5分钟极减阅读kaiming团队无向量量化的自回归图像生成模型

5分钟极减阅读kaiming团队无向量量化的自回归图像生成模型
青稞减论 (ReductTheory):传递人工智能算法科普教育的减约理解,提升信息效率及认知维度。
大家好,这里是减论为您带来的5分钟极减阅读《Autoregressive Image Generation without Vector Quantization》,即无向量量化的自回归图像生成模型
1 | Paper:Autoregressive Image Generation without Vector Quantization |
众所周知,kaiming出品,必属精品。今天,让我们花5分钟时间来领略一下kaiming团队在图像自回归生成领域的一大力作:MAR + Diffusion Loss。一作是li tianhong博士。
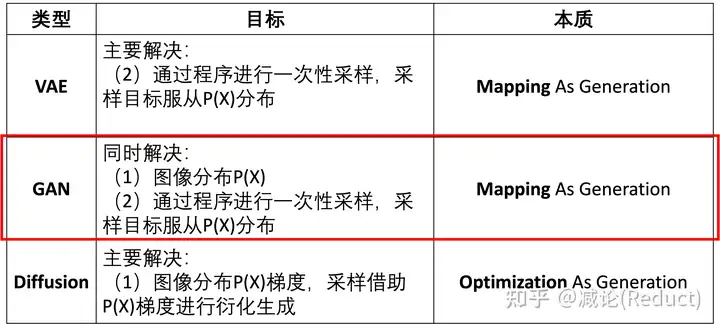
这篇工作的故事线是希望移除自回归式的图像生成模型(Autoregressive Image Generation,AIG)对向量量化(vector quantization,VQ)的依赖,也就是人们常说的codebook,有限向量码表。

AIG为什么会对codebook有所依赖?究其原因是来自自回归大语言模型范式的惯性:语言模型天然自有codebook,即“categorical, discrete”的单词库,有多少词就对应了有多大容量的codebook。
所以,大语言模型的自回归范式在迁移到图像生成领域时,现有的研究默认都延续了该设定,会先利用各种VQ的技术手段对图像进行离散编码,形成图像单词的概念以便于仿照语言模型进行自回归建模。
那么kaiming团队为什么要做移除AIG对VQ依赖这件事情

原文的说法是:本质上来讲没必要。
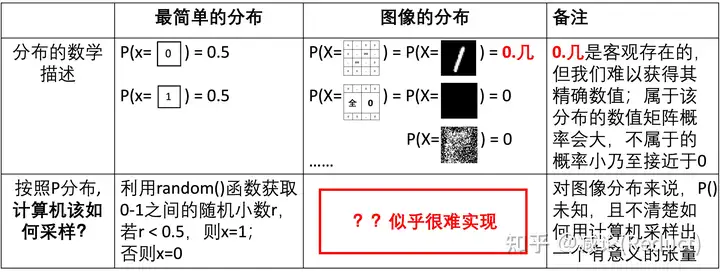
3.1节具体给出了分析,总结如上表所示。
如原文所述,究其本质而言,能完成自回归建模的关键并不在于token x的表示是离散还是连续,而在于该条件概率分布p(x|z)可否训练并能采样。使用额外的codebook将p(x|z)简化为类别概率分布CPD是一种常规途径基本操作,但实际上我们完全可以借助Diffusion的思想进行建模训练并采样,具体类比的细节如表中所示。
具体怎么做
首先,原文采用了(Latent Diffusion Model,LDM)中连续化的Tokenizer先对图像进行连续的向量表征(KL-16 version),之后所有的操作均在该连续的向量表征X下进行。

针对上述连续向量X进行Autoregressive Modelling,原文并没有采用语言模型中常用的casual attention模式,而是一如既往参考了kaiming MAE中的bidirectional attention + 随机mask token的模式,如图(b)所示,在文中也被称为Generalized Autoregressive Modelling的一种。

实操过程中,在基本维持性能的前提下,为了进一步提升模型运行效率,原文选择了下图中的(c)方法,在一个step能够一次预测多个连续数值token,并且预测对象的顺序是完全随机的。

这些预测的连续数值Token作为condition z,被用于送入diffusion MLP中(如下图所示),进行DDIM式的采样获取连续表征x。随着自回归的进行,连续表征x被不断采样并最终覆盖全图获得X,最终X利用Tokenizer的decoder恢复出完整的图像。

有一点细节值得注意,Diffusion Model在其中扮演了一个带参数的Loss组件的角色,这带来了两点性质:
- 1)它是会跟着自回归模型本身共同优化的,它的梯度会传导到自回归模型主干;
- 2)作为Loss组件,它可以被设计地很轻量,在原文中仅仅采用一个2M的小型MLP就可以获得极具竞争力的结果。
训练过程原论文给的比较简单且粗糙,大意是随机掩码加Diffusion Loss对掩码进行预测。我们简单绘制了一个便于理解的示意图,实际情况中对应的图像块的位置需要替换为其编码好的连续数值向量。测试流程相对更加清晰:整个测试流程和MaskGIT非常类似,从掩码比例为1.0开始到0.0采用cosine schedule,并且全程采用随机的掩码采样生成,生成流程的示意图如下所示(测试流程选自MaskGIT论文图片):

性能效果
如下图所示,MAR + Diffusion Loss主打一个快且好,原文的说法是:our method can generate at a rate of < 0.3 second per image with a strong FID of < 2.0。单独针对Diffusion Loss的ablation study自然是非常有效,这里就不放了,只展示一下SOTA秀肌肉的结果,证明了其scale up的能力。

一些扩展思考
- 原文可以视为从建模all token分布的Diffusion过程进行解耦拆解:用autoregression建模token z之间的关系;将z作为条件用超轻量的diffusion建模单个token x分布,使得整体的复杂度大大降低。一个简单的示意图来说明两者关系:

- 正如原文所展望的那样,MAR + Diffusion Loss方法展现出了非常惊人的效率和scale up的能力,它或许也将引领下一代文生图或者文生视频等诸多现象级应用的技术基座(kaiming团队难得一见的没有开源代码和模型,难道是正在悄悄搓下一代文生图的大力丸子?)。
- 更大胆一些,MAR + Diffusion Loss高效率地打通了端到端的训练链路,甚至为去Tokenizer化也提供了一种可能性:我们能否直接将raw pixel的patch块视为token x?
- 当然,还有很多常规的改进或者改造,例如,类比于VAR,Masked AR过程可否建模为一个多尺度由粗到精的预测过程?作为一个通用的条件概率建模组件Diffusion Loss,它是否在其他任务或者领域有着巧妙的应用?