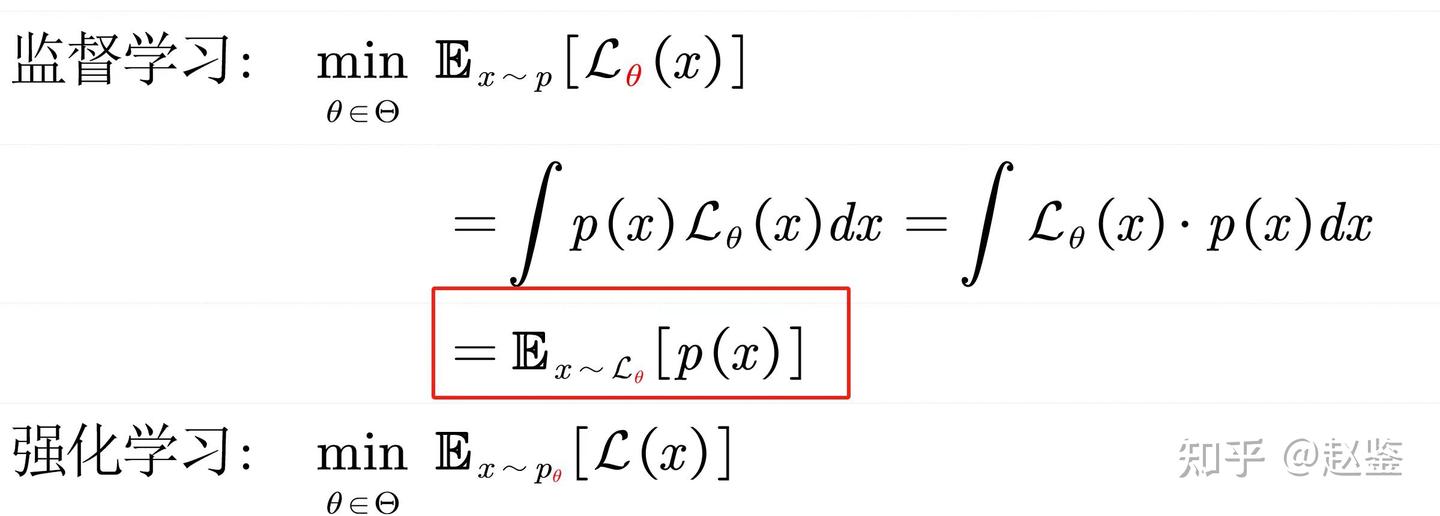基于 MLCEngine 的低延迟高吞吐量的 LLM 部署研究
基于 MLCEngine 的低延迟高吞吐量的 LLM 部署研究
青稞作者:赖睿航,CMU CS Ph.D.(已授权) 原文:https://zhuanlan.zhihu.com/p/903143931 >>加入青稞AI技术交流群,与青年研究员/开发者交流最新AI技术
今年六月初,我们 MLC 团队发布了支持全平台部署的大模型推理引擎 MLCEngine。通过机器学习编译、全平台通用的推理 runtime 和统一的 OpenAI API 接口,MLCEngine 支持从云端服务器到本地设备的全平台大语言模型部署。
引擎的推理性能长久以来以来都是我们开发 MLCEngine 过程中关注的一大重点。过去这两个多月里,MLC 社区一直在努力提升 MLCEngine 在云端 serving 场景下的性能。我们想通过这篇文章和小伙伴们分享这段时间我们取得的一些成果和经验。
在这篇文章里我们会重点探讨低延迟高吞吐量 (low-latency high-throughput) 的 LLM 推理。在有非常多优秀的工作聚焦于提升 LLM 引擎总吞吐量的同时,大家能够注意到延迟这一指标对于 LLM 引擎的重要性正在日益增长,而延迟也是大家在使用各大 API endpoint 时最能直观感受到的性能之一。因此,我们更加侧重关注引擎在低延迟需求下的表现(比如能够满足对于单个请求有 50 tok/s, 100 tok/s,甚至更高速度的需求)。除此之外,我们也很关心 LLM 引擎在不同并行度(同时处理的请求)下吞吐量和延迟这两者间的 trade-off。希望了解这些能够给大家在部署 LLM serving 时提供一些参考,帮助大家做出更灵活的选择。
下文会主要分为两大部分:首先,我们研究 MLCEngine 在 Llama3 系列模型上的延迟和吞吐量表现。在这之后我们会进一步深入分析不同推理技术 (tensor parallelism 和 speculative decoding) 对高吞吐量低延迟推理的影响。
在 NVIDIA H100 上的实验结果说明 MLCEngine 在不同的延迟需求下都具有 state-of-the-art 的性能 。同时,我们在这篇文章里尝试探讨低延迟的推理场景中不同推理系统设定之间的 trade-off。
Benchmark 设定
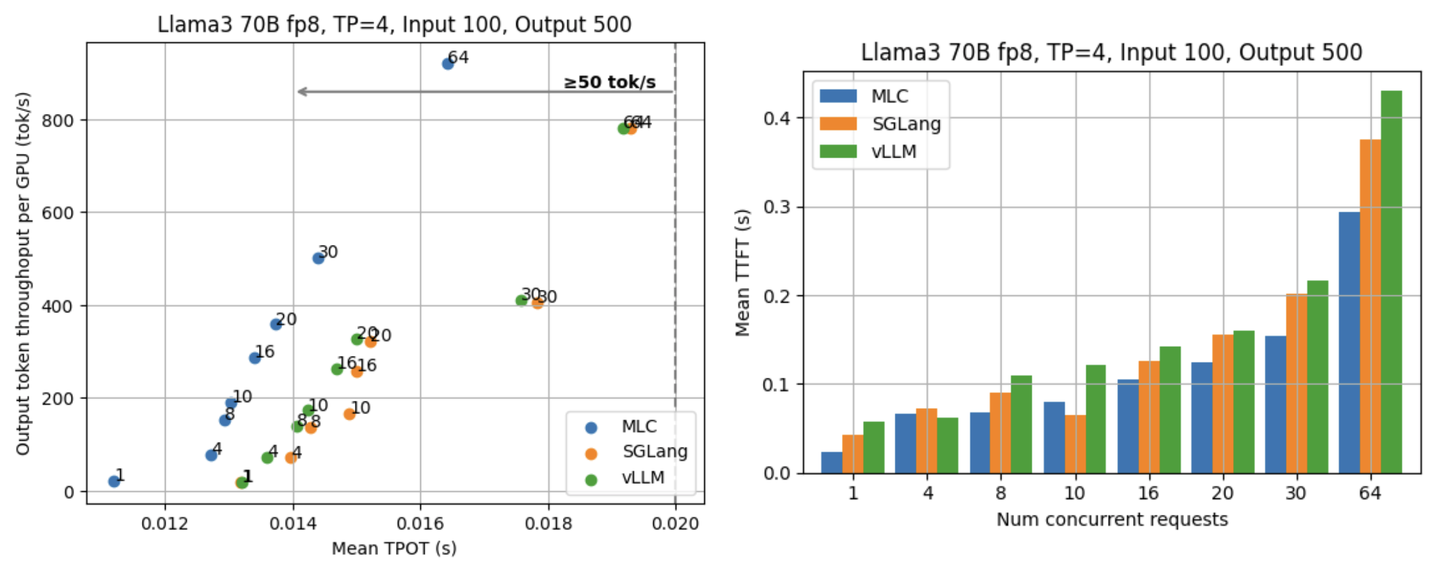
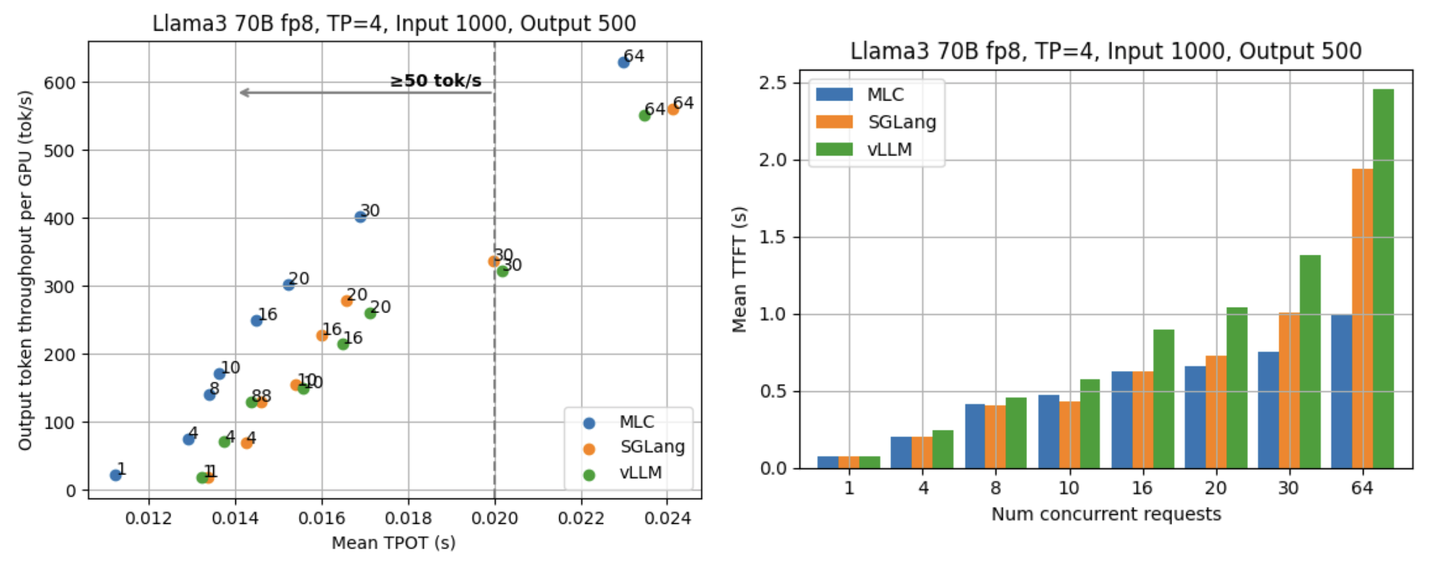
本文中的实验都是使用 Llama3 8B fp16 和 70B fp8 这两个模型,在配备 NVIDIA H100 SXM GPU 的集群上完成的。我们使用 ShareGPT 数据集,通过数据集里的输入文本和输出长度构造发送给 LLM server 的请求。每轮 benchmark 总共发送 500 个请求,分别将 LLM server 同时处理的请求数量(并行度)固定在 1/4/8/10/16/20/30/64。我们测量 LLM server 对于每个请求各自的 TPOT (time per output token,指在接收到第一次 server 返回后生成一个 token 所需要的平均时间)和 server 的总输出吞吐量(用每分钟输出的 token 数量来表示)。附录包含了在更多不同的设定和指标下的结果,包括固定请求率 (request rate) 的场景,TTFT (time to first token)、90th percentile 这两个指标,和其它的请求输入/输出长度场景下的性能表现。
为了了解 MLCEngine 与其它 state-of-the-art LLM 推理引擎之间的对比,我们将 MLCEngine 与 SGLang (v0.3.1.post2) 和 vLLM (v0.6.1.post2) 进行了一些比较。实际上,因为 LLM 推理这一领域正在飞速发展,这些不同的框架预计很快都会取得性能上的提升。我们更希望通过这篇文章与整个机器学习系统社群分享和探讨我们在优化性能的过程中所吸取的经验。
吞吐量和延迟的 Trade-Off Benchmark
首先让我们来看看 Llama3 8B fp16 的单卡和 70B fp8 的四卡 (tensor parallelism) 性能。下面两张图展示的是在不同数量的并行请求下的平均 TPOT (time per output token) 和平均每张 GPU 的输出吞吐量。展示平均每卡(而非整个系统)输出吞吐量的主要原因是我们总能够通过增加 GPU、利用 data parallelism 来提升整个系统的吞吐量。这两张图中的结果并不包含我们后在后文讨论的优化(比如 speculative decoding),同时这些数据点都是通过同一个 API endpoint 收集到的,不涉及特殊的系统配置和调优。
能够看到这两张图清楚展示了延迟和输出吞吐量之间的 trade-off。通常情况下,LLM 引擎都能够批处理并行的请求,所以随着并行请求数量的增加,引擎能拥有更高的吞吐量,对应着每张图的右侧区域。
相反,在存在一个低延迟目标的时候(比如要对单个请求做到 100 tok/s 的速度),图的左上方则会是我们要关心的区域。比如,如果保持 100 tok/s 的速度 serve Llama3 8B 请求,MLCEngine 可以支持 30 个并行的请求与总共超过 3000 tok/s 的吞吐量。总体而言,MLCEngine 在低延迟推理场景下有 state-of-the-art 的性能。接下来我们讨论一些背后的技术。
我们如何做到低延迟?
MLCEngine 的低延迟推理性能背后有许多助推因素,我们很高兴能将其中的一些经验分享给大家。
Fast decode attention.
在 LLM 推理的 decoding 阶段,attention 计算所花费时间的比例取决于 context 长度:在 context 只有 100 个 token 左右时,attention 计算只占每次 decode 时间的不到 20%,而当 context 长度增长到几千时这个比例能超过 50%。为了加速 attention 的计算,MLC 使用了 state-of-the-art attention 库 FlashInfer。
Compiler-driven kernel generation and dispatch.
MLCEngine 作为基于机器学习编译的 LLM 部署方案,能够利用多种来源的 GPU kernel。比如,对于高请求并行度的场景,我们会采用 cuBLAS 或 CUTLASS 的 GeMM kernel,而在只有一个并行请求的情况下,我们则会使用编译器生成的高效 GeMV kernel。
Dynamic shape-aware memory planning and CUDA Graph.
MLC 的模型编译管线中包含 dynamic shape-aware memory planning compiler pass,能够静态分配 LLM 推理所需要的 GPU 显存,避免在推理时动态分配/释放显存。同时编译管线包含 CUDA Graph rewrite compiler pass,能够让我们进一步利用 CUDA Graph 减少 GPU kernel launch 的开销。我们发现 CUDA Graph 对于使用 tensor parallelism 在多 GPU 上的模型部署效果尤为明显。
CPU overhead reduction.
我们做了一系列能够减少两轮 decode 之间 CPU 开销的优化。这里面比较重要的是,我们将引擎的 driving loop 放在了一个单独的线程上,而将其余前端的请求处理(比如 tokenizer encode/decode,异步的 HTTP 请求接受/发送等)交给另一个线程来处理。这样的设计能够将内部引擎的 GPU 计算和请求的输出处理重叠在一起异步处理。在所有 CPU 开销优化的帮助下,MLCEngine 的 CPU 开销占单次 batch decode 时间的 3% 左右。
Tensor Parallelism 的影响
当我们要在多张 GPU 上部署 LLM 推理的时候,data parallelism (DP) 和 tensor parallelism (TP) 是两种最常见的方式。Data parallelism 在每组 GPU 上都放置一套完整的 model weight 副本,这使得整个系统能在保持延迟不变的情况下将吞吐量翻倍。Tensor parallelism 则利用额外的 GPU 来共同计算同一个 model,在牺牲一些吞吐量的情况下进一步降低延迟。为了更好地理解 TP 在不同场景下的影响,我们研究了 MLCEngine 在不同 TP 下的性能。这里的 y 轴同样表示平均每张卡的吞吐量,从而让我们能更方便地比较高 TP 和低 TP 的设定吞吐量和延迟的 trade-off。
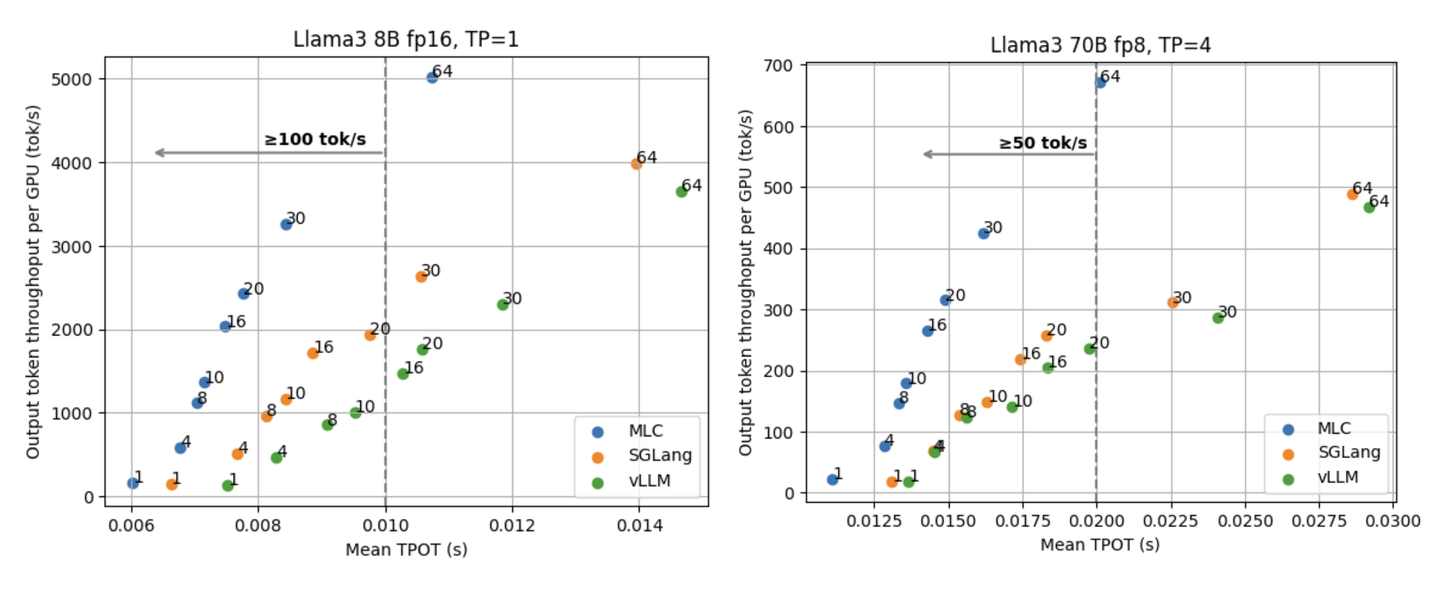
下面两张图展示了 Llama3 8B fp16 分别在 1/2 张 GPU 上的结果和 Llama3 70B fp8 在 4/8 张 GPU 上的结果。
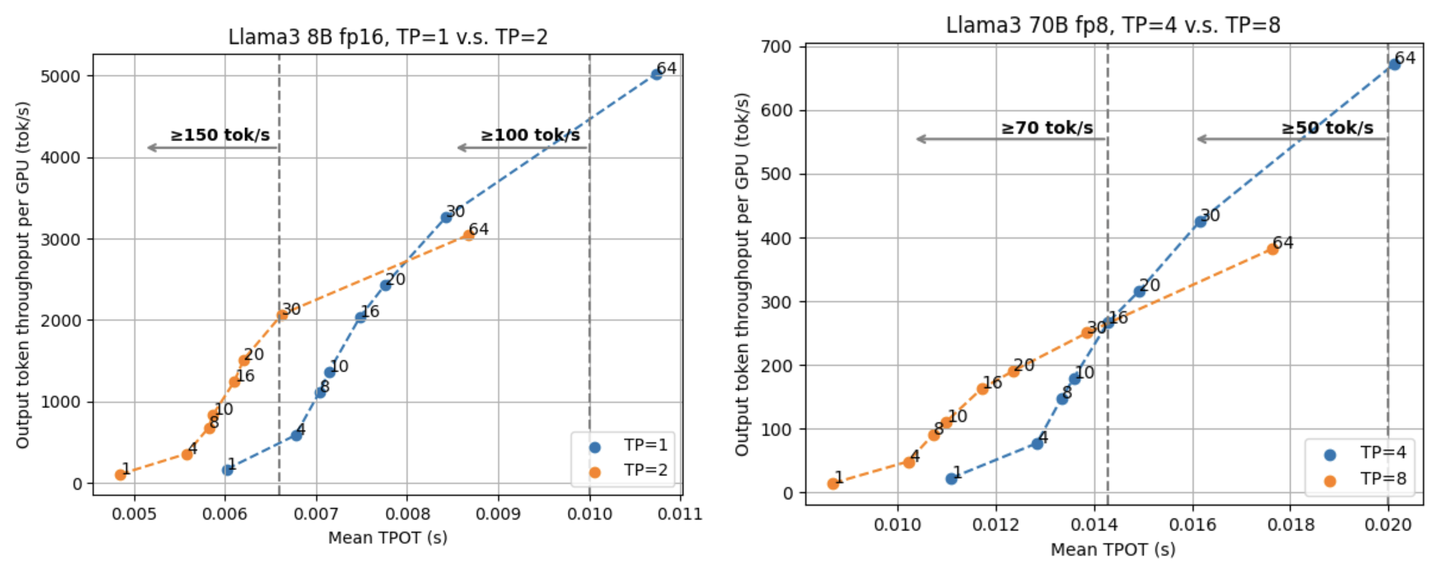
从两张图中我们能都看到两条曲线存在交叉点。交叉点的存在意味着在低延迟 LLM serving 的需求下我们需要使用高 TP,而在对延迟要求不高的情况下使用 data parallelism (和低 TP)。
对于 Llama3 8B,如果我们的延迟目标是 100 tok/s,那么 30 个并行请求在 TP=1 时已经可以满足需求,甚至有略高于 TP=2 时 64 个并行请求的吞吐量。然而,如果追求更低的延迟,TP=2 就将成为我们的选择。比如如果想要达到低于 7 毫秒的 TPOT (等价大于 143 tok/s 的输出速度),对于 TP=2 来说我们能够挑 30 的请求并行度,而对于 TP=1 来说我们只能选择 8 的并行度,还要牺牲 45% 左右的吞吐量。TP=4 和 TP=8 在 Llama3 70B fp8 上情况也类似,在 70 tok/s 的位置有一个交叉点。
这说明了 tensor parallelism, data parallelism 和延迟、吞吐量之间的复杂关系,因而在实际部署模型,决定选择 TP 或者 DP 之前,需要充分考虑我们对于延迟和吞吐量的目标是什么。
Speculative Decoding 的影响
Speculative decoding 是 LLM 推理领域能够有效降低延迟的一项技术,每次它首先利用较小的 draft 模型提供对接下来多步 decode token 的预测,再使用目标模型一次性验证所有的 draft token —— 这样做能够在不损失任何精度的情况下有效利用 LLM 推理的 batching effect。一种理解 speculative decoding 作用的方式是将其看成 “增大单个请求的有效 batch size”。目前大部分对 speculative decoding 的研究都集中在处理单个请求的场景,在这种情况下整个系统的请求并行度和吞吐量都相对较低。我们想借此机会对其在 LLM serving 上的效果一探究竟,因为在实际的 LLM serving 会对于系统整体的吞吐量和并行度都有一定的要求。
因此,我们通过在 MLCEngine 中实现的 speculative decoding 研究用 Llama3 8B fp8 作为 draft 模型预测 Llama3 70B fp8 模型的效果。我们固定每一次 draft 模型生成的 draft 长度在 3(这样在验证阶段每个请求要被验证长度是 4),分别测试了 TP=4 和 8 时候与普通的 batch decoding 所比较的结果。
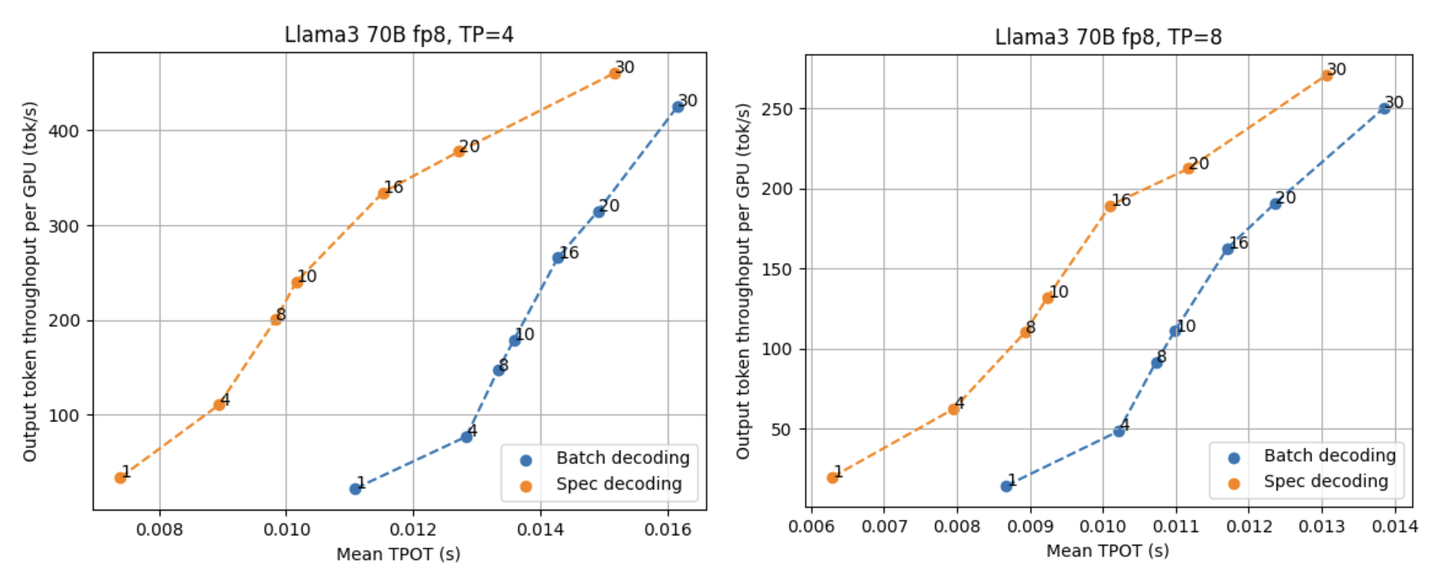
如上面这两张图所展示的,speculative decoding 能够稳定降低延迟。在目前的 benchmark 场景里,TP=4 能够提供更大的 throughput,而 TP=8 与 speculative decoding 的结合则能进一步将 TPOT 推向极限,在有 16 个并行请求的情况下都能达到 100 tok/s。随着并行度的增大,LLM 推理逐渐从 memory bound 向 compute bound 转移,因而 speculative decoding 对降低延迟所能够提供的帮助也在逐渐减小。
值得一提的是,还有一些因素会对 speculative decoding 的效果造成影响,比如不同的数据集可能会影响 draft 模型的预测准确率,从而进一步影响 speculative decoding 能够带来的提升。
Efficient Speculative Decoding System with Continuous Batching.
我们在实践中发现对在 LLM 引擎中实现高效的 speculative decoding 并将其和 continuous batching 结合在一起而言,有一系列系统层面的挑战需要克服。因为 draft 模型的存在,每一次完整 draft 的生成需要跑多轮 draft 模型,所以整个引擎的 CPU 开销会被放大,而降低这些开销也就变得更加重要。同时,我们需要非常小心地管理 draft 模型所生成的 probability distribution,避免在生成和验证 draft 的过程中有动态的内存分配。此外,为了减少 probability distribution 在 GPU 与 CPU 之间的传输,我们需要有专门的 GPU kernel 来处理 draft verification。
一些讨论与未来展望
这篇文章里我们探究了高吞吐量低延迟场景下的 LLM 推理 trade-off。实际上,还有很多 MLCEngine 中更加高级的推理技术(诸如 common system prompt 与 prefix caching,结构化 JSON 输出与其开销,更高级的 speculative decoding 方法如 Eagle 和 Medusa 等)没有在本文中展现。而所有这些技术组合在一起的综合性能表现会与我们所关注的 serving 场景密切相关,我们会在今后讨论这些技术。
附录
固定请求率 (request rate)
前文的实验全部都是在固定并行请求数的设定下进行的。在并行度固定的情况下,我们能更清楚地剖析 LLM 引擎在不同强度下的性能。固定请求率(平均每秒到达的新请求数量)则是另一个很常见的 benchmark 方式,在这种情况下 LLM 引擎所要并行处理的请求数量会随着时间动态变化。相比于固定并行度,这种 benchmark 更能够反映 LLM 的综合性能。下面两张图展示了不同请求率 (1/2/4/8/16) 下的延迟和吞吐量结果,MLCEngine 在这些情况下具有 state-of-the-art 的性能。
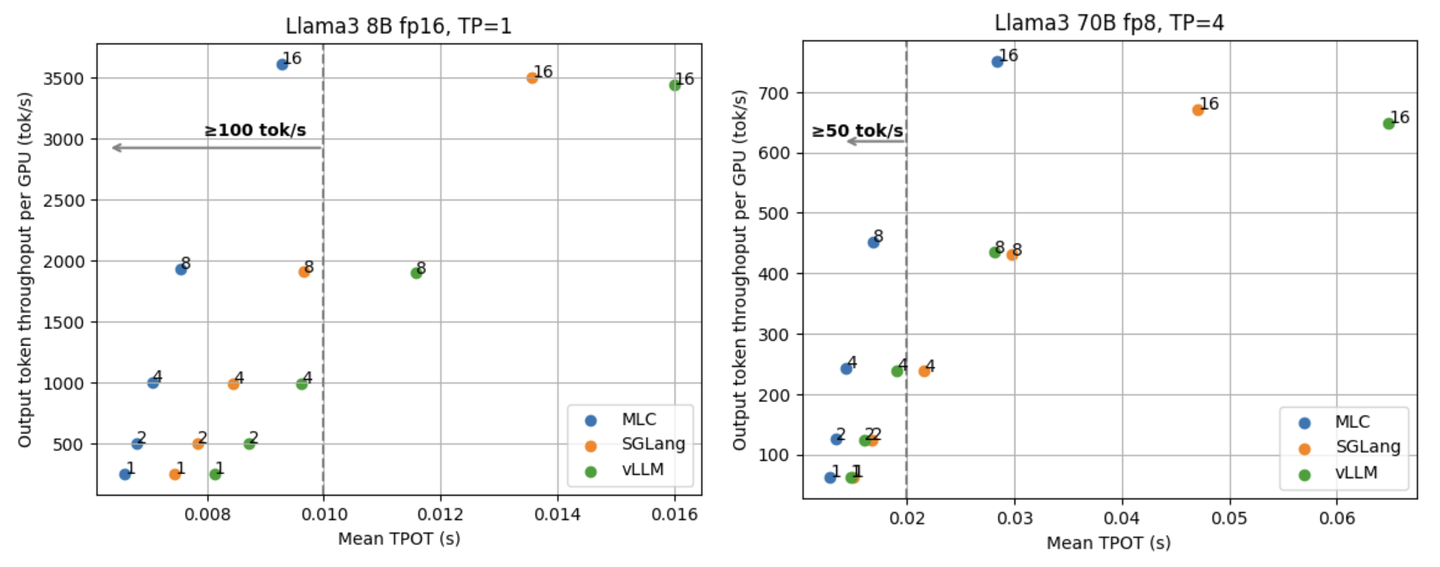
TTFT (Time to first token)
TTFT 是 LLM serving 很重要的一个性能指标,它指的是从发送一个请求到收到第一次响应所花的时间。通常来说,TTFT 能反映 LLM 引擎在 input prefill 和请求调度等方面的效率。下面两张图展示了 Llama3 8B fp16 和 70B fp8 在不同并行度下的平均 TTFT。可以看到 MLCEngine 在不同的并行度下都有与其他框架相当的 TTFT。
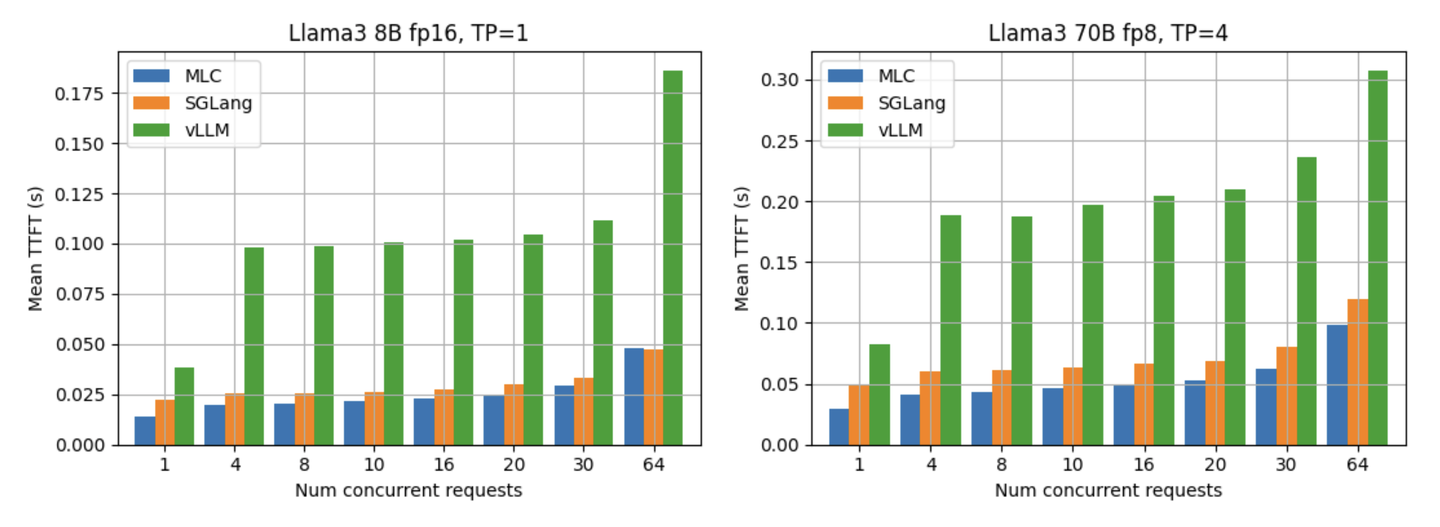
90th percentile 性能
除了平均的 TPOT 与 TTFT 水平,另一个大家所关心的方面是 LLM 引擎的 tail performance。下面两张图展示了 Llama3 70B fp8 在不同并行度下的 p90 TPOT 与 TTFT。
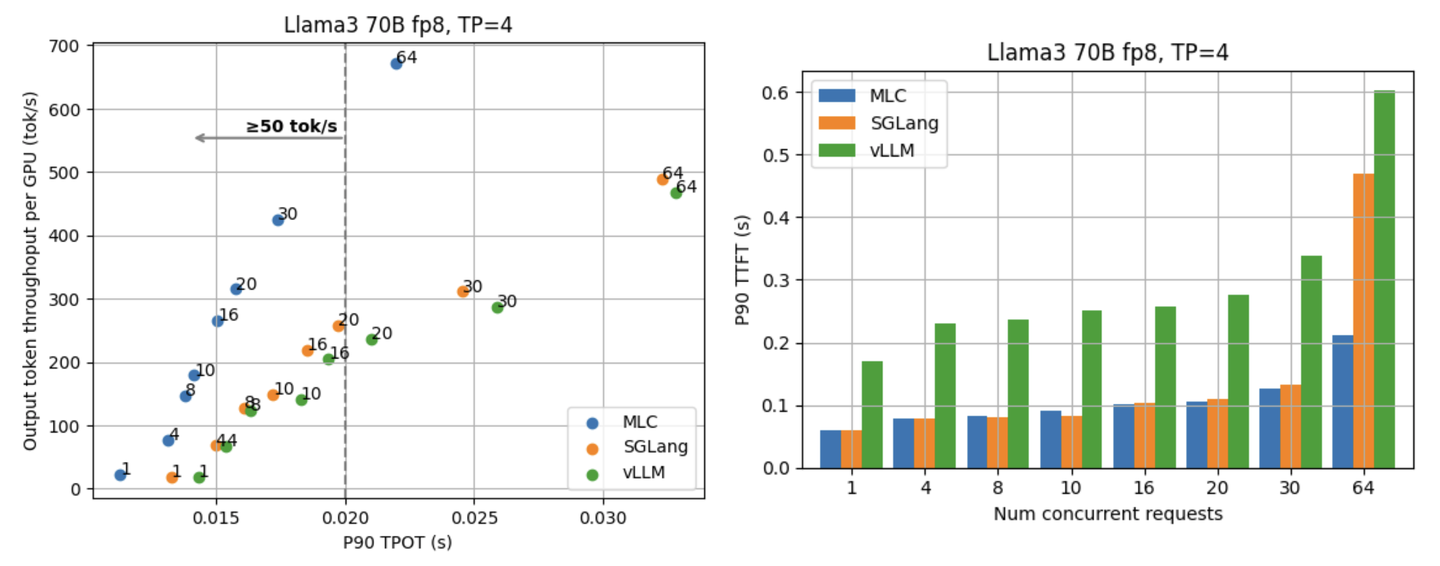
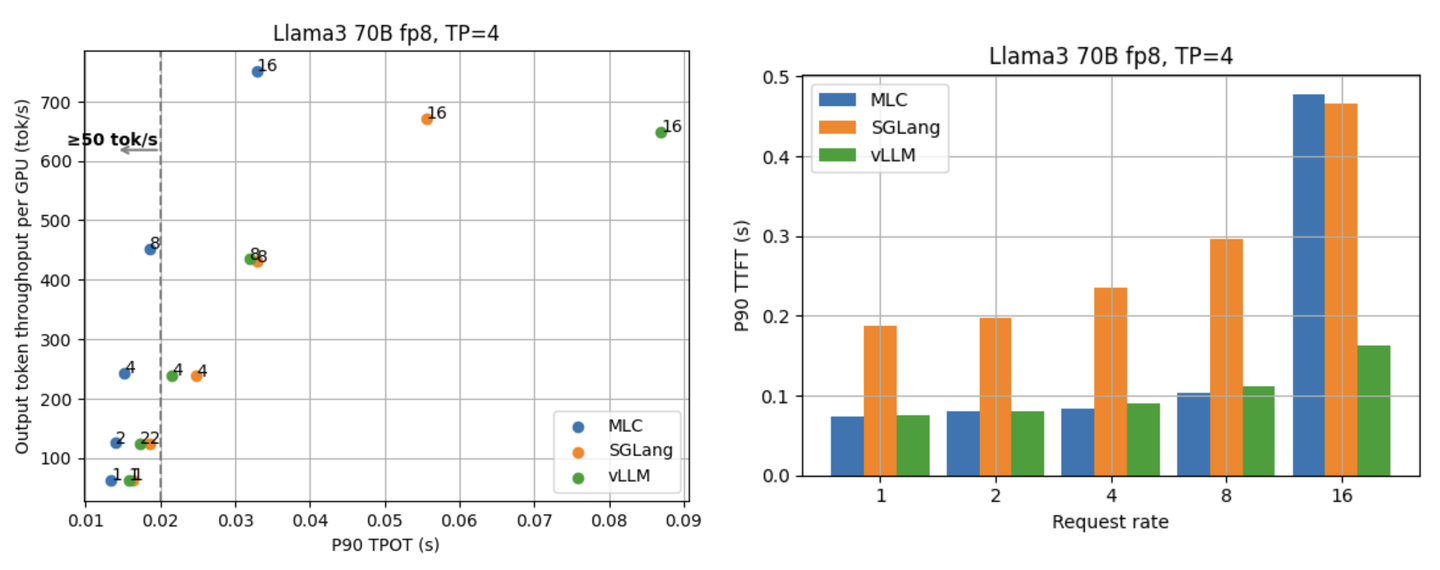
接下来两张图展示了 Llama3 70B fp8 在不同请求率下的 p90 TPOT 与 TTFT。
不同的输入/输出长度
除了直接使用 ShareGPT 数据集中真实的输入/输出长度,我们同样尝试了一些不同的输入/输出长度设定。下面两张图展示了当所有请求统一输入长度 100 tokens,输出长度 500 tokens 时在 Llama3 70B fp8 上的 TPOT 和 TTFT 结果。
最后两张图是在统一输入长度 1000,输出长度 500 时的实验结果。
Benchmark instructions
1 | # Install MLC-LLM |