5分钟极减阅读CVPR24 best paper《Generative Image Dynamics》
5分钟极减阅读CVPR24 best paper《Generative Image Dynamics》
青稞减论 (ReductTheory):传递人工智能算法科普教育的减约理解,提升信息效率及认知维度。
大家好,这里是减论为您带来的5分钟极减阅读CVPR24 best paper《Generative Image Dynamics》,生成式图像动态。
1 | Paper:Generative Image Dynamics |
CVPR今年2篇best paper都给了图像生成模型,可见社区对生产式模型的关注度还是空前高涨的。这篇文章《Generative Image Dynamics》GID重点解决的是某种特定类型的动态视频的生成:图像全局的自然摇曳,例如下图中由风引起的树叶、花朵、灯笼、烛火的摆动,甚至是猫咪的呼吸导致的腹部起伏。

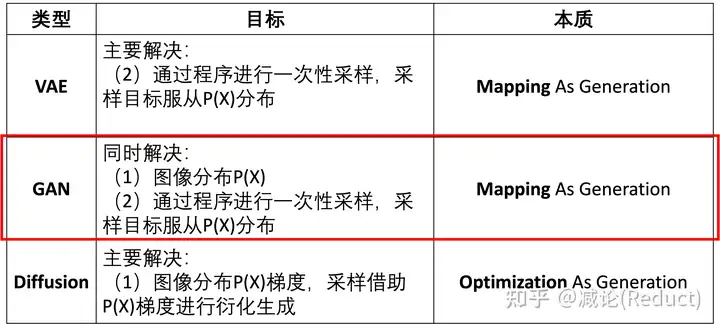
原文本质上是对《Image-Space Modal Bases for Plausible Manipulation of Objects in Video》[0]这篇2015年TOG的深度学习化改造。原文GID和这篇TOG文章从效果上做了几乎一致的事情,形成自然摇曳的目标(或图像),用户可编辑其摇动方向和力度。所以两者建模的物理数据结构(Spectral Volume,本质上可以理解为光流轨迹的傅里叶频域系数表示)是一致的,不同的点在于GID的组件全部深度学习化,借助了现有成熟的生成式模型技术。
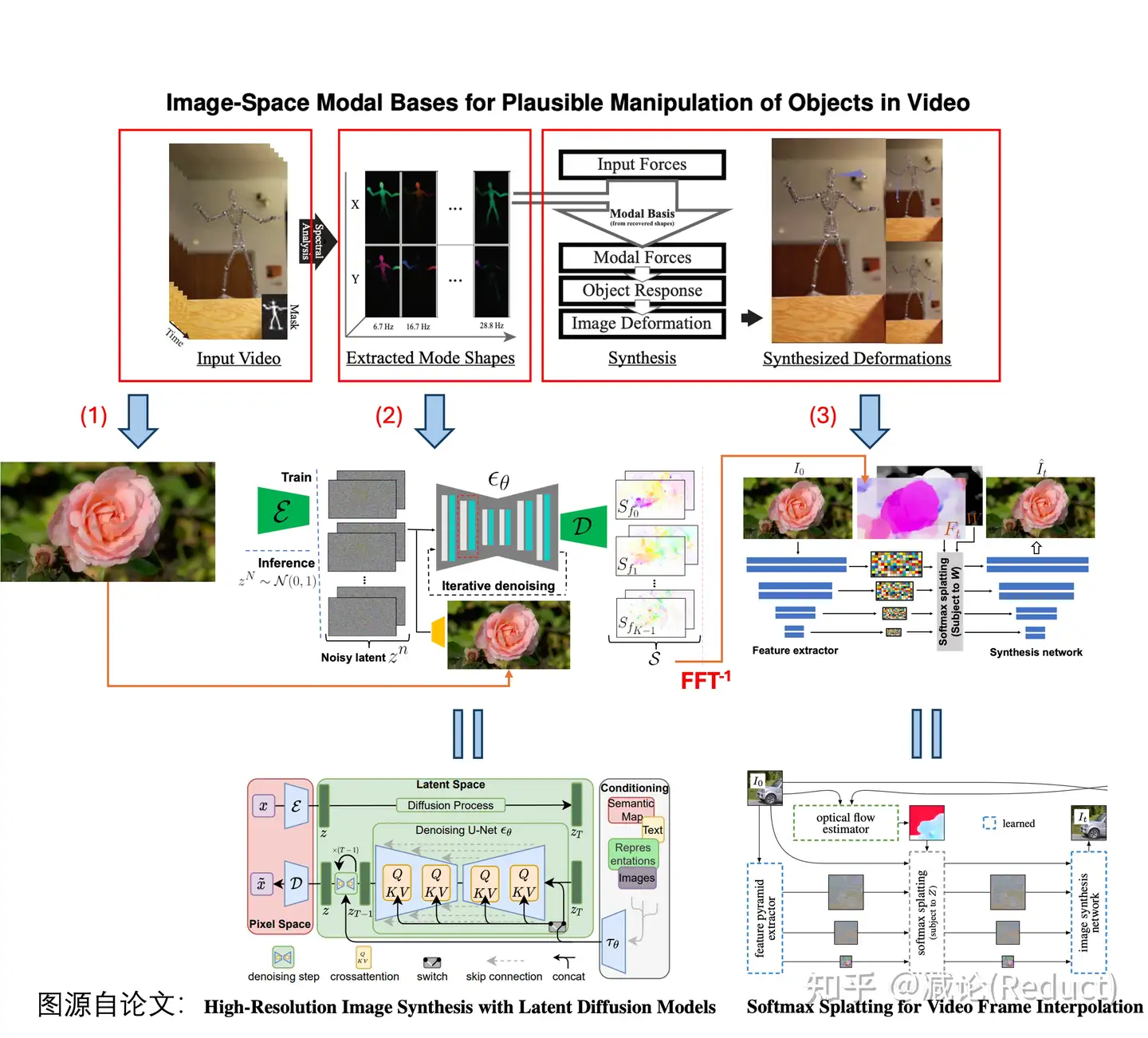
如上图所示,GID原文具体改造[0]中有3点:
(1) TOG文章[0]需要从视频输入中分析提取出Spectral Volume,而GID输入可以变为单张图片来预测Spectral Volume;
(2) 将单张图像作为condition,利用Latent Diffusion Model(LDM)[1]强大的生成能力直接预测出Spectral Volume;
(3) 将Spectral Volume通过傅里叶逆变换FFT^(-1)获取光流场,采用Softmax Splatting技术[2]借助网络来生成未来每一帧的图像。
设计思路
接下来,我们采用庖丁解牛的方式,从最原始的视频生成一步步导出原文的设计思路(当然这可能和原作者的思考顺序不同,但笔者认为这样的思考更具灵感和启发性)。
首先我们知道任务是某种特定类型的动态视频的生成:图像全局的自然摇曳。不管有多特殊,它依然是一个视频生成任务;一个最粗暴的想法就是直接端到端生成:采集大量该类型的视频数据,端到端训个Image to Video(I2V)模型即可。
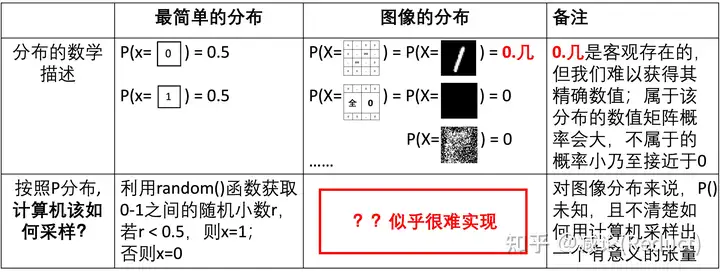
当然,这样黑盒的模型完全丧失了我们对视频中运动物理的认知和控制。如果我们需要加入一点点运动方向的可控性或者可解释性,我们通常会引入光流:光流本身的定义是视频两帧之间像素的移动。有了光流,我们可以从物理上简单地把控和认知视频运动,当然其也可以作为condition成为生成视频的一种手段,正如《Softmax Splatting for Video Frame Interpolation》[2]工作中所展示的:
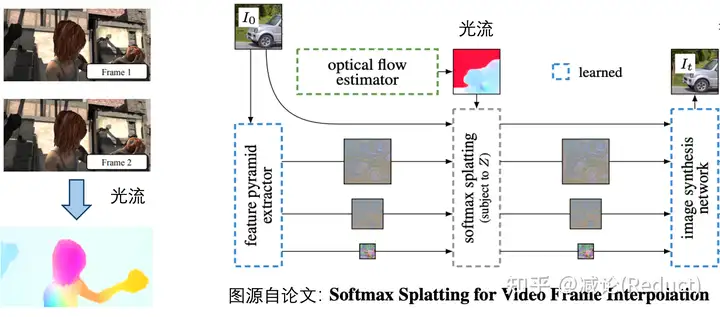
当然,如果仅仅采用光流来进行对视频中物理运动的把控,依然存在如下的问题:
1) 复杂度高。如果我们生成T帧的视频,需要生成T帧Dense的全图光流估计,计算复杂度非常高;
2) 可控性弱。如果我们要人为修改其中的运动,需要对T帧Dense的光流图进行时间轴上一致性且合理的改动,这样的改动相对比较困难;
于是,我们需要一个更加High-Level的可控量,即2015年TOG工作《Image-Space Modal Bases for Plausible Manipulation of Objects in Video》中所提出的Image-Space Modal Bases,在GID原文中也可以称为Spectral Volume。这个原理其实很简单,就是将每个像素在空间域的移动轨迹,通过傅里叶变换变化到频域,用少量的傅里叶系数来近似表征。之所以能够这么做是和该任务的特殊性质有一定关联:该任务(图像全局的自然摇曳)中像素的移动都是略带周期感的、微量性的,这就为少量傅里叶系数来表示整个运动轨迹带来了可能性,如图所示:

上图中的曲线图比较有趣,是一个时空图,纵向代表时间变化,横向代表左图中的蓝色横线对应的像素:从该时空图中大体能够感知到图像摇曳的情况,的确是一种微量的振动式运动。
经过建模,网络的回归目标就由原来的光流(T个全图位移量),变成了少量的傅里叶系数(4K个全图系数,文中K取16)表示的数据结构,随之而来的就是两大好处:
1) 复杂度低。理论上有 K << T,而T作为视频长度可以非常长,文中K默认取16;
2) 可控性强。我们可以很好地操控少量的傅里叶系数来控制运动的幅度、方向等等,该操控是贯穿整个视频运动的,视频一致性、稳定性的保持自然也是非常良好的。
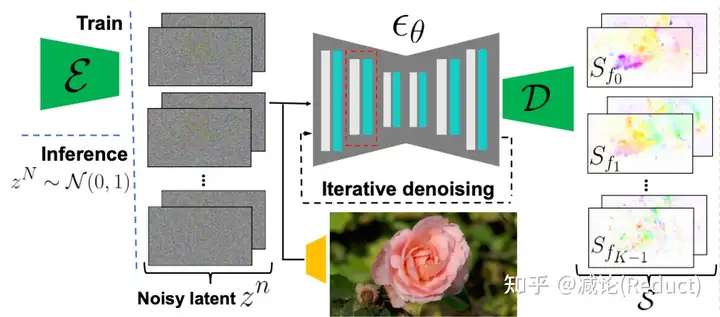
最后,整个技术就剩最后一个拼图了:怎么得到这些傅里叶系数呢?那么作者掏出了Diffusion大法LDM:Latent Diffusion Model,如下图所示,通过单张图片作为condition,将这些4K个全图傅里叶系数去噪生成出来。具体训练过程相对简单,作者是收集一些类似运动的视频,对其进行傅里叶系数标签的计算来进行LDM的训练。
总结
好了,庖丁解牛完毕,进入总结。整体上来看,今年的这篇best paper的确存在多个现有工作组合的痕迹,但这样的组合的确也是需要一定功底的:对问题特殊性的探查、对多种现有技术能力的掌握、对任务的选择和可行性的预见。
那么从技术层面我们能有哪些遐想呢?笔者认为,这篇工作的成功,或许为运动可控型视频生成提供了一种有趣的途径:我们是否可以将傅里叶系数调整为更一般的曲线系数(例如高阶贝塞尔曲线),来建模更加复杂和任意的运动?如此一来,我们或许就能更好的控制更加一般化的视频生成,例如让图中的人从A位置自然地走到B位置。
备注:本文对某些组件的细节没有深入,例如Softmax Splatting,还有LDM中作者提出的Frequency Attention等,但不影响对本工作核心的理解。需要了解细节实现的读者需要自行深入对应章节或相关论文。
参考
1 | [0] Davis A, Chen J G, Durand F. Image-space modal bases for plausible manipulation of objects in video[J]. ACM Transactions on Graphics (TOG), 2015, 34(6): 1-7. |