, y_{1:t-1}) = (1 + \lambda) \cdot h^\theta(x, y_{1:t-1}) - \lambda \cdot h_{\text{ref}}(x, y_{1:t-1}), 其中 \lambda > 0\) 是一个超参数,$y_{1:t-1} $表示第 \(t\) 个输出之前的输出序列。
这种通过近似 $p_e^(y_w y_l|x) \(进行的解耦噪声识别不需要额外的计算,**相当于对两个模型的logits进行加权和作为计算reward的logits**,因为所需的测量\) h^$ 和 $h_{} $在计算原始目标时已经获得。因此,SPA 只需在原始代码库上添加几行代码即可。完整的SPA流程在算法部分中给出。
1.最终优化:
- 使用解耦后的噪声标签 $z_{_^e} $替换 \(z_\theta\),并优化模型 \(\pi_\theta\)。

算法流程
1.使用种子数据 \(D_0\) 和初始模型$ _{init} $通过 DPO 获得初始模型 \(\pi_0\)。
2.迭代进行以下步骤: - 从新提示集合 $X_i $中生成偏好数据 \(D_i\)。 - 在$ D_i $上进行微调,同时引入噪声检测和标签优化。
返回最终对齐模型$ _T$。
SPA 方法通过以上流程高效扩展了偏好数据,同时显著降低了噪声干扰,提升了 LLM 的对齐性能。
实验部分
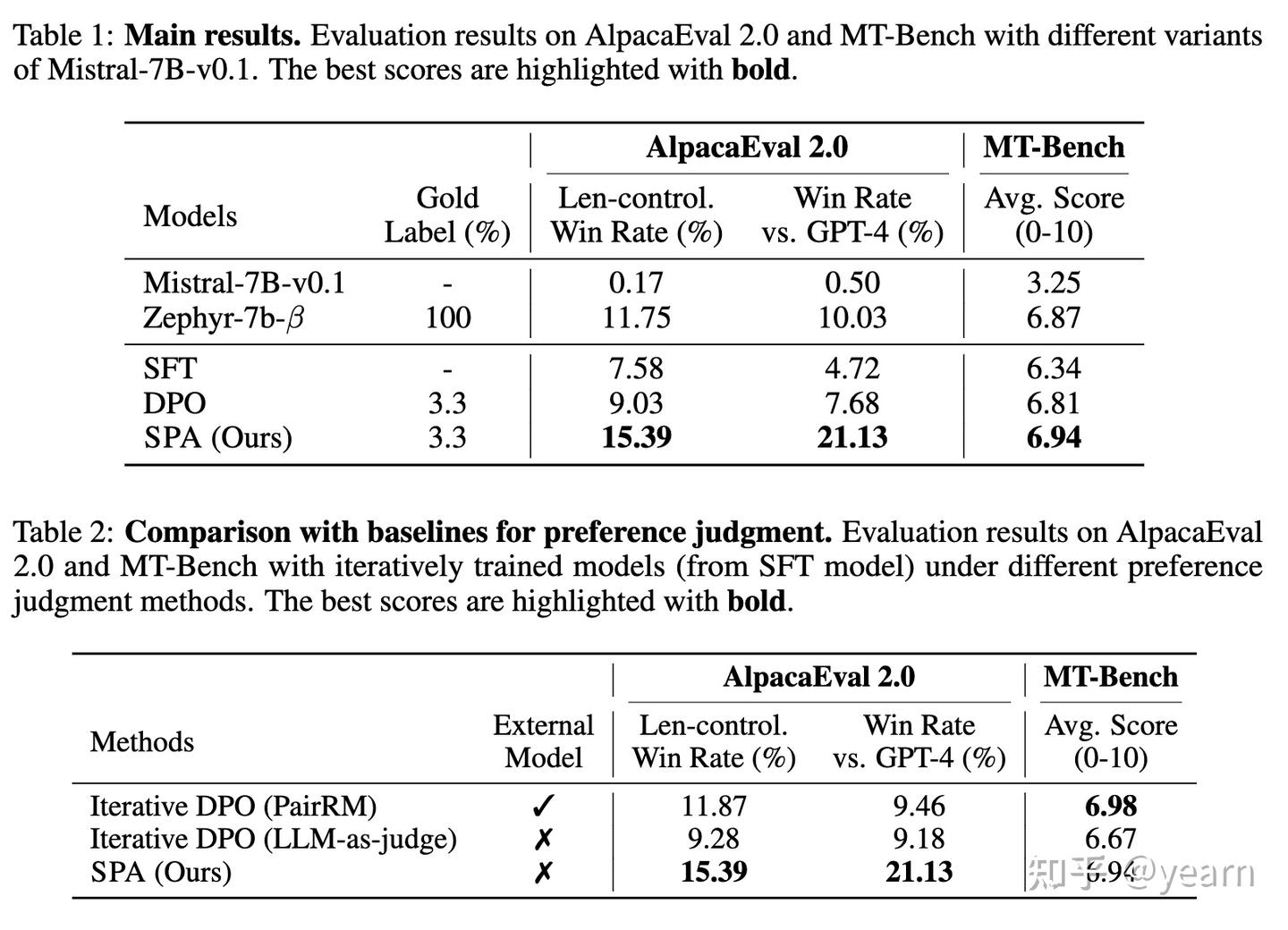
在这一部分,作者通过一系列实验验证了SPA(Self-Preference Alignment)方法的有效性和通用性。以下是一些有趣的实验发现:
- SPA在少量人工标注数据下的表现:在AlpacaEval 2.0基准测试中,经过3次数据扩展和微调后,SPA训练的模型在对抗GPT-4时达到了21.13%的胜率。这比仅使用3.3%标注数据进行标准DPO训练时的7.68%胜率有显著提升。同时,长度控制胜率也从9.03%提高到了15.39%。
- SPA与其他偏好标注方法的对比:在Table 2中,SPA在对抗GPT-4时的胜率为21.13%,明显优于使用外部奖励模型PairRM的9.46%。在长度控制胜率方面,SPA也以15.39%超过了PairRM的11.84%。这表明,SPA在偏好判断时更能适应数据分布的变化,因为它在每次迭代中都会更新其内在奖励模型,从而减少了分布偏移的影响。
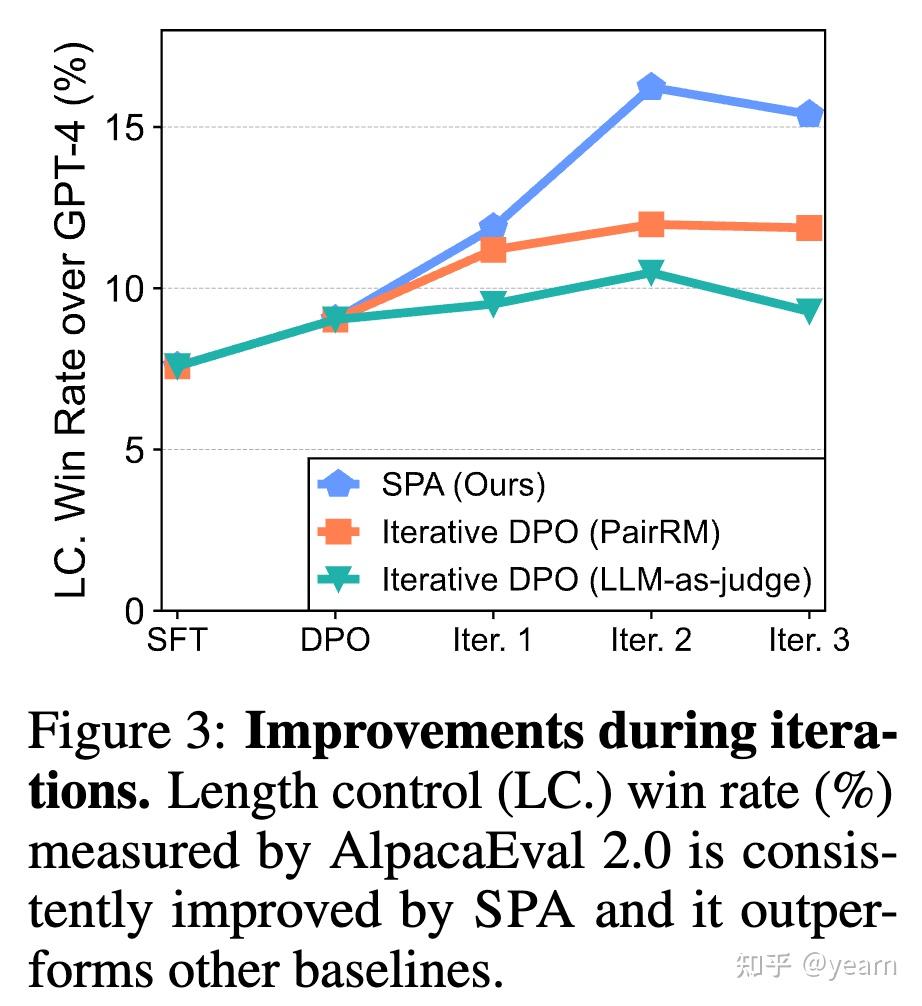
- SPA的通用性:实验表明,SPA在不同的种子数据选择和LLM类型上具有良好的通用性。在不同的迭代中,SPA一直保持了较高的性能,尤其是在第二次迭代时,SPA与其他方法的性能差距显著扩大,进一步支持了其有效性。
- 各组件的影响:通过对比不同偏好判断方法的实验,发现直接使用训练的LLM进行偏好判断的方法在多次迭代后效果更佳。这是因为随着迭代次数增加,生成数据的分布与初始偏好数据的分布差异增大,而固定的外部奖励模型在这种情况下效果下降。
这些实验结果充分展示了SPA方法在提升模型性能和适应性方面的优势,尤其是在数据有限的情况下。
更多分析
在这部分中,作者通过在AlpacaEval 2.0上的额外比较,进一步分析了SPA(自我偏好对齐)方法的效果。具体的更多比较和额外实验结果则展示在附录中。
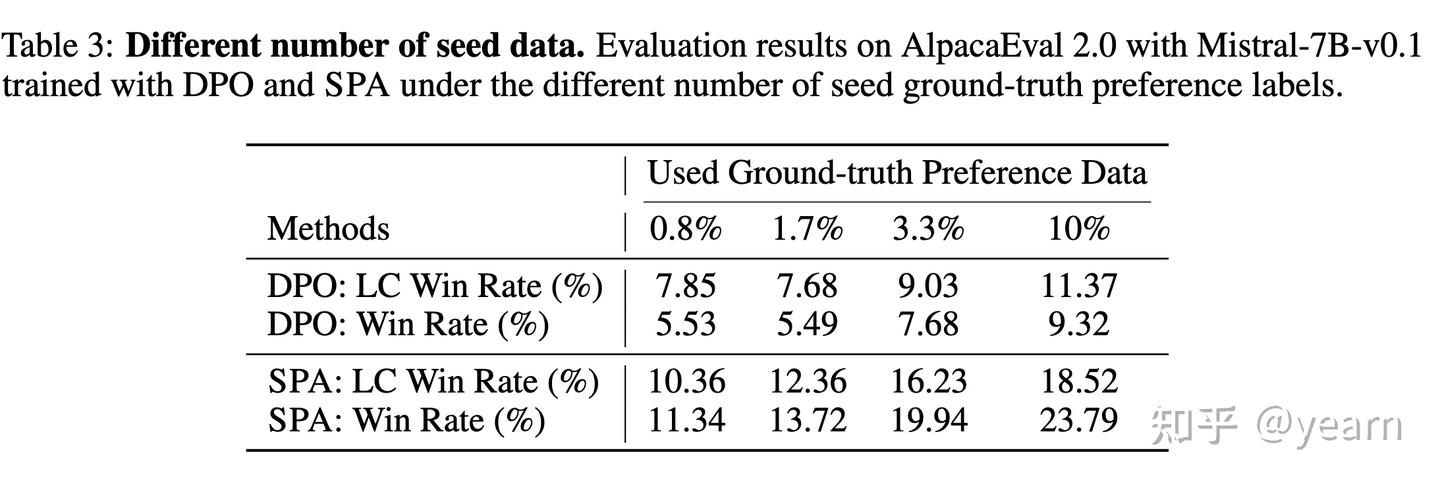
- 不同种子数据量的泛化能力:作者首先通过改变种子偏好数据的比例(0.8%,1.7%,10%),来检验SPA方法的有效性是否依赖于种子数据集的大小。结果显示,无论种子数据的比例大小,SPA的表现都一致优于DPO方法,这证明了SPA在不同种子数据量下的鲁棒性。
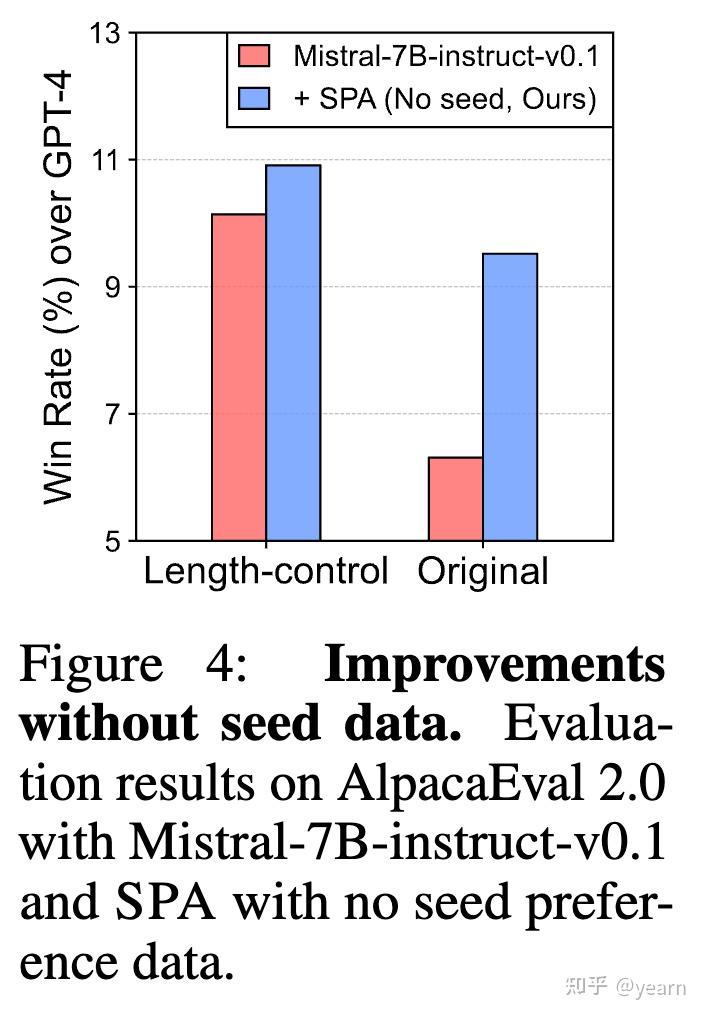
- 无种子数据的可行性测试:实验还探讨了在没有种子偏好数据的情况下,使用SPA方法的可行性。利用Mistral-7b-instruct-0.1v作为初始模型,并通过自我微调和数据扩展,测试模型在没有任何种子偏好数据的支持下的性能。结果显示,即使在没有种子数据的情况下,SPA也能有效地利用LLM内部信息与人类偏好对齐,胜率从6.31%提高到了9.79%,长度控制胜率也从10.14%提升到了11.59%。
- 不同初始种子数据集的敏感性:此外,作者还通过改变初始种子偏好数据集的随机抽样,来检验SPA对种子数据的敏感性。结果表明,SPA无论种子数据如何变化,都能持续改善对齐性能,尤其是在正常胜率情况下变化不大,而长度控制胜率虽有较高的变异性,但最低置信区间值(13.36%)仍高于最强基线的值(11.98%)。
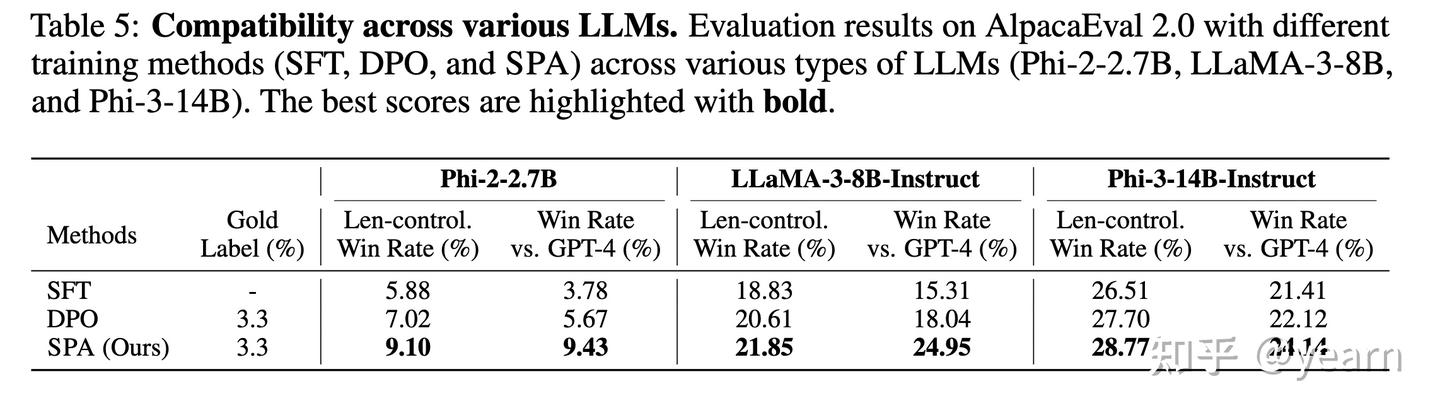
- 不同模型的兼容性:为了验证SPA框架在不同LLM上的兼容性,作者使用了三种不同的LLM(Phi-2-2.7B,LLaMA3-8B,Phi-3-14B)进行实验。实验结果显示,SPA在这些不同的LLM上应用后,都能一致地提高性能,例如在Phi-2上,经SPA训练后的胜率从5.67%提升到了9.43%,长度控制胜率也从7.02%提升到了9.1%。
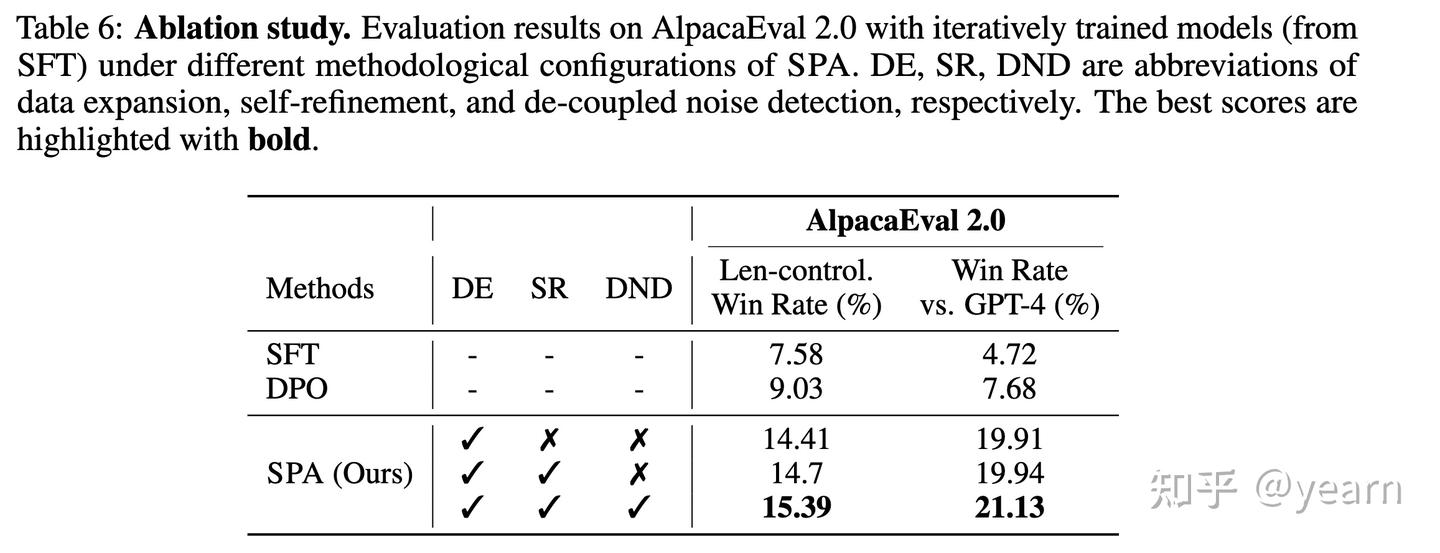
- 自我精炼组件的影响:通过去除自我精炼(SR)和解耦噪声检测(DND)两个组件进行消融实验,结果显示,当加入解耦噪声检测到自我精炼中时,胜率从19.91%提升到了21.13%,长度控制胜率也从14.41%提升到了15.39%。这些结果证实了自我精炼组件在提升性能中的重要性。
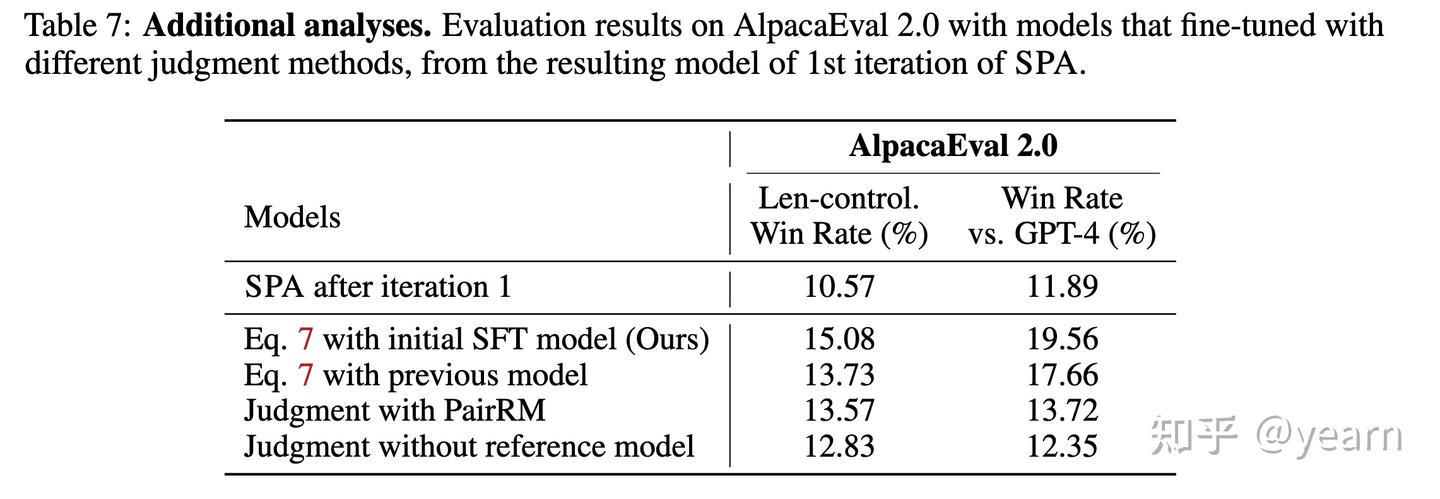
- 偏好判断方法的附加分析:在Table 7中,作者进一步分析了偏好判断过程中参考模型的影响。实验结果显示,使用SPA中的SFT模型作为偏好判断的参考模型,能获得最高的性能提升。这些发现强调了选择合适的判断方法和参考模型的重要性。
这些分析结果进一步验证了SPA方法在不同设置下的有效性和适应性,尤其是在偏好数据有限的情况下。
结论
在这篇文章中,作者提出了一种名为SPA的方法,该方法能够通过最少的人类标注偏好数据高效地提高大型语言模型(LLM)的对齐能力。文章的主要贡献包括:
- 1.数据扩展方法:开发了一种有效的数据扩展方法,结合了直接偏好判断方法。这种方法能够在有限的标注数据下,扩展出更多的训练数据,从而提升模型的表现。
- 2.偏好学习算法:引入了一种偏好学习算法,该算法具有自我精炼潜在噪声偏好的能力。这意味着即使在存在噪声的情况下,模型也能通过自我调整来提高对偏好的理解和学习。
作者通过在最新的LLM上进行微调,展示了SPA方法的有效性。在常用的基准测试AlpacaEval 2.0和MT-Bench上,模型表现出了显著的改进。作者预期SPA将在未来的研究和实际应用中做出重要贡献,特别是在人类标注偏好难以收集的情况下。