聊聊强化学习发展这十年
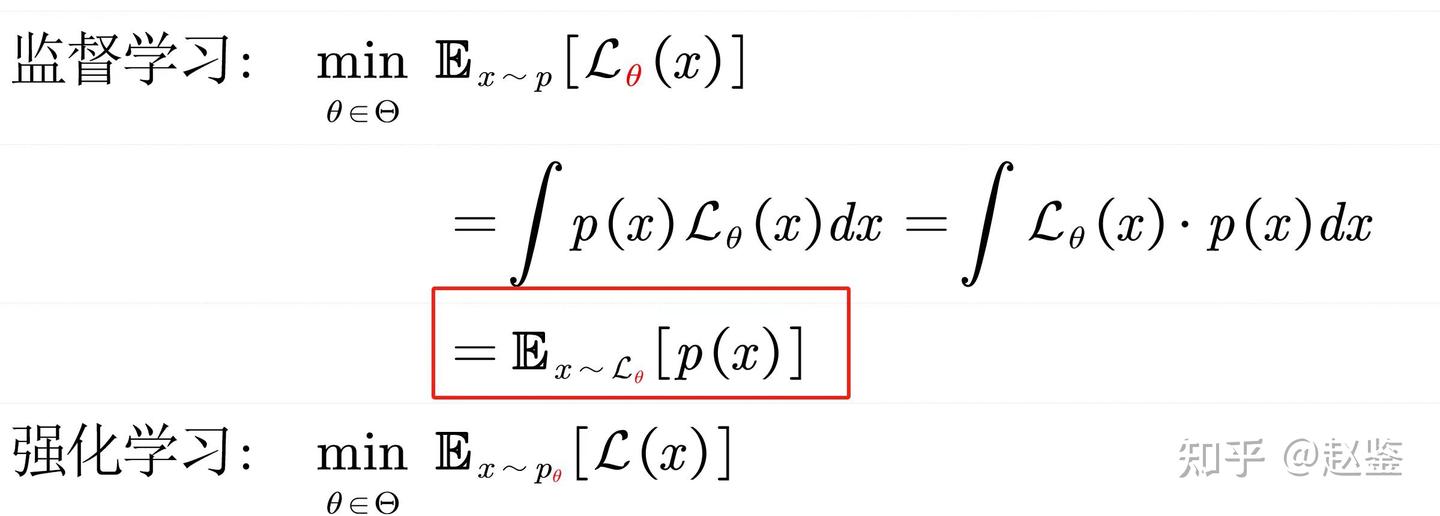
聊聊强化学习发展这十年
青稞
- 作者:赵鉴,中科大博士
- 原文:https://zhuanlan.zhihu.com/p/31553187995
(前言:这篇文章我从祖师爷评上图灵奖的时候开始写的,但不停的在删了重写,删了重写,到现在为止才出一个我勉强接受的版本。我从我的视角来描述下我觉得这些年来强化学习的发展风向。先叠个甲,本人学术不精,本文所有观点都乃我一家之言,欢迎大家批评指正。)
最近在帮忙给强化学习立标准,我发现这是一件非常痛苦的任务。因为随着这两年强化学习的大力发展,强化学习衍生出了许许多多的子课题方向,除了最经典的online RL以外,
例如offline model-free RL,model-based RL,RLHF,multi-agent,risk-sensitive,inverse RL等等,要给这些子课题找共性非常困难。
而在传统教科书中,强化学习的标准制定时由于这些子课题还未出现,导致定义早已过时。举个例子,例如强化学习强调智能体跟环境交互,而offline RL方向偏说我就不跟环境交互。再例如强化学习强调无需人类标签还是采用奖励信号,RLHF说我就不是这样。
所以我打趣说,这就像以前府里有个RL的老太爷。老太爷年轻气壮的时候,所有的子子孙孙都说自己是RL府里的。结果随着日子发展,RL府里的少爷们走了不同的方向,一个个飞黄腾达,有些混的比老太爷都好了。这时你说要在RL几个儿子里找到相同特性,只能说有点不合时宜了,勉强只能说他们都留着RL的血脉吧。
于是我只能根据强化学习这10年左右的发展时光,看看每个阶段给强化学习做了怎么样的注解。
强化学习一阶段:
大概在十年前,在我刚做RL的时候,其实RL没有定义,只有描述,大家认为RL是一种解决马尔可夫决策过程的方法,典型算法包括DQN、PPO。当然那时我们有一种历史局限,就认为这个描述是个充要条件。也就是认为只有value-based算法(DQN),policy-based算法(PPO)这种才算是强化学习,其他统统不算。
同时这个阶段,有大量的强化学习研究者开始涌入这个方向,大家总体分为两拨,学术界的学者试图研究通用的强化学习算法,而工业界的人则在给强化学习找应用场景。
那像作者这样天资愚笨的同学自然在通用算法上没有办法做出太多创新,于是大家开始给强化学习的问题定义做细致扩展,出现了多智能体强化学习, 安全强化学习等等的强化学习子方向。
从后验角度出发,其中某些子方向的问题定义其实缺乏实践依据,导致强化学习产生了一个后遗症:给人留下了没法用的污点。
强化学习二阶段:
随着第一批强化学习研究生的毕业,强化学习也进入了大应用时代。最开始,人们对强化学习应用的要求也非常严格,在强化学习应用的论文描述里必须有以下内容:
1.非常准确的状态空间和动作空间定义 2.必须存在状态转移函数,不允许单步决策,也就是一个动作就gameover 3.必须有过程奖励,且需要存在牺牲短期的过程奖励而获取最大累计回报的case案例
说个开玩笑的话,如果DS的文章放到几年前RL的审稿人手里,他大概率会得到这样的回复:这只是采用了策略梯度的方式将不可导的损失/奖励函数用于优化神经网络参数而已,请不要说自己使用了强化学习。
这导致像作者这样的old school,在看到最新的强化学习应用文章时,总会试图问文章作者几个基础的问题,状态是啥,动作是啥,奖励是啥。但其实现在很多文章已经不考虑这些问题了。
那时大家普遍认可的应用方向是游戏AI,因为游戏AI符合上述所有的定义,并且游戏环境较为容易获得。但较为可惜的是,以强化学习为核心的游戏AI应用市场份额不大,随着PR价值的慢慢淡去,这个领域渐渐容纳不下日益增长的强化学习研究生。
而在落地其他工业场景的时候,由于仿真器的不完善,导致强化学习难以开展智能体训练。如果仿真器投入程度不高,同时又存在sim2real这个难以逾越的问题,市场慢慢对其失去了信心。
大家只好开始自谋生路。
强化学习三阶段:
作为经历过二阶段的研究者们发现,强化学习落地的真正难点在于问题的真实构建,而非近似构建或策略求解等等方面的问题。所以首先强化学习的概念扩大了,从原先任务只有求解策略的过程是强化学习,变成了构建问题+求解策略统称为强化学习。
典型如offline model-based RL和RLHF,其中核心的模块变成了通过神经网络模拟状态转移函数和奖励函数,策略求解反而在方法论中被一句带过。
我个人觉得这件事是具有强化跨时代意义的,因为理论上这个过程可以被解耦,变成跟强化学习毫无相关的名词概念,例如世界模型概念等等。非常感谢RL方向大牛研究者的持续输出,是他们工作的连续性,保证了强化学习的火焰没有在这次迭代中熄灭。
继续发展下去,人们发现:可以解决一切问题的强化学习被证明,没有有效的交互环境下的就没法达到目标,有这种有效交互环境的实际应用场景却非常少。导致把决策问题的过程步骤:问题建模、样本收集、策略训练、策略部署的周期拉得更长了,这几个步骤不是跟在线强化一样那么紧凑,是断开了链路的。
于是神奇的事情发生了:中间过程的任何一个步骤都变成了强化学习!
但实话实说,即使出现了这样程度的概念扩大,强化学习的应用落地仍然不太乐观。
直到大模型训练把整套逻辑发扬光大了。
强化学习四阶段(猜测未来):
直到现在,我们有一次在讨论强化学习和监督学习分界线的时候,大家都一时语塞。某数学系的老哥给出一个定义。
监督学习优化的是 非参分布下的含参loss function 强化学习优化的是 含参分布下的非参loss (cost/reward) function? 公式如下:
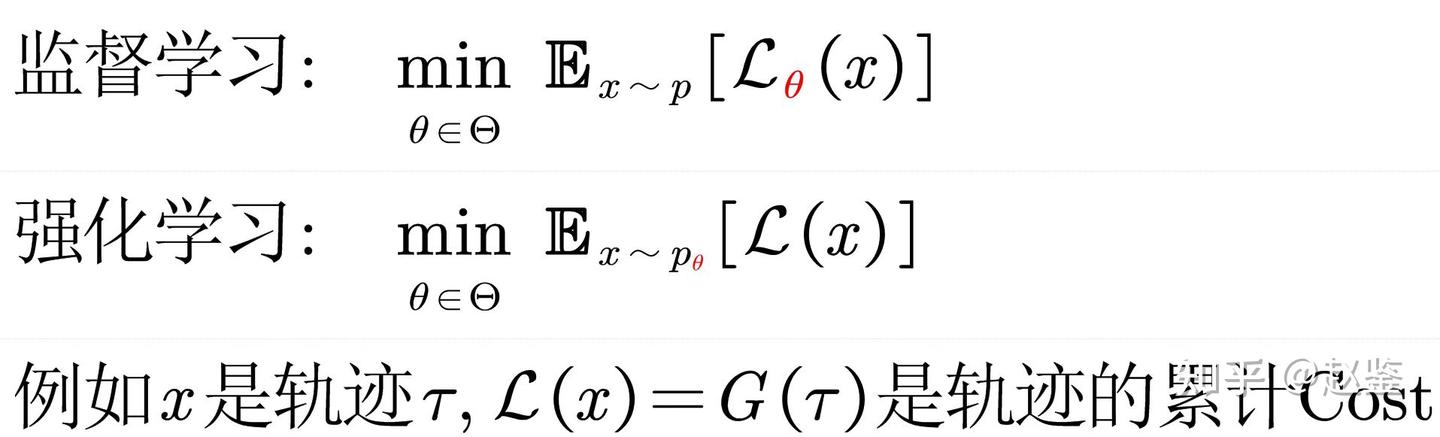
但我说这个公式可以做轻微推导:
这时我们得到了一个暴论:监督学习只是强化学习的一个特例。
具体的case也不难获得,例如在二分类问题中,状态是输入特征,输出是0/1,奖励是分类正确了给1,分类错误了给0。基于PG的推导公式跟二分类entropy loss是完全一致的。无监督的例子跟强化学习的关系也可以得到类似的推导。
那我们熟知的概念:机器学习分为监督学习、无监督学习和强化学习。
变成了:机器学习就是强化学习,监督学习和无监督学习只是其中的特例。
那么强化学习的应用也就会变得越来越多,让人们觉得它越来越有用。
后记:
写到这一块我开始杞人忧天,难以下笔。我开始思考这种发展对于RLer来说是否健康的。
持反对意见的领域就是文章开头的祖师爷sutton,祖师爷理论上是这一波RL概念扩大收益最大的人,但祖师爷在talking上表达了他的观点:

甚至在某次和小伙伴的交流中,祖师爷说RLHF是scam,持完全的否定态度。
但作为一个强化学习研究者,并尝试去进行AI应用落地的人来说,至少这波RL概念扩大,让RLer吃上了饭,甚至吃上了好饭,应该还是要对此心怀感激的吧。