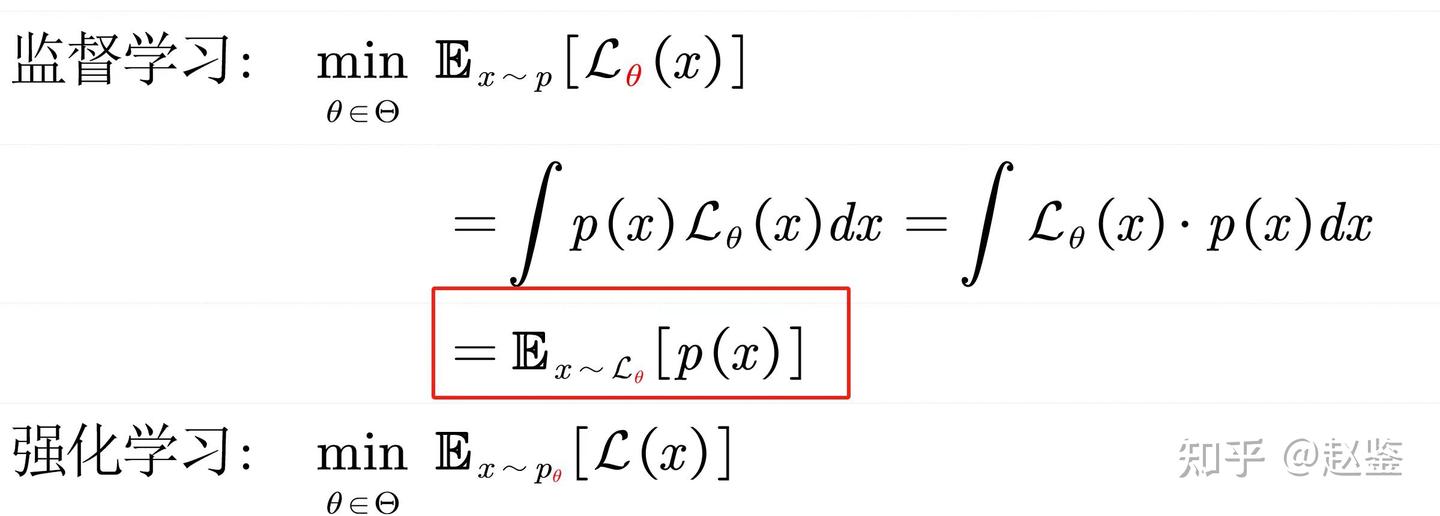如何正确复现 Instruct GPT / RLHF?
如何正确复现 Instruct GPT / RLHF?
青稞作者:初七123334
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://www.zhihu.com/people/chu-qi-6-41
前言
最近几个月随着 OpenAI Instruct GPT/ChatGPT/Anthropic Claude/文心一言等大语言模型的火爆,GitHub上开源了不少 ChatGPT复现方案。总体来说这些复现库分为两类:
- 基于 ChatGPT API 接口抓取指令数据基于开源大模型权重做指令微调,比如基于 LLaMA 微调的 Alpaca,基于 Bloomz 微调的 BELLE。这类微调模型因为直接“蒸馏”ChatGPT的"标准答案",所以效果通常还不错。
- 实现完整的 SFT/RLHF 流程,以供用户自己从头开发自己的模型。这些库主要有 PaLM-rlhf-pytorch,ColossalAI-Chat,DeepSpeed-Chat,TRLX, Huggingface TRL。
但是在试用过这些框架后,笔者发现这些实现中有各种各样的bug导致训练不稳定无法收敛。本文基于对大量RLHF相关论文和开源库的调研,旨在讨论如何正确的复现一个 RLHF 的训练流程,但不涉及数据集收集清洗准备。
回顾 GPT/Instruct GPT
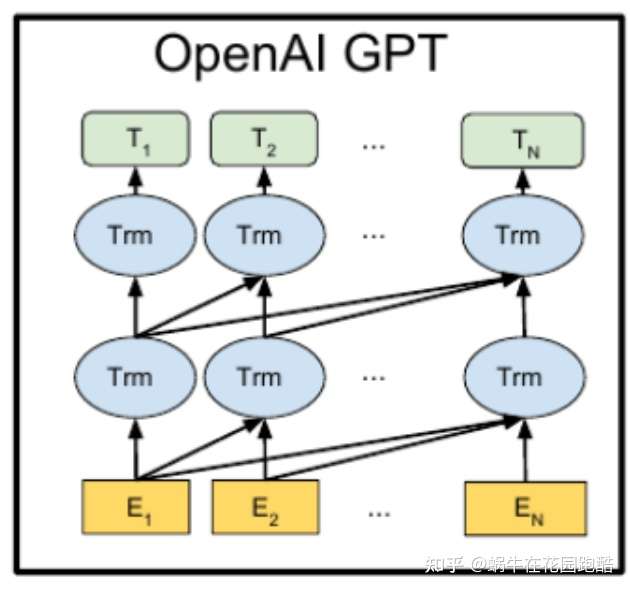
GPT
如下图所示,GPT是一种自回归的语言模型,即利用句子前面的单词预测后面的单词。用大量的语料通过预测下一个单词的方式预训练一个GPT模型,便可的得到一个初步可用的语言模型。

Instruct GPT
仅仅通过预训练的的GPT并不会遵循人类的意图回答问题,而且喜欢胡说八道乱填空说脏话。此时我们可以通过 监督学习 (SFT)/RLHF来进一步 finetune模型。
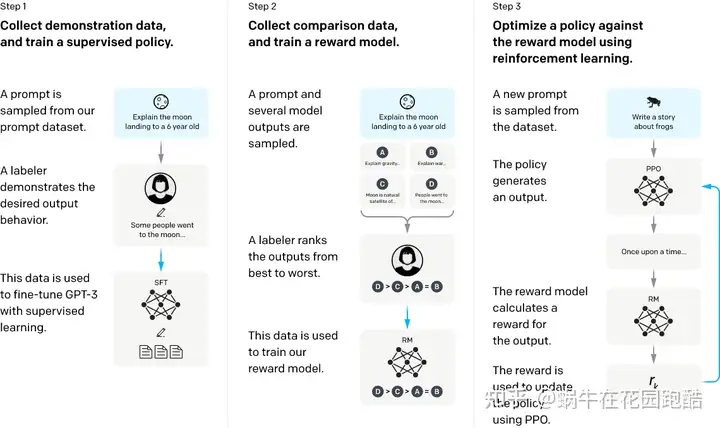
如下图所示,Instruct GPT的训练流程主要分为三个阶段:
分别为 监督学习(SFT),奖励模型训练,PPO 训练;后面两个阶段便是我们通常说的 RLHF。
如何训练一个奖励模型
Instruct GPT 中使用 pair-wise 排序损失函数来训练一个 Reward Model,如下

EOS_token
从实现细节上来说,我们假定使用 GPT 模型作为这个奖励模型的基础架构,那么我们有多种思路来预测一个对话的奖励值。
- 对所有token上预测reward取平均
- 在最后一个token,即EOS_token上预测reward
这里我们倾向于方式2,因为对于GPT这种模型,只有EOS_token的输出才能看完整句话给出一个整体的评价。这种方式也在 Anthropic 的相关论文中被使用。
如何进行 PPO 训练
MDP
对于一个对话模型,我们可以以两种不同的角度将其建模为强化学习问题。
第一种即 Token-level MDP,简单地说每个单词都作为一个独立动作,将 GPT 模型的自回归预测单词的过程建模为一个长度等于句子长度的 MDP 问题。这种场景下对应于RL中的Single-agent问题,下面是严格的数学定义:

第二种可以称为 Multi-agent MDP,即将GPT模型的输出一整句话为建模为多个智能体,即Multi-agent问题,每个输出的单词都是一个独立的智能体。这场情况下,我们只有一个长度为1 的Multi-agent MDP。即状态等于 x,动作等于 y (注意y是一个动作序列)。
TRLX/DeepspeedChat等方案使用Token-level MDP,而ColossalAI Chat/PaLM-rlhf-pytorch使用Multi-agent的建模策略。这里我们倾向于使用第一种,即Token-level MDP。理由是: - OpenAI 早期开源的 RLHF 实现均使用 Token-level MDP; - 大量的论文比如 ILQL/RL4LMs 也是使用Token-level MDP; - Multi-agent 问题的求解目前仍处于学术研究状态,并不像Single-agent那么成熟。
从PPO的实现细节上来看,Token-level MDP 的 Critic 网络输出 Value 应该和 Actor 中输出单词一一对应,等价于Single agent 的PPO 算法,并且用GAE来估计advantage;而 Multi-agent MDP 只需要用一个 Centralized Critic 输出一个共享的 Value,对应于 MARL中的 MAPPO 算法,由于Multi-agent MDP只有1步就结束了,不需要用GAE估计advantage。
PPO-ptx
Instruct GPT 中的 PPO-ptx 损失函数分为三部分,第一项为 Reward 模型给出的奖励,第二项为 KL reward 用于约束当前策略和初始策略(SFT训练后的策略)的距离,第三项为 pretrain loss (PTX loss),用于避免策略遗忘预训练阶段学习到的知识。

KL Reward
第二项的 KL reward前面有一个系数 beta,从实际训练的体验来说 beta的设置非常重要,可以有效避免策略走的太远(走太远容易导致策略过拟合和坍塌),这里beta的设定通常要结合target KL的设定,即我们可以通过实验确定KL变化多大模型的表现比较好,然后根据这个 target KL来决定 beta的大小,但是这种方式通常需要大量的实验比较。
不过我们可以从 OpenAI的早期论文中找到一种根据 KL_target 自适应调节 beta的算法,这个方法已经被 TRLX/TRL实现。

PTX Loss
最后一项是预训练的 Loss,同样这一项有一个系数 gamma,InstructGPT 种将 gamma设为 27.8,但在我的实验经历中,通常这一项应结合 policy loss 和 pretrain loss 的大小综合设定。在我的实验中,gamma < 1 模型才能比较好的收敛。
- Reward Normalization
在 PPO 的训练种,我们通常会使用 reward normalization 以及 value normalization 等类似技术,我们发现在 RLHF 的训练中 reward normalization 非常有助于训练的稳定性,毕竟我们的 reward 不像在游戏环境中那么规则,而是通过一个模型学出来的中间层输出(这就意味着输出范围可能会很大)。
- Distributed Advantage Normalization
同样 Advantage Normalization 也是PPO训练种常用的稳定训练的技术,我们在使用 DeepSpeed 等类似 DDP 的训练手段时应注意做全局样本的 Advantage Normalization,而不是某个DDP进程只针对自己的样本做归一化。这一点目前的 RLHF 开源框架都没有充分考虑进来。
最后基于上面的分析和改进,笔者终于在A100上稳定的训练了自己的RLHF模型~
RLHF 起到了什么作用?
最后我们简单分析一下RLHF到底在LLM训练中起到了什么作用,通过对一些资料的分析,我想一下几个点比较重要:
- 有一些LLM需要的目标函数是难以通过规则定义的,比如说什么是“无害性”,“有帮助性”,如果我们希望模型最后具有这些好的特性,就需要制定这样的训练目标函数,而用人类的偏好学习一个reward model再用RL来训练,就自然的可以将这些特性融合到LLM里面。
- RLHF可以泛化,在SFT阶段,人类的高质量样本确实很快速让模型align人类的意图,但是这些人类编写的样本始终是有限的。而对于RL,我们只要一个足够好的reward model 结合 RL的探索特性,就等于我们能有无穷的样本对模型 finetune(注意提示词 prompts是有限的,但RL的samples是无限的)。
- 如果RM质量比较好,RLHF可以通过RL的探索特性找到比SFT更好的解 (即reward 比 SFT 样本更高的解)。
最近 OpenAI 科学家 John Schulman 对 RLHF的作用提出了一些看法
多样性角度
对于SL,模型只要稍微偏移答案就会收到惩罚,而RL对于多个回答可能有同样的reward,这和人类的行为是类似的
负反馈角度
监督学习里只有正反馈,而 RL 可以提供负反馈信号,人类学习的时候也是在失败中进步
自我感知角度
对于”知识获取型“问题,可分类两种情况: - 如果模型内部的知识图谱具有这个问题的知识,那么SFT会让其将知识和问题联系提来。 - 如果模型内部是没有这个知识图谱的,SFT容易让模型学会说谎。为了提升模型的可信度,我们倾向于想做的是模型直接回答不知道,而不是去记忆SFT的结论,因为这可能会让模型在遇到相关问题时胡编乱造(即模型的内部知识不理解这个问题,但是死记硬背了一个回答)。我们认为reward model和 actor是同一个基础模型,他们具有相同的内部知识系统,所以RM可以判断于自己不懂的问题回答不知道也给予奖励。