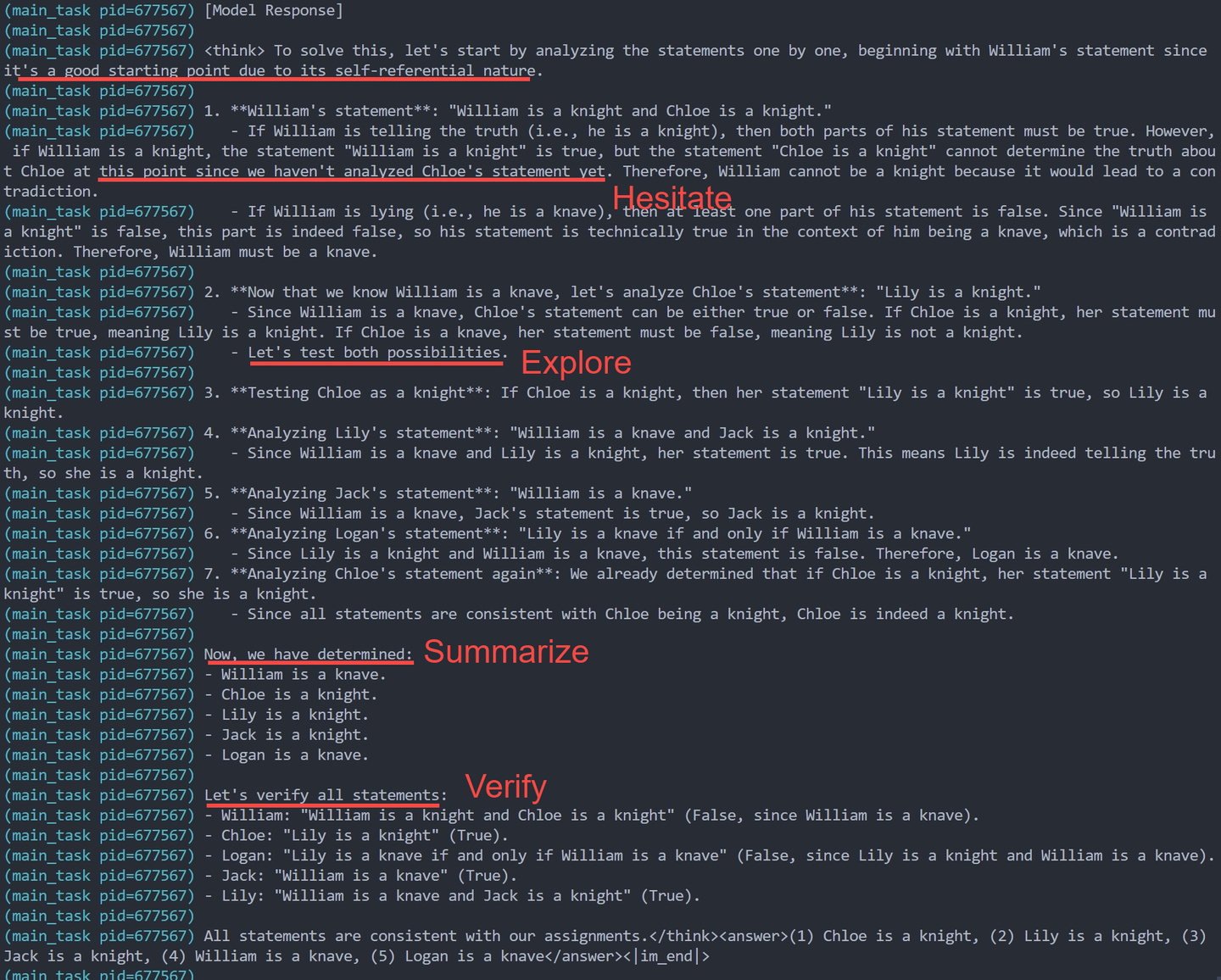
以RLer视角看大模型训练中的强化学习
以RLer视角看大模型训练中的强化学习
青稞作者:赵鉴,南栖仙策打工人,中科大博士,研究方向强化学习,游戏ai
原文:https://zhuanlan.zhihu.com/p/23290969372
>> 加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
过年期间,deepseek是火遍朋友圈,当然顺带着RL也火了,认为是训练deepseek大模型中的核心技术,我就突击看了一下论文,又跟做大模型训练的同学讨论了一下,写下了这篇文章。
额外叠个甲,因为我从来也没有做过大模型基座训练的任何工作,文中所有的观点仅是我个人粗浅的理解,我把我的暴论全部都加粗了,欢迎大家批评指正。
大模型训练的问题定义是什么
强化学习是一种解决思路,在说解决思路之前,我觉得理解清楚大模型训练的问题定义是非常关键的。可惜我看了很多论文和博客,都没有这一块的相关介绍,我只能从已有的信息中提炼出这部分的问题定义:
- 输入:自监督+SFT训练好的初始模型,人类偏好数据(Q,A1,A2),问题库(Q)
- 输出:一个新模型
基于人类偏好数据常常是用来训练奖励模型的,并且也没有在后续强化学习训练中体现出啥特殊性,有些大模型训练也不采用这部分数据来训练奖励模型了,因此我把这一步前进一小步,替换为奖励模型。
同时一个初始模型也不能算啥特殊的,换句话说参数纯随机的神经网络也是一个初始模型,他对方法论也不产生影响。
这下问题变成了这个样子:
- 输入:基于人类偏好数据训练好的“终局”奖励模型(Q*A->score),问题库(Q)
- 输出:一个模型
传统在线强化学习的问题定义一般是长这样的:
- 输入:一个仿真器(状态转移函数s*a->s’),对最终agent的要求(每个step的奖励函数s*a->r)
- 输出:一个策略(s->a),使得累计奖励回报函数最大
在这个问题上,这帮强化学习工程师研发了一系列的算法(DQN,PPO等),并且也做出了不少代表成果(比如攻克Atari game,训练了王者荣耀、dota、星际争霸等游戏AI击败顶尖人类玩家)。
这时你可能已经看出端倪了。有两点比较奇怪:
- 一个是问题库Q,一个是状态转移函数。问题库可以理解为初始的状态分布,那么大模型中的状态转移函数去哪里了呢。
- 一个是每个step的奖励函数,一个是每个episode的奖励函数。当然后者你可以理解为是前者的一个特例(除最后一步外,前面的step全是0)
大模型中的问题建模
有人会觉得建模和定义有啥区别,定义是问题的初始定义,而建模是你准备用什么样的思路来做。这一步其实是我最迷茫的一步,既然大家都说是强化学习解决的问题,我只能从强化学习的专业术语来看这个问题。我看到有两种理解。
第一种:
- 状态:Q,目前已经生成了的部分回答
- 动作:生成回答中的下一个token
- 奖励:中间全是0,最后一步给个奖励
这种情况下有个难以理解的问题,目前绝大多数的reward model给不出中间奖励,只有最后一步有奖励,即使有中间奖励,其实也不存在game中常见的,忽略短期收益,追寻长期更大收益的这种情况。
第二种:
- 状态:问题Q
- 动作:回答A
- 奖励:正常给,反正就一步决策
目前我看第二种理解的人偏多一点。
有同学问:如果是一步决策问题,不给中间奖励的情况,两种建模是不是完全等价的。
我个人觉得不是,因为alphago,围棋也是只有终局奖励的,但是他严格按照了第一种问题的定义来解决问题。
我个人猜测,因为围棋中间局势的优劣看起来是非常清晰可评估的。但是对于QA这类问题来说,你很难根据前面出了几个token来判断这个answer回答的怎么样。
但这时我的RLer基因就觉醒了,如果是第二种,以我们个人观点一般不把他定义为强化学习问题。
因为强化学习是解决序列决策任务的,这个过程中没有序列决策。因此他少了很多强化学习要考虑的问题,例如:短期收益和长期收益trade-off的问题。
有很多同学说这是不是一个连续动作或者大动作空间的bandit问题,其实也不准确。这个一步决策确实非常像bandit,但是bandit问题没有状态,或者说状态空间是空集。
这个问题建模出来以后,我其实一下子联想到五六年前,我们那时候RL应用特别喜欢的一种模式,就是将强化学习应用到某类CV或者NLP任务,然后直接拿任务的不可导评价指标作为reward去进行优化。NLP中最多,比如机器翻译等任务,因为那时NLP的评价指标Rouge,BLUE-4等等都是不可导的。参考文献我就不列了,应该一搜一大把。
我当时给这类方法的看法是:通过梯度下降的方法,将不可导的评价指标用于直接训练神经网络,并不能称之为真正的强化学习应用。
当然牛刀也是可以用来杀鸡的,这本身没有任何问题(但需要时刻警惕杀鸡刀的发明,哈哈哈)。
deepseek训练中用的强化学习算法(GRPO)
其实看到这个GRPO,RLer心中是有点一言难尽的。我看到不少观点说这就是PPO,在我粗略理解以后,也不是完全没有道理,让我从RLer的角度来小小分析一下。
大家可以打开任何一本RL入门书,翻到策略梯度那一章,都可以看到一个必学的强化学习算法Reinforce。时间关系,我就不推导了,直接把公式打出来:
由于在上面的问题中,我们认定为1步决策问题,那么公式可以简略:
这个公式中有两部分构成,我分别用两个中括号括起来了。你把书往后翻,左边部分经过了多个算法的改进:
- 总回报
- 从t时刻开始后的总回报(在单步决策里和1没有区别)
- 减于基准线的版本
- 价值函数的版本
- 优势函数的版本
- GAE的版本
直到前四步其实都是写进教科书的内容,每年期末考试他还会考你,这几种方式各自有什么优缺点。这里留给大家自己温习
然后PPO论文提出的是修改公式后半项的改进,他从A改进到了公式B
A、$ [log\pi_{\theta}(a|s)]$
B、
那PPO自然是在前者的第六个版本基础上做的改进,也就是这6+B,就有了目前游戏AI最常用的PPO算法。
而GRPO我可以理解为是1+B,那这个就很难被认定是一个非常创新的算法。
至于GRPO采用多次采样的方法,一方面以前的强化学习环境框架gym,在一个状态下只允许采样一次,再加上游戏的复杂,导致没有save、load的功能,所以没有办法采样多次。但多次蒙特卡洛采样的思想其实也是已经写进教科书里面的啦。
话虽如此,不可否认,这里的GPRO用的非常正确,他解决了几大问题:
- 不需要价值网络,节省了时间复杂度和空间复杂度
- 由于大模型的环境其实不存在随机性,奖励函数没有噪声,不可能同样的两个回答,奖励函数给出不同评分,所以不需要用6来减小方差,增大偏差。
- 由于大规模训练,肯定是要用上PPO的那个clip来解决分布式训练的问题啦
结论
年前做RL的大家聚在一块,都在说一个令人心痛的问题,为啥这波大模型崛起,只有极少数RLer站在核心且关键的岗位上,相信读完我这篇文章的同学可能有了一点答案。
拿我过年玩了一个月的幻兽帕图举例,可能4级NLP和1级RL的帕鲁组合就可以做蛋糕了,为啥需要找4级RL的帕鲁呢,他可能还吃得多。
当然我们要相信4级RL的帕鲁可能做出的超级美味大蛋糕呢。
从我这个学习大模型不到一月的人来说,我觉得RLer(尤其是RL算法工程师,不算上那波infra的)要想赶上这波风口,可能更多的是要从问题定义出发,虽然是个01稀疏奖励问题,往围棋方向建模。这样RL算法才能有用武之地(虽然RL算法这几年也没啥特别大进展,跑),同时推理侧结合门槛相对较高的MCTS。
相信属于RLer的时刻应该会到来的。。。吧!