大模型Weekly 05|450美元训练32B推理模型,并开源;微软开源Phi-4
大模型Weekly 05|450美元训练32B推理模型,并开源;微软开源Phi-4
青稞「青稞·大模型Weekly」,持续跟踪工业界和学术界 AI 大模型产品每周的最新进展和创新应用。
NovaSky发布Sky-T1-32B-Preview推理模型
训练成本不到 450 美元
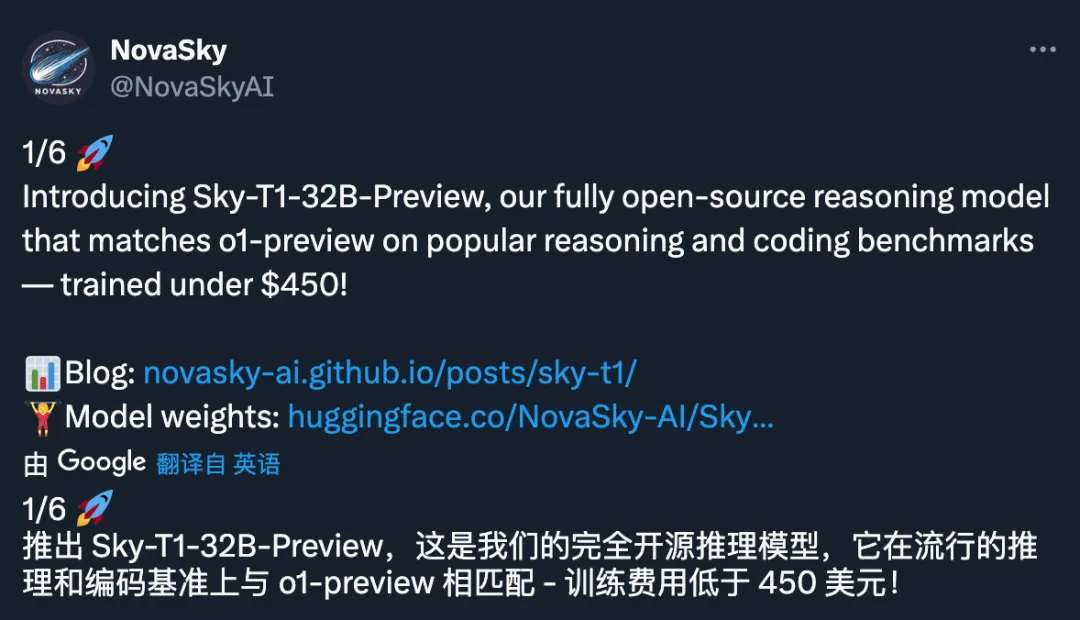
Sky-T1-32B-Preview:450美金就可以训练的o1-preview【模型权重与训练细节已完全开源】
2025年1月12日,加州大学伯克利分校天空计算实验室的研究团队NovaSky发布Sky-T1-32B-Preview推理模型。该模型在多个关键基准测试中表现出与OpenAI早期o1版本相当的水平,且其训练成本不到450美元,远低于以往同类模型的数百万美元。
Sky-T1-32B-Preview不仅是首个真正意义上的开源推理模型,NovaSky团队还公开了用于训练它的数据集及必要的训练代码,这意味着该模型可以从头开始复制。这一突破得益于合成训练数据的广泛应用,合成数据由其他模型生成,能够显著降低训练成本。

昆仑万维发布「天工大模型4.0」o1版和4o版
o1版具备中文逻辑推理能力,4o版可以提供情感表达和快速响应的实时语音对话助手Skyo
昆仑万维集团推出「天工大模型4.0」o1版和4o版,在原有基础上全面升级和优化,具有更强的计算能力和更广泛的应用场景,「天工大模型4.0」o1版(Skywork o1)作为国内首款具备中文逻辑推理能力的模型,更是对中文语言处理和逻辑推理能力的一次重大突破,不仅包含上线即开源的模型,还有两款性能更强的专用版本,经过全方位的技术栈升级和模型优化,由昆仑万维自研的Skywork o1系列能熟练处理各种推理挑战,包括数学、代码、逻辑、常识、伦理决策等问题。「天工大模型4.0」4o版(Skywork 4o)是多模态模型,其赋能的实时语音对话助手Skyo,则是一个具备情感表达能力、快速响应能力、多语言流畅切换的智能语音对话工具。
在自然语言处理领域,该模型可以实现更加精准的语言理解和生成,提升智能助手和机器翻译等应用的性能;在图像识别领域,能够实现对复杂图像的高效识别和分析,应用于安防监控、医疗影像等领域;在语音识别领域,能够实现更加准确的语音转文字功能,提升语音交互体验。此外,该模型的推出还推动了人工智能技术的发展和应用,为用户创造更大的价值。

字节跳动开源全新AI模型LatentSync
直接从音频生成唇部动作,利用Stable Diffusion生成动态逼真的说话视频,提升视觉效果
2024年12月2日,字节跳动开源了全新AI模型LatentSync,基于Transformer的生成模型,用于生成时间序列数据的高维向量表示,这种表示能够捕捉数据的内在模式,并在此基础上实现时间序列预测。
无需任何中间运动表示,即可实现视频中人物唇部动作与音频的精准同步。与以往基于像素空间扩散或两阶段生成的唇同步方法不同,LatentSync 直接利用了 Stable Diffusion 的强大功能,能更有效地建模复杂的视听关联,LatentSync 引入了时间表示对齐 (TREPA) 技术。TREPA 利用大型自监督视频模型提取的时间表示,使生成的帧与真实帧对齐,从而增强时间一致性,同时保持唇同步的准确性。

详情链接:https://github.com/bytedance/LatentSync
微软发布Phi-4小型语言模型
140亿参数小语言AI模型Phi-4,性能比肩 GPT-4o Mini
2024年12月15日,微软在Hugging Face平台上发布了Phi-4小型语言模型,Phi-4是一个仅有140亿参数的语言模型,虽然参数规模相对较小,但在多个基准测试中展现出了卓越的性能。特别是在数学推理和编程方面,Phi-4在MATH和MGSM等具有挑战性的基准测试中得分超过80%,超越了包括Gemini Pro和GPT-4o-mini在内的多个更大规模模型。此外,在美国数学竞赛AMC的测试中,Phi-4更是达到了91.8分的平均得分,这一成绩出人意料地超过了所有参与测试的竞争对手。
Phi-4的开源是在MIT许可证下进行的,这意味着开发者可以将其用于商业应用。目前,Phi-4已在Hugging Face平台上发布,感兴趣的开发者和尝鲜者可以下载、微调和部署该AI模型。

详情链接:https://huggingface.co/microsoft/phi-4
商汤科技推出“日日新”融合大模型
文科全球第一,理科国内第一
商汤推出“日日新”融合大模型,实现原生融合模态,深度推理能力与多模态信息处理能力均大幅提升。根据国内大模型测评机构SuperCLUE最新发布的《中文大模型基准测评2024年度报告》:商汤“日日新”融合大模型以总分68.3的成绩,与DeepSeek V3一起并列国内榜首。
在实际应用场景中,相较于传统大语言模型仅支持单一文本输入的模式,“日日新”融合大模型展现出显著优势,尤其是在自动驾驶、视频交互、办公教育、金融、园区管理、工业制造等天然拥有丰富模态信息的场景中。“日日新“融合大模型能够有效满足用户对图像、视频、语音、文本等多源异构信息的综合处理与识别需求。

详细地址:https://chat.sensetime.com/
英伟达推出旨在理解现实世界的基础模型 Cosmos
旨在加速自主驾驶车辆和机器人的开发,减少对真实数据的依赖
英伟达推出可以理解现实世界的基础模型NVIDIA Cosmos,是一个世界基础模型,专注于理解和模拟物理世界,特别是在自动驾驶和机器人应用领域具有重要作用。Cosmos能够接受文本、图像或视频提示,并生成虚拟世界状态的视频输出,帮助开发人员进行AI训练和策略优化,基于Transformer架构,采用了自回归和扩散两种生成方式,并通过大规模训练(使用了9,000亿个令牌)来捕捉物理世界的复杂性。该模型还包含高级分词器和加速视频处理管线,为开发者提供了丰富的工具和框架,以构建和定制物理AI系统。 NVIDIA Cosmos的推出标志着英伟达在物理AI领域迈出了重要一步,旨在推动自动驾驶、机器人等技术的发展,并加速物理AI的广泛应用。

通义万相推2.1视频模型 大幅提升复杂运动能力
分为极速版与专业版,分别提升高效性能与表现力
1月9日,阿里云通义万相迎来重磅升级,推出万相2.1视频生成模型,在大幅度复杂运动、物理规律遵循、艺术表现等方面全面提升。根据权威评测榜单VBench的信息显示,新版通义万相登上榜首位置,超越混元、海螺AI、Gen3、Pika等国内外视频生成模型。
通义万相2.1的升级,使得生成的视频更加真实、自然,不再只是静态画面的简单堆砌。

详情链接:https://tongyi.aliyun.com/wanxiang/videoCreation
字节联合高校发布 STAR 模型
实现视频超分辨率,提升视频质量
南京大学的研究团队与字节跳动、西南大学联合推出了一项创新技术:STAR(Spatial-Temporal Augmentation with Text-to-Video Models),旨在利用文本到视频模型,实现真实世界视频的超分辨率处理。该技术结合了时空增强方法,能够有效提高低分辨率视频的质量,尤其适用于在视频分享平台上下载的低清晰度视频。
研究团队已经在 GitHub 上发布了 STAR 模型的预训练版本,包括 I2VGen-XL 和 CogVideoX-5B 两种型号,以及相关的推理代码。这些工具的推出标志着在视频处理领域的一次重要进展。

详情链接:https://github.com/NJU-PCALab/STAR
银河通用联合多机构发布GraspVLA大模型
训练数据达到了有史以来最大的数据体量:十亿帧「视觉-语言-动作」对
银河通用携手北京智源人工智能研究院(BAAI)及北京大学和香港大学的研究人员,共同发布了首个端到端具身抓取基础大模型GraspVLA,为机器人领域带来了重大突破。
该模型通过模拟人类的抓取行为,实现了对物体的精准识别和抓取,具有高度的灵活性和适应性。其价值在于为机器人领域提供了更为先进的抓取技术,能够广泛应用于仓储物流、工业自动化、服务机器人等场景。例如,在仓储物流领域,该模型可以实现对不同形状、大小和材质物体的快速识别和抓取,提高物流机器人的工作效率和准确性;在工业自动化领域,能够实现对复杂零部件的精准装配和搬运,提升生产效率和产品质量。此外,该模型的推出还推动了机器人技术的创新发展,为实现更加智能化和自动化的生产方式提供了强有力的技术支持