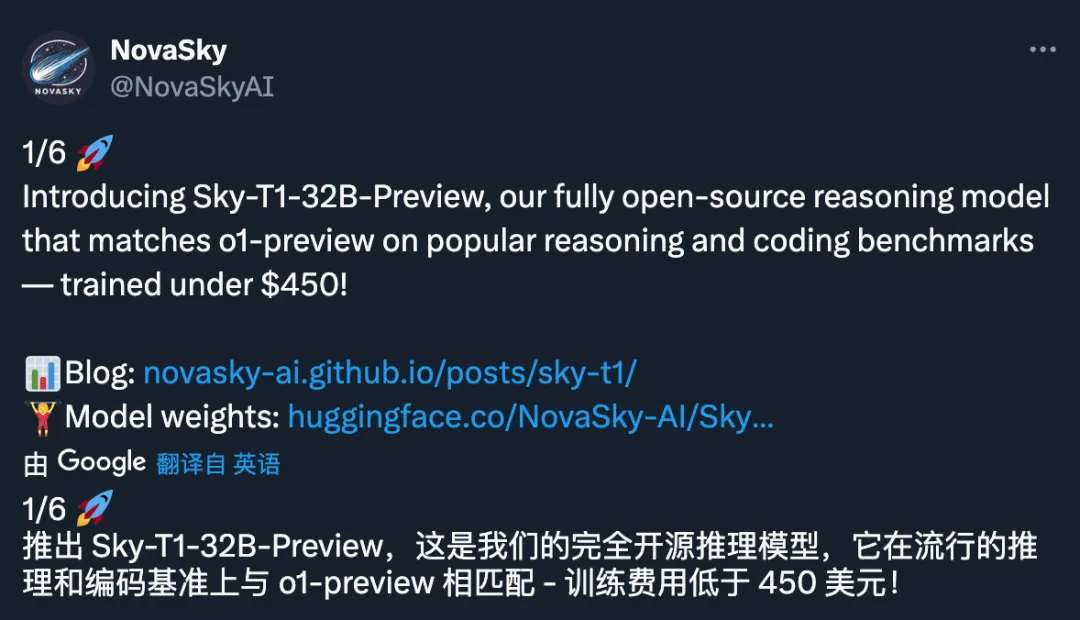
Sky-T1-32B-Preview:450美金就可以训练的o1-preview【模型权重与训练细节已完全开源】

Sky-T1-32B-Preview:450美金就可以训练的o1-preview【模型权重与训练细节已完全开源】
青稞原文:https://novasky-ai.github.io/posts/sky-t1/
>>加入青稞AI技术交流群,与青年研究员/开发者交流最新AI技术
Sky-T1-32B-Preview 是我们推出的推理模型,在常见的推理和编码基准测试中,其表现可与 o1-preview 媲美。值得注意的是,Sky-T1-32B-Preview 的训练成本不到 450 美元,展示了以经济高效的方式复制高水平推理能力的可能性。
1 | 代码库:https://github.com/novasky-ai/sky-t1 |

背景
诸如 o1 和 Gemini 2.0 等在推理方面表现出色的模型,能够通过生成长链的内部思考来解决复杂任务。然而,这些模型的技术细节和权重尚未公开,限制了学术界和开源社区的参与。
为此,一些在数学领域训练开源推理模型的努力相继出现,例如 STILL-2 和 Journey。同时,我们伯克利大学的 NovaSky 团队也在探索多种技术,以提升基础模型和指令微调模型的推理能力。在这项工作中,我们实现了在同一模型中,不仅在数学推理方面取得了竞争性表现,在编码领域也同样出色。
完全开源:共同推动进步
为了让我们的工作惠及更广泛的社区,我们致力于开源合作。我们公开了所有细节(包括数据、代码、模型权重),以便社区能够轻松复制和改进我们的成果:
- 基础设施:用于构建数据、训练和评估模型的完整代码库。
- 数据:用于训练 Sky-T1-32B-Preview 的 17,000 条数据。
- 技术细节:我们的技术报告以及训练日志。
- 模型权重:我们的 32B 模型权重。
| Model |
Sky-T1-32B-Preview
|
STILL-2
|
Journey
|
QwQ
|
o1
|
|---|---|---|---|---|---|
| Data |
✅
|
✅
|
❌
|
❌
|
❌
|
| Code |
✅
|
❌
|
❌
|
❌
|
❌
|
| Report |
✅
|
✅
|
✅
|
❌
|
❌
|
| Math Domain |
✅
|
✅
|
✅
|
✅
|
✅
|
| Coding Domain |
✅
|
❌
|
❌
|
✅
|
✅
|
| Model Weights |
✅
|
✅
|
❌
|
✅
|
❌
|
通过共享这些资源,我们旨在赋能学术界和开源社区,基于我们的工作探索新的可能性,推动推理模型开发的边界。
方法
数据整理过程
为了生成训练数据,我们使用了 QwQ-32B-Preview,这是一款在推理能力上可与 o1-preview 相媲美的开源模型。我们策划了数据混合(见后续部分),以涵盖需要推理的多种领域,并采用拒绝采样程序来提高数据质量。然后,我们使用 GPT-4o-mini 对 QwQ 的推理过程进行重写,形成格式良好的版本,以提高数据质量和解析的便利性。我们发现,易于解析对于推理模型尤为重要——它们被训练以特定格式响应,而结果往往难以解析。例如,在 APPs 数据集中,如果不重新格式化,我们只能假设代码写在最后的代码块中,此时 QwQ 的准确率仅约为 25%。然而,代码有时可能写在中间位置,重新格式化后,准确率提升至 90% 以上。
拒绝采样:如果 QwQ 的样本根据数据集中提供的解决方案被判定为错误,我们将其丢弃。对于数学问题,我们与标准答案进行精确匹配。对于编码问题,我们执行数据集中提供的单元测试。最终数据包含来自 APPs 和 TACO 的 5,000 条编码数据,以及来自 AIME、MATH 和 NuminaMATH 数据集奥林匹克子集的 10,000 条数学数据。此外,我们保留了来自 STILL-2 的 1,000 条科学和谜题数据。
训练
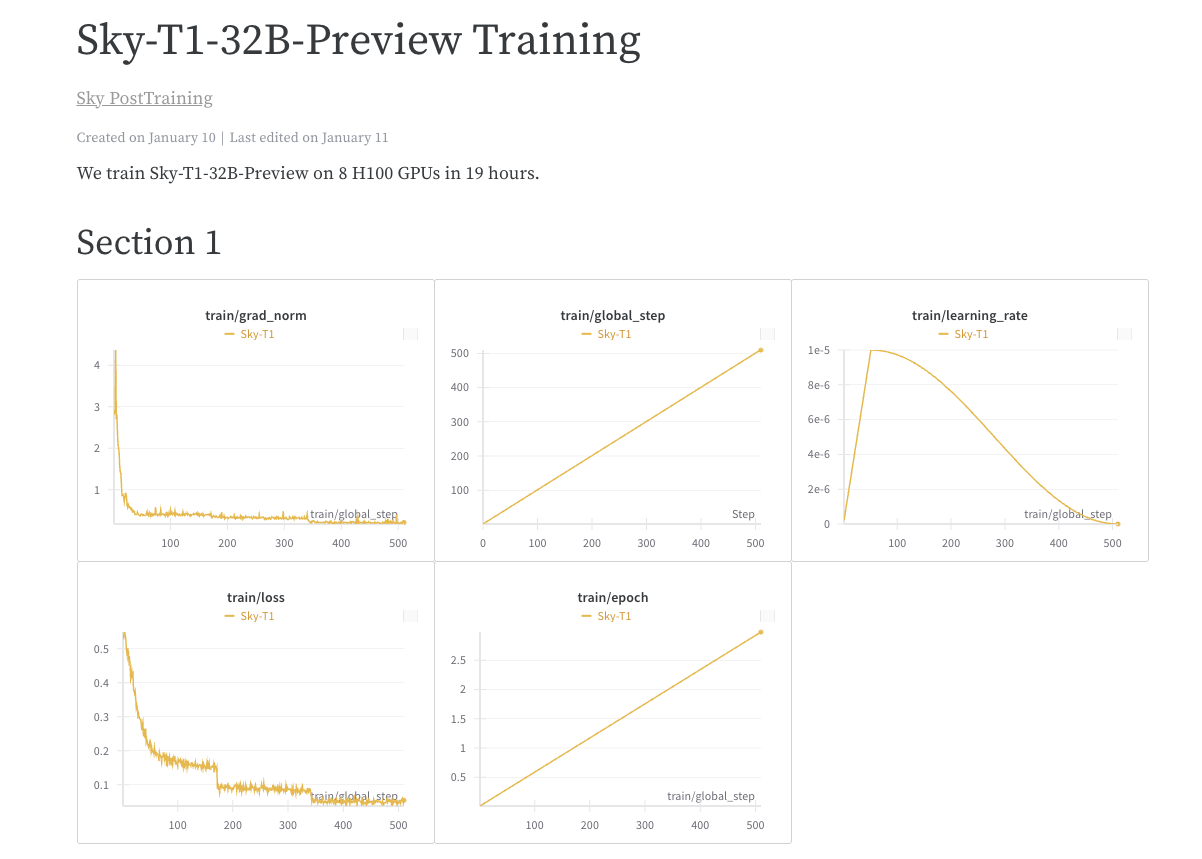
我们使用整理的数据对 Qwen2.5-32B-Instruct 进行微调,这是一款开源但缺乏推理能力的模型。模型训练进行了 3 个周期,学习率为 1e-5,批次大小为 96。使用 DeepSpeed Zero-3 offload,在 8 个 H100 上训练 19 小时完成(根据 Lambda Cloud 的定价,约 450 美元)。我们使用 Llama-Factory 进行训练。
评估与结果
| 模型 | Math500 | AIME2024 | LiveCodeBench-Easy | LiveCodeBench-Medium | LiveCodeBench-Hard | GPQA-Diamond |
|---|---|---|---|---|---|---|
| Sky-T1-32B-Preview | 82.4 | 43.3 | 86.3 | 56.8 | 17.9 | 56.8 |
| Qwen-2.5-32B-Instruct | 76.2 | 16.7 | 84.6 | 40.8 | 9.8 | 45.5 |
| QwQ | 85.4 | 50.0 | 90.7 | 56.3 | 17.1 | 52.5 |
| o1-preview | 81.4 | 40.0 | 92.9 | 54.9 | 16.3 | 75.2 |
其他发现
模型大小很重要
我们最初尝试在较小的模型(7B 和 14B)上进行训练,但仅观察到有限的改进。例如,在 APPs 数据集上训练 Qwen2.5-14B-Coder-Instruct,只使 LiveCodeBench 的性能从 42.6% 略微提升至 46.3%。然而,通过手动检查较小模型(小于 32B)的输出,我们发现它们经常生成重复内容,限制了其有效性。
数据混合也很关键
我们最初使用来自 Numina 数据集的 3,000 至 4,000 条数学问题训练了一个 32B 模型,但在数学基准测试上仅取得了有限的改进。
通过这项工作,我们展示了以相对较低的成本训练高性能推理模型的可行性,并希望我们的开源资源能够促进该领域的进一步研究和发展。
对未来的展望
Sky-T1 的推出不仅展示了经济高效训练高性能推理模型的可能性,同时也为开源社区提供了许多宝贵资源。我们期待以下方向的进一步发展:
- 扩展领域覆盖:除了数学和编码领域外,探索其他需要复杂推理能力的任务,例如科学问题、自然语言理解和逻辑谜题等。
- 优化模型架构:通过进一步优化架构设计,尤其是在处理长链推理和复杂问题时,提高性能。
- 社区合作:我们希望通过开源合作,吸引更多的开发者和研究人员加入,共同完善和优化 Sky-T1 的能力。
结语
通过 Sky-T1-32B-Preview 的发布,我们实现了以低成本构建高效推理模型的目标,表明开源与创新并存的可能性。我们期待通过开源的方式推动该领域的发展,并愿意与学术界、工业界及开源社区的伙伴们携手,共同探索人工智能模型的未来。