我的RL人生哲学:写给Sutton & Barto的图灵奖时

我的RL人生哲学:写给Sutton & Barto的图灵奖时
青稞
- 作者:曹宇@知乎
- 原文:https://zhuanlan.zhihu.com/p/28202119556
我不知道怎么做这一篇的开场,只能先把一张从Sun Hao那边盗来的一张图放在这里,图中是第一届RL Conference(RLC)的一幕:台上神情颇为严肃的是 Andrew(Andy)Barto,台下蓄着胡须的则是 Rich Sutton。他们今年共同因为在强化学习(RL)领域的突出贡献,获得了图灵奖,这个在计算机界最高的殊荣。
他们的得奖实至名归,甚至稍有些晚了,Sutton依然奋战在科研一线,不过Barto已开始颐养天年。有人说强化学习终于站起来了,RL works,在强化领域持续耕耘的同学也守得云开见月明了。我想说这都是表象,强化人背后的艰辛与隐忍是不足为外人道的:强化是一种道,术可以练习,道需要修行。
苦涩的教训
大多数接触强化学习可能有几个时间点:Atari游戏、AlphaGo大战柯洁、R1爆火。大多数人放弃强化学习可能有几个时间点:看不懂公式、找不到工作、训练不出来效果。成败之道就在于这个苦涩的教训 The Bitter Lesson:

这篇至今仍然挂在Sutton主页上的文章,说明的是这样的一个道理,过去接近80年的AI研究告诉我们找到一种能够通用的高效利用算力的方法才是推动AI前进的第一性原理。人类的领域知识和先验虽然表面上和AI的算力扩张并不冲突,但是无数的经验告诉我们,人类的知识偏向于将整个问题变得复杂直到算力无法充分施展。所以我们要克服人类的偏见,用更通用的方法利用更多的算力及摩尔定律来推动AI的发展。
很少有其他的AI领域像RL一样,还没学技术呢就先来一个教训。须知,大道至简,大美天成。loss改一改,结构动一动,数据调一调这些连术都算不上的trick,最终都无法抵抗住这个大道。就如在大模型领域,除了DPO这一种严格数学等价的对齐方法之后,各类XPO的结局无非都是走向凋零。因为这些方法希望用人的简单启发去对抗算力的scaling,道不同,不相为谋,AI 就不会 work。
Bitter Lesson 在很多方面有自己的阐释:David Silver,Noam Brown,以及 Hyung Won Chung 等 RL 当代弟子都在各自的领域做出过新的阐释。
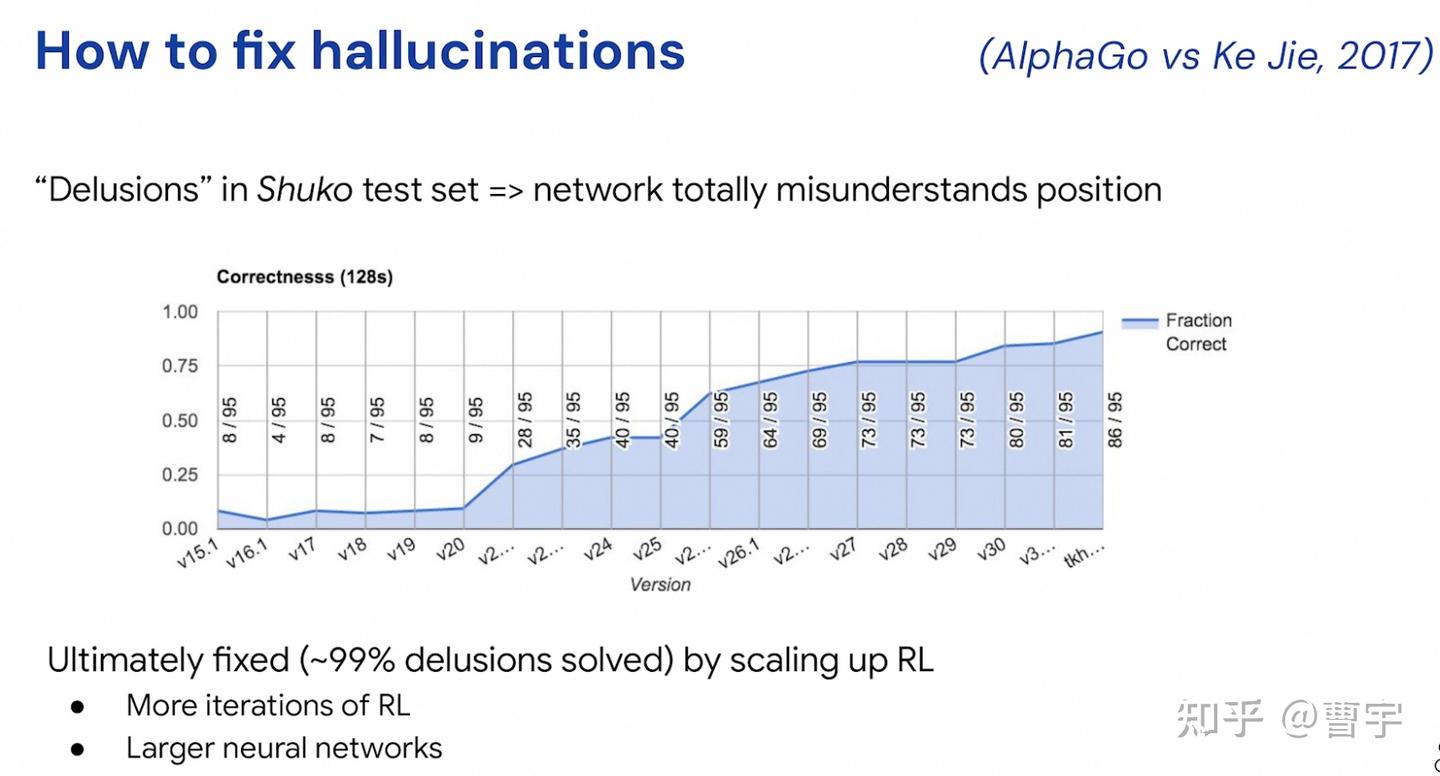
David Silver: 如何修复AlphaGo中的幻觉问题?99% 的问题可以通过scaling up RL来解决,既可以是更多的RL迭代,也可以是更大的网络。
Hyung Won Chung:更少的人类结构,更好的计算scaling law
Noam Brown:不要做One Weird Trick

我相信真的经历并真实感受过苦涩的教训,方才可以算是入了强化学习之门。这才有后话,Scaling即是一种算法思想也是一种工程能力。给你几千卡,你真的做好了用起来这些算力的准备了嘛?不论RL的工作表面看起来是什么样,背后的坚毅和隐忍就是为了这个大道而服务的。
RL = Search + Memory
说完了Sutton这边,Barto去年在第一届RLC的演讲也是对于其鞠躬尽瘁的RL研究生涯的一次谦虚的回顾,同样作为祖师爷,这边讲了另外一个强化学习的道:要勇于探索,并时常学习。

这其实已经不是一种简单的RL的道了,更多的是一种人生哲学了:我们为什么要探索,我们如何去探索,我们如何判断探索出来的结果的好坏,我们如何在稀疏而充满噪声的信号中学习,我们如何记住过去的成功与错误从而更好地在下一次遇到类似情况下应对。
这些都是RL算法本身最重要的技术命题,但是当我把他写在这里的时候,和你我在人生的旷野中苦苦追寻又有何异呢?我们当然可以选择不去探索,只利用以往过去所有的知识,这样既不会太对,也不会太错。我猜这也是为什么ilya说:(我们都知道的那种)预训练即将终结了,因为预训练就是没有探索,我们的目标是从祖宗的经验中牢记未来将会发生什么,这种智能更像是人类对于AI的馈赠。
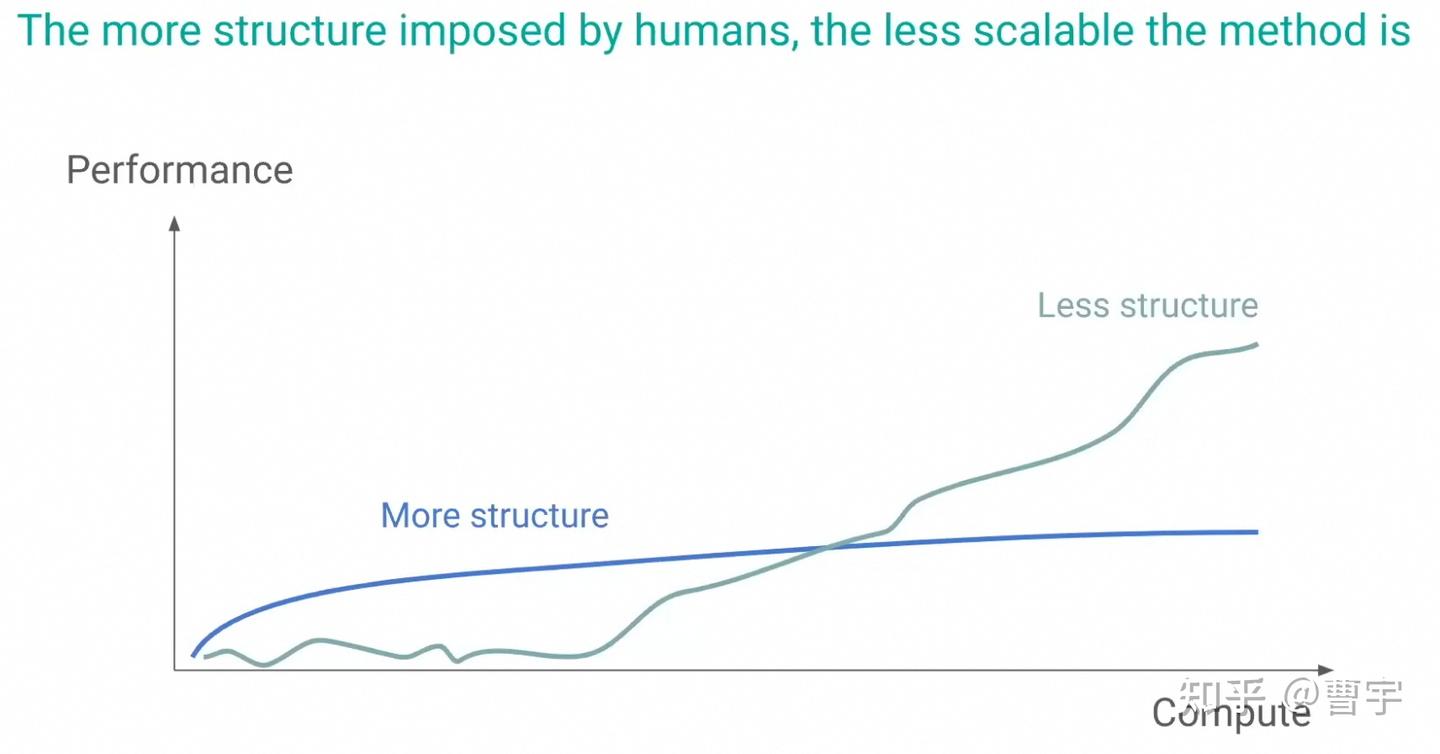
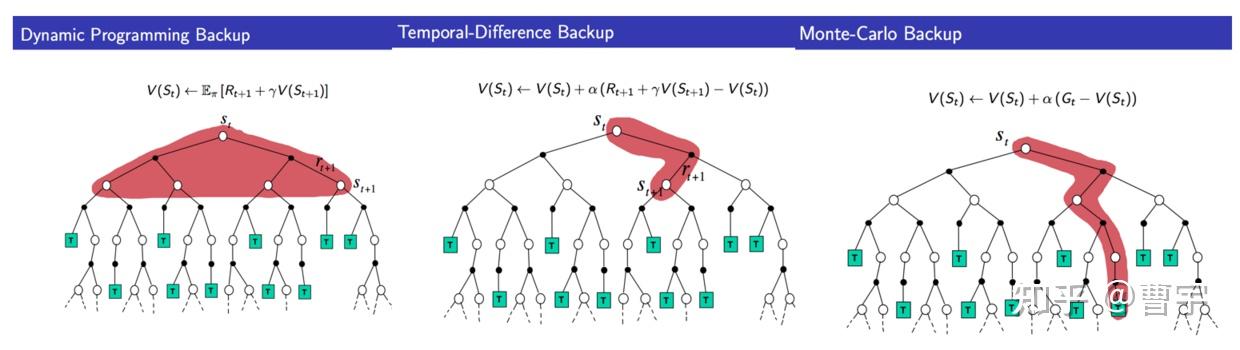
那么我们如何去探索呢?对于人来说,这一辈子拥有的能量和时间是有限的,我当然期望Dario所说的“生命逃逸速度”可以在我这辈子实现,但是在这之前,我们每个人都是仅有定量探索机会的个体。这个探索机会就是下图里面的红色部分,到底是选择DP(全面出击),TD(走一步看一步),MC(梭哈到底)本质上还是取决于我们作为一种有生命的个体,到底选择如何过自己的人生。AI 不会有这种痛苦,从某种程度上来说,他可以在算力足够的情况下采用下面任何一种模式。但作为人你要敢赌(MC,TD),不赌你的生命(红色的资源)会先耗尽。
我们如何判断探索出来的结果的好坏呢?当然取决于问题的难度,对于明确的问题,比如数学题来说黑白分明,利用Verifier便可以做到。这种问题上,我们在过去的几个月不断取得狂飙,o1,R1等等直接掀翻老模型的桌子,留在桌上的只有Sonnet 3.7了。但现实世界的复杂,人类偏好的诡异是非常难以捉摸的,RLHF做到今天其实还是面临着我向谁对齐,以大模型为主的结果逐渐渗透到人们生活的方方面面。但不论技术如何进步,我们都不可能做到完全不偏不倚的判断,到了某一个阶段这个问题就上升到了算法主创的审美和ta的胸怀了。除了Antrophic我不知道有谁现在正视到了这个问题,一个模型必然是这个模型研发团队的审美平均值。甚至连代码类任务都是如此的,对不对是好判断的,好不好是主观的。Sonnet 3.7出来的 UI 精美程度,和codeforce的能力有关,但和AIME其实并无明确关联。
我们如何在稀疏而充满噪声的信号中学习?强化学习本来就是一种长序列决策的艺术,我们从控制系统、游戏AI再到大模型、具身大模型的发展脉络中看。这必然会牵涉到我们如何在稀疏的奖励信号中学习,而这种奖励信号本身还可能存在缺陷。不要想取得一个完美的奖励信号,这是一件不可能的事情。我们只能期望有一种方法,指导我们在这种环境下仍然能够学到东西。
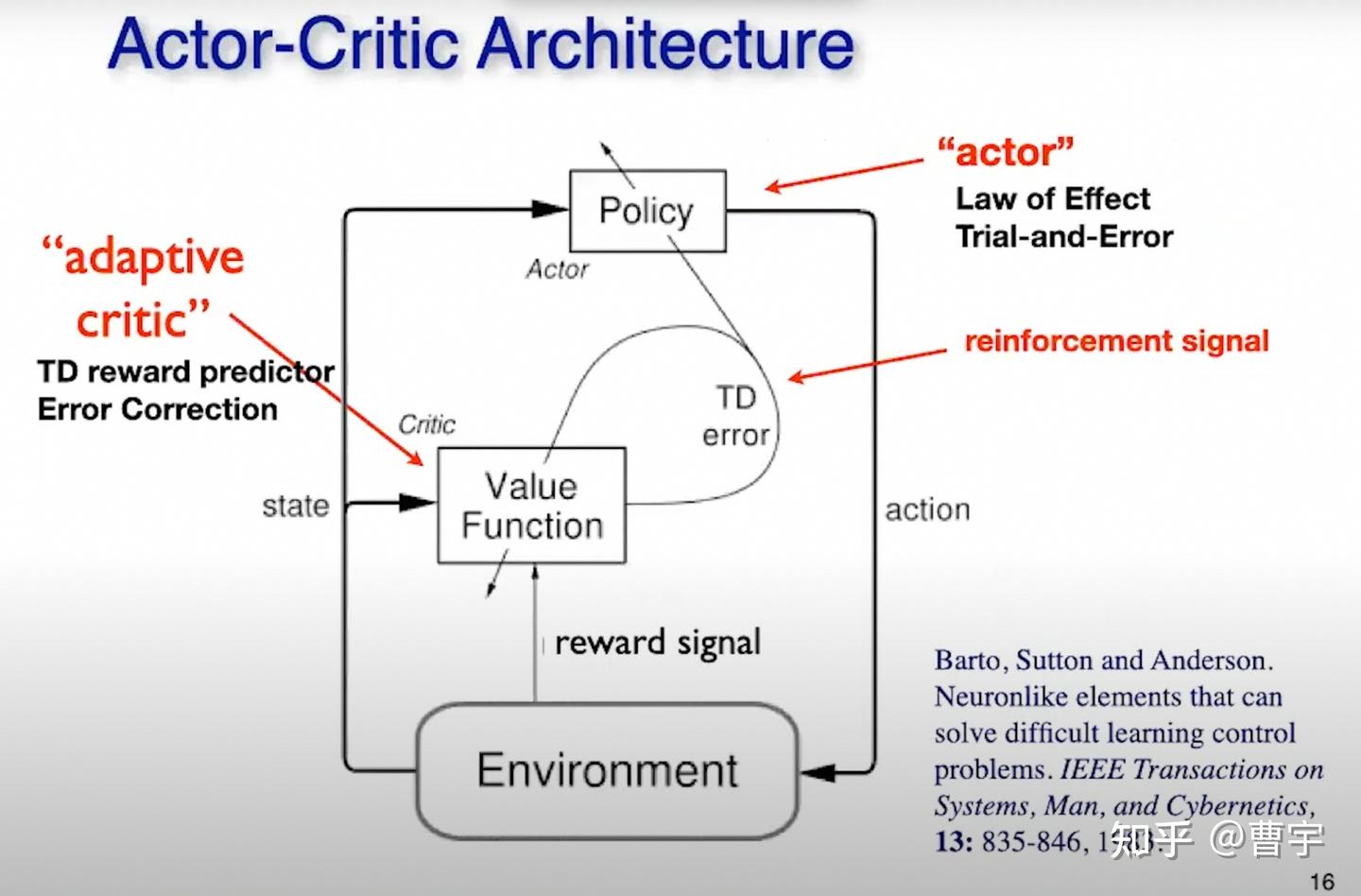
这便是Barto和Sutton获奖的作品之一:Actor Critic架构,模型与环境交互并观察,但不直接用环境给他奖励决定自己的行为。反而采用自己的价值函数(价值观)来判断自身价值与现实的差距,使用这种差距最终改变自己的行为。这种算法在机器人控制、游戏AI、大模型对齐等领域不断开花结果,为产业做出了大量的贡献。难的是什么,我们每个人都要有自己的value,没有它你可能会被reward震荡飞起来。
我们如何记住过去的成功与错误从而更好地在下一次遇到类似情况下应对,其实这里才是大家看到的所谓的术的部分。什么PPO和GRPO的区别都在这里而已,重要也重要,不重要也不重要。重要的是,不能因为获得惩罚的奖励就过度贬低自己过去的行为,更不能因为获得一点点小的随机性奖励就沾沾自喜而强化一个看似正确的行为。从TRPO到PPO都是这么一种隐忍的做法,限制住更新的步伐,慢慢提升并逼近智能的极限。
总结和展望
今年正好是我入行RL 10年整,我在这一行隔空相望祖师爷,并和行业一起一步一步成长起来。我尽量控制不聊太多关于我自己可能有主观偏见,但这篇有力量的文字应该代表了很多与我类似的RL领域的坚守者的内心,我们是很矛盾的个体:虽然不好赌,但是不得不赌。虽然看起来表面不温不火,但是个个都是内心揣着AGI。对于新入行的同学来说,你们看到我的文字会觉得很奇怪,但当你在探索的路径上遭遇挫折时,请回来再看看,先悟道再学术。