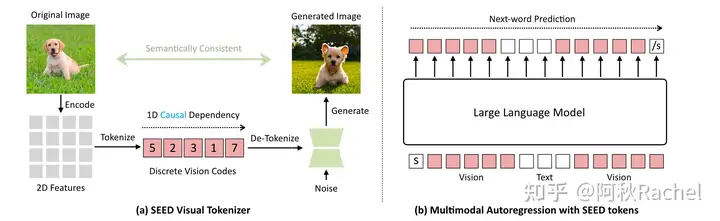
更适合 flash attenion 体质的长上下文训练方案

更适合 flash attenion 体质的长上下文训练方案
青稞作者:朱小霖,SDE @Tencent WeChat AI, focusing on MLSys
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://zhuanlan.zhihu.com/p/718486708
年初的时候,我尝试去结合了 ring attention 和 flash attention,并设计了 zigzag ring attention:
理论上来看,zigzag ring attention 基本做到了线性扩展 context length 的最优解,即:
- 每张卡上的显存占用不随 context length 扩展;
- 每张卡基本平分计算与通信;
- 通信可以和计算 overlap。
然而,当我去把 zigzag ring attention 和 flash attention 结合的时候,遇到了如下的现实问题:
精度损失
- 因为 ring attention 需要对在 flash attention 的输出进行迭代计算,我们要把 flash attention 输出的 bf16 结果相加。而 bf16 作为一种有效位数极少的数据格式,随便就能搞出来一个 1e-3 级别的误差。
- 更麻烦的是,让 flash attention 返回 fp32 结果这件事对 flash attention 的源码改动会比较大。
varlen 版本又难用,又慢
- 这是因为我们需要把 varlen 数据中的每一条都拆分为 2 * world_size 份,使得每条数据都需要 padding,rotary embedding 也需要针对性做改变;而速度上,这种拆分会增加一些拷贝,而且由于序列变短了,kernel 并行度会降低,效率也降低了。
通信上大量使用 p2p,而不是更高效的集合通信
那么有什么办法能适当地牺牲一些理论性能,而优化上述的几个问题呢?
我发现 llama3 团队在技术报告中提出了这样的方案:
Different from existing CP implementations that overlap communication and computation in a ring-like structure (Liu et al., 2023a), our CP implementation adopts an all-gather based method where we first all-gather the key (K) and value (V) tensors, and then compute attention output for the local query (Q) tensor chunk. Although the all-gather communication latency is exposed in the critical path, we still adopt this approach for two main reasons: (1) it is easier and more flexible to support different types of attention masks in all-gather based CP attention, such as the document mask; and (2) the exposed all-gather latency is small as the communicated K and V tensors are much smaller than Q tensor due to the use of GQA (Ainslie et al., 2023).
简单来说,就是先 all gather 一下 kv,然后让每张卡上自己的 q 和全部的 kv 做计算。这样很显然解决了 p2p 通信不如 cc 的问题,而且因为只会调用一次计算 kernel 了,也就基本解决了精度问题。但是因为要 all gather 所有的 kv,所以显存占用会多一些。
那么我们是否可以适当优化这个方案,一方面尽量降低一些显存占用,另一方面让它适配 flash attention 的 varlen 接口,从而解决 ring attention 与 varlen 的错配问题呢?
首先看显存占用。很容易发现,由于在 attention 计算中,每个 head 是分开计算的,我们可以每次只 all gather 一个 head。这样的话,正向的增加的显存占用也就只有 4 * seq_len * head_dim (这里 4 中 2 是 k 和 v,2 是 bf16),那么取 1M context length,head_dim 128,也就是 512MB,对于 40GB 或者 80GB 的 GPU,也不算太过分,何况大多数情况下,大家都训不到 1M。
而且,当改成每次算 1 个 head,我们就可以把下一个 head 的 all gather 操作和这一个 head 的计算 overlap,也就又缩小了通信时间(不过这需要多一倍的显存做 buffer,也算是用空间换时间了)。
再来看 varlen。可以发现,当使用这个方案的时候,我们不再需要单独切分每一条数据,而是直接切分整条数据,并根据 q 的切分去匹配对应的 kv 就行了。
具体来说,当我们直接去切分全部数据的时候,可能会遇到如下的 3 种情况:
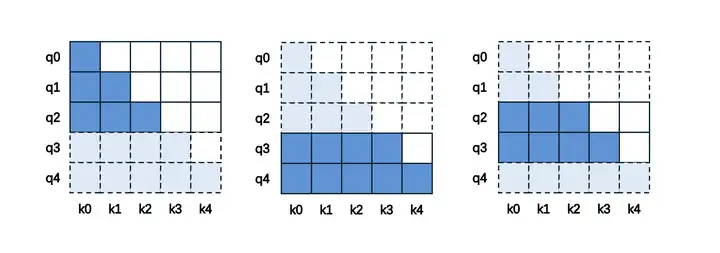
- 如果只留下了 q 的前半部分,如左图的 q0~q2,那么只需要匹配等长的前半段 k,即 k0~k2;
- 如果只留下了 q 的后半部分,如中图的 q3~q4,那么需要匹配全部的 k,即 k0~k4;
- 如果是留下来中间的一段,如右图的 q2~q3,那么需要结合 1 与 2,留到最后一个位置的 q 对应的 k,也就是 k0~k3。
flash attention 的 varlen 接口也提供了对应的支持:在 causal=True 时,如果 q 的长度小于 k,就会采用中图(或右图)的这种 mask。所以我们只需要根据这个逻辑来计算合适的 cu_seqlens(flash attention 中 varlen 结构需要传入的 cumsum)就行了。
举例来说,假如我们有长度为 3、6、3、4 的一组 varlen 数据,他们会被拼成一个全长 16 的数据,对应的原始 cu_seqlens 会是 [0,3,9,12,16] 。如果我们需要把这段数据切分到 4 张卡上,则:
- gpu0 会分到 [0, 4) 的 q,也就是完整的数据 0 的全部和数据 1 的前半部分,即 cu_seqlens_q 是 [0, 3, 4]。考虑 kv 时,因为只有前半部分,所以匹配到等长,取全部 kv 中的 [0, 4),构造 cu_seqlens_k 为 [0, 3, 4];
- gpu1 会分到 [4, 8) 的 q,也就是数据 1 的中段,即 cu_seqlens_q 是 [0, 4]。 考虑 kv 时,因为是中段,要匹配到最后的 q 对应的 k,所以需要取到数据 1 长度为 5 的地方,即取全部 kv 中的 [3, 8),构造 cu_seqlens_k 为 [0, 5];
- gpu2 会分到 [8, 12) 的 q,也就是数据 1 的后半部分与完整的数据 2,即 cu_seqlens_q 是 [0, 1, 4]。 考虑 kv 时,因为是后段,所以需要取全部的 k,即取全部 kv 中的 [3, 12),构造 cu_seqlens_k 为 [0, 6, 9];
- gpu3 会分到 [12, 16) 的 q, 也就是完整的数据 2,那么很简单,cu_seqlens_q 为 [0, 4],kv 也取全部 kv 的 [12, 16),cu_seqlens_k 也为 [0, 4]。
把上述的逻辑总结成代码,我们就有了个可以完整地做切分,不需要内部做 padding 或者拆每条数据的方案了。(注意 cu_seqlens 和 kv 的 slice 都可以在数据处理的时候准备好,一次正向 + 反向计算中共享)。
causal=False 的场景会更简单一些,只需要把每张卡上的 q 对应的所有完整的 kv 取出来就行了。这里就不赘述了。
到这里,我们就有了一个显存占用还能接受,对精度与 varlen 很友好的长上下文方案.....的正向部分了。还需要稍微操心一下反向的问题。
反向的实现很简单,每张卡算出全部 kv 在当前 head 上的梯度后,reduce scatter 一下就行。不过因为还是需要做 reduce scatter,所以 kv 的梯度还是会有一点精度问题。另外需要注意,反向除去一个 head 的 kv 的 buffer,还需要 dk 与 dv 的 buffer,所以额外的显存占用需要乘 2。
说了这么多,最后是 show me the code 环节,我在 ring-flash-attention 这个项目里实现了这个方案,粗暴地称为 llama3_flash_attn_varlen_func 了,想用一用或者看看实现细节的朋友可以看这里:
1 | https://github.com/zhuzilin/ring-flash-attention/blob/main/ring_flash_attn/llama3_flash_attn_varlen.py |
目前这个实现中正向的误差是 0,反向中 dq 误差也非常小(非零猜测是 deterministic=False 的锅),dk 与 dv 差不多是其他 ring attention 实现的量级。考虑到不少人用这里的 ring attention 接口也成功训了模型,相信这个误差量级不至于不能用~
P.S. 还没实现通信 overlap 的部分,有兴趣的朋友欢迎提 PR 呀~