字节 DAPO 技术报告有感!大模型 RL 细节为王

字节 DAPO 技术报告有感!大模型 RL 细节为王
青稞
- 作者:haotian
- 原文:https://zhuanlan.zhihu.com/p/31770741283
近期,seed&清华发表的DAPO,将32b-base做到了aime50分的效果,是一个值得参考的技术报告。这个报告里面提到了很多方法/tricks:

好的流程远胜不靠谱的算法trick
llm的sft和rl,笔者认为,二者差别不大,sft是rl的一个特例(有一些文章做了类似的讨论),而rl则更好的利用了负样本。在dapo中,一个核心是dynamic-sampling,简单来说,根据当前模型在prompt的bon,动态决定采样budget,难prompt采样更多的sample,简单prompt则采样更少的prompt,以及过滤模型解决不了的hard-prompt或者easy-prompt。
在sft阶段,通常也会使用类似的策略做code/math等等的拒绝采样、筛选多样性response(embedding+聚类、长度)。从DAPO中可以看出,一个良好的pipline(online-dynamic-sampling)远胜于不靠谱的算法trick。
当做好sft后,从数据/task、response合成/采样、response挑选/打分方法等等,都有一个相对固定且运行良好的流程。把这个流程做到online,在replay-buffer的数据构造中即可应用,配合对应的挑选/打分/筛选策略,便可将sft阶段积累的优秀流程直接迁移到online-rl。同时也需要replay-buffer和主代码解耦,做灵活的控制。
总之,能做好sft且pipline能够在线化运行的团队,做好online-rl只是算力和时间的问题(生产要素)。反之,则陷入一个窘境(生产关系):
- 做sft的一直offline调数据、蒸馏、挑选,但pipline较难在线化运行,且需要人力不断重复,但实际上都是well-defined流程和配比实验,不太需要过多的人工参与;(出现能力/任务冲突后,人工介入处理)
- 做rl的不断重复sft的数据流程:找数据、找replay-buffer的数据构建策略,踩过一坨坑后,发现,这些策略其实和sft并无不同,造成了极大的资源浪费和时间浪费。
- 做agent-rl的时候,agent-rl只需要写一个推理引擎的多次采样即可,而环境的稳定性则更为重要。如果sft没怎么做过agent-based的sft数据,则环境积累基本为0,当应用agent-rl的时候,环境稳定性会成为rl训练的阿喀琉斯之踵。尤其是agent环境,延时、返回结果的不确定性等等会加剧这个问题。
token-level-loss分析
DAPO中提到了token-level-loss,这个议题在24年末在社区也引起了一些讨论,尤其当梯度累加较大的时候,会导致梯度累加训练和大batch训练loss有较大的差异,具体可参考1:
这里,第一行是 大batch的loss计算,第二行是ga=2的loss计算,显然,主流框架实现的为第二行的loss计算,天然会比大batch计算的loss更大,对于长文本训练会产生不利的影响。
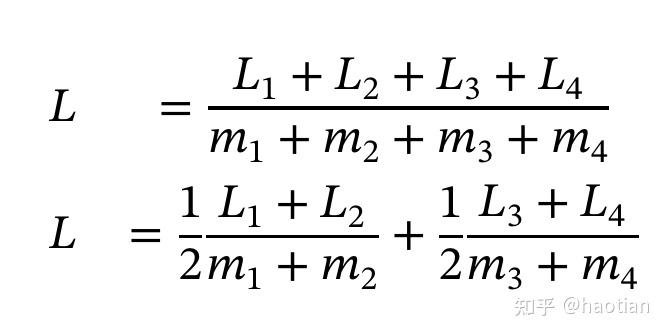
在openrlhf/verl中,micro-batch-loss为token-level-loss计算,但有梯度累加的时候,也会存在类似的问题。对于训练会有一定的影响。前期loss过大,优化过于激进。
实现梯度累加内的token-level-loss也比较直观,计算loss的时候,直接按照各个维度求和再除以当前ga内的总token数:
1 | if len(prefetch) == 0 or len(prefetch) % self.strategy.accumulated_gradient != 0: |
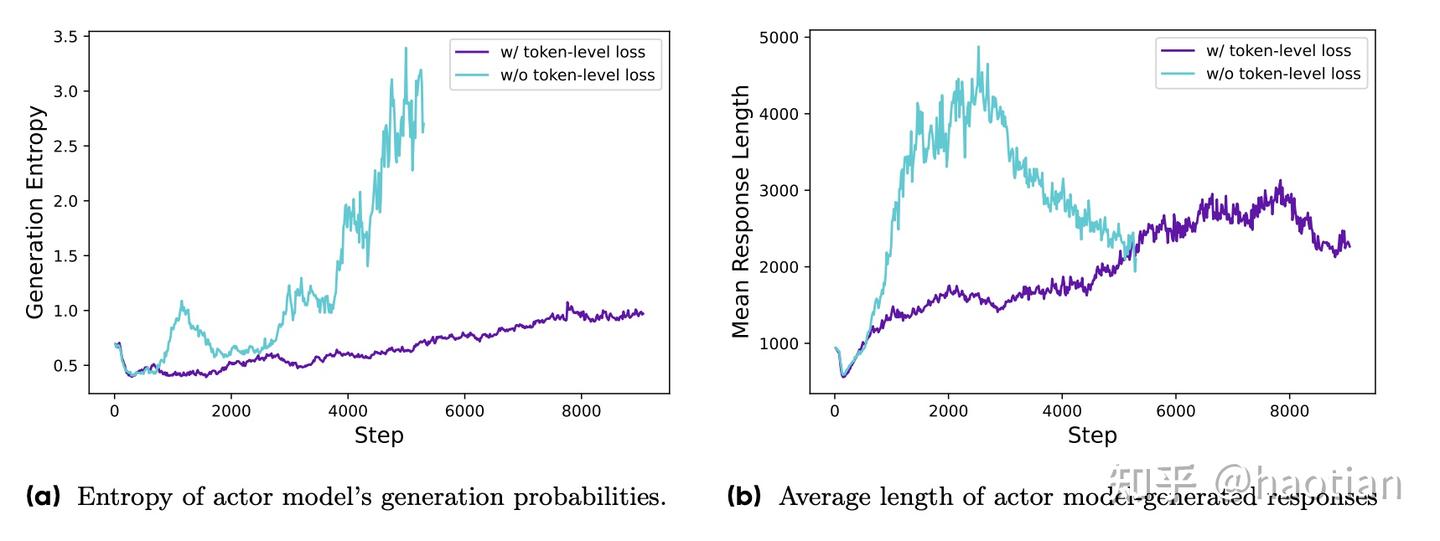
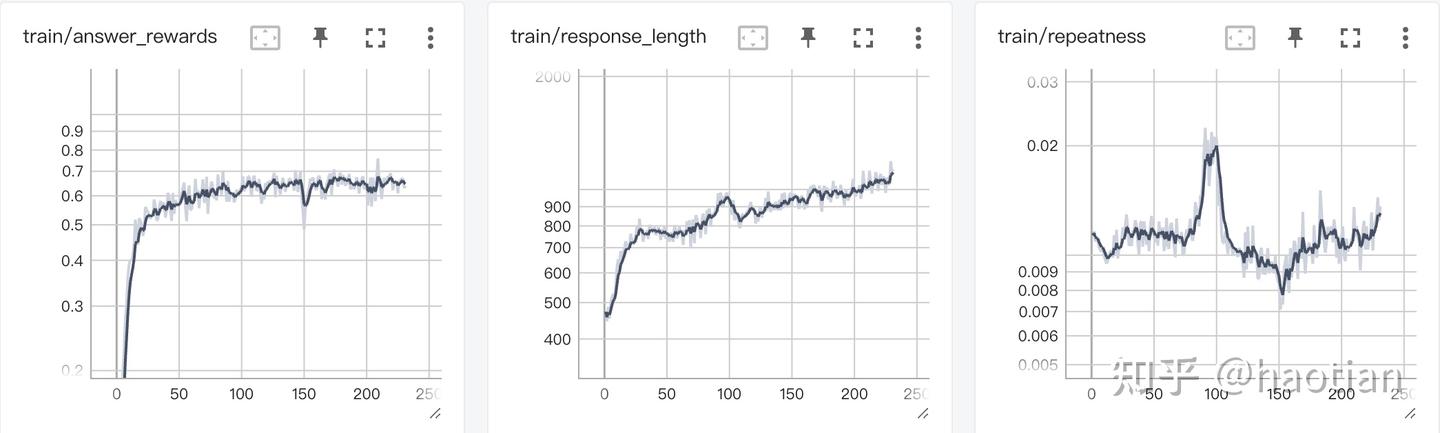
grpo:无token-level-loss
grpo:有ga-token-level-loss
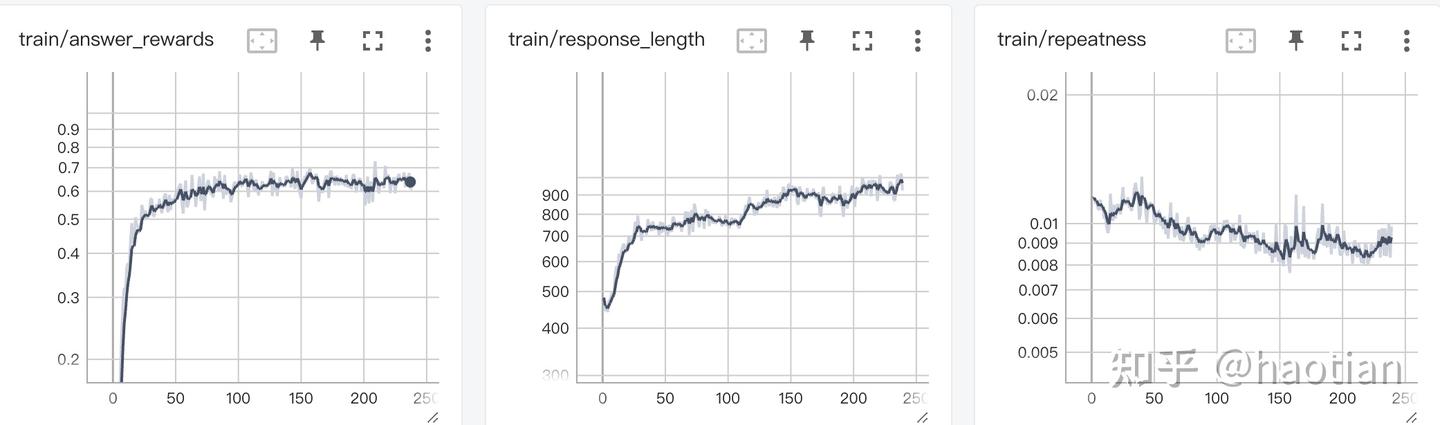
参考orz的repeatness统计,ga-token-level-loss会让grpo优化更稳定一些,至少不会产生特别多的重复,而none-token-level-loss训练到后期,repeatness、format崩溃会显著上升(不加任何dataloader-filter、kl、entropy正则的情况下)。
对比reinforce_baseline和grpo的异同点
(token-level-loss,不考虑kl、entropy等等)
reinforce_baseline的advantage计算:r-group_mean+全局归一化
grpo的advantage计算:(r-group_mean)/group_std(group归一化)
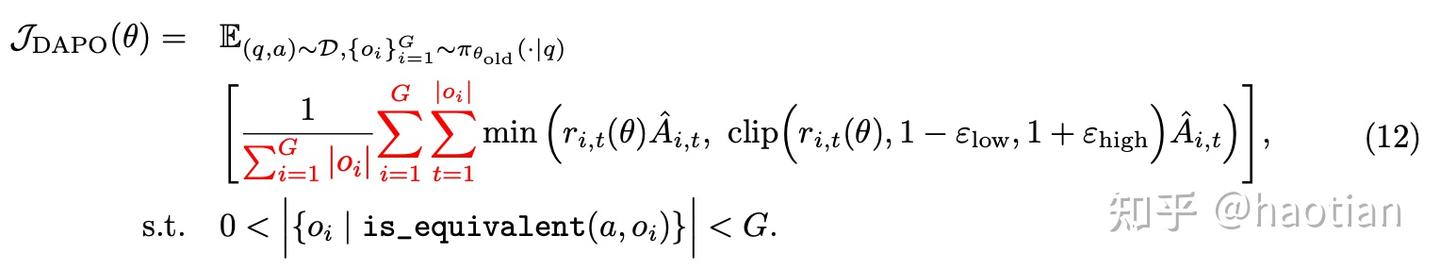
3中对grpo进行了细致的分析和推导:当reward=0/1时(为一个随机变量服从伯努利分布),我们有如下均值/方差的估计
对于reinforce_baseline来说,
\(\sum_{i=1}^{G}\sum_{t=1}^{|o_i|}\min\left(r_{i,t}(\theta)\widehat{A}_{i,t},\text{clip}(1-\varepsilon_{low}, 1+\varepsilon_{high})\widehat{A}_{i,t}\right)\)
这里,
\(A_{\text{reinforce}}=\frac{r-p_i}{\text{std}_{\text{global}}} , A_{\text{grpo}}=\frac{r-p_i}{\text{std}_{\text{group}}}\)
则reinforce_baseline和grpo只差一个系数:
\(A_{\text{grpo}}=A_{\text{reinforce}}\frac{\text{std}_{\text{global}}}{\text{std}_{\text{group}}}\)
全局std:由于进行了局部均值归一化,global-mean的期望=0,global-std为group的方差求和开根号,global-std要大于group-std,当采样样本无穷多时,
group-std: \(\sqrt{p_i(1-p_i)}\)
global-std: \(\sqrt{\sum_{i}p_i(1-p_i)}\)
如果不对group样本做调整,当group-std的标准差小到一定程度,会让当前的loss急剧增加,产生更为激进的优化。道理上,reinfroce_baseline和grpo有着类似的training-dynamics,而grpo的收敛速度要好于reinfroce_baseline,但稳定性来说,不如reinforce_baseline。当全局样本都处于方差较小的状态,reinforce_baseline也会崩,只是要比grpo来的晚一些。
最后总结一下
- sft流程搬到online-replay-buffer采样流程中,基本上就能做好online-rl(稳定的online环境+鲁棒的rl方法);
- token-level-loss在ga层面实现也重要,毕竟,在rl训练时,梯度累加都开的比较大,一种规避方式是一次采样多次参数更新即更offpolicy一些;
- reinforce_baseline和grpo有着类似的training-dynamics,二者的advantage只差一个系数,道理上,reinforce_baseline会更稳定,而grpo可能前期优化会比较猛。