

GPT-4o
的多模态基础能力和交互体验令人感到惊艳,然而开源模型很少在这两个方向均表现出色。来自腾讯优图实验室
(Tencent Youtu Lab)、南京大学 (NJU)等的研究者们最新发布了
VITA,这是第一个开源的交互式多模态大语言模型,它能够同时处理和分析视频、图像、文本和语音模态,同时具有先进的多模态交互体验。VITA
深度解读可参考:腾讯优图开源多模态大模型VITA
: GPT-4o的简易平替!
VITA 以 Mixtral
8x7B作为语言基座,扩大其汉语词汇量,然后进行中英双语微调,并进一步的通过多模态对齐和指令微调两阶段赋予语言模型视觉和语音理解能力。VITA
展示了强大的多语言、视觉和语音理解基础能力,其在单模态和多模态基准测试中均表现出色。
除了基础能力之外,在增强多模式人机交互体验方面也取得了一定的进展,VITA
是第一个提出非唤醒交互和语音打断交互的多模态大语言模型,也是开源社区探索多模式理解和交互无缝集成的第一步,希望它作为先驱可以作为后续研究的基石。
10月14日19点,青稞Talk 第26期,VITA
第一作者,南京大学智能科学与技术学院研究 ...

SGLang 是 LMSYS Org 团队于开源的一个用于 LLM 和 VLM
的通用服务引擎,采用 Apache 2.0 许可授权。它由纯 Python
编写,核心调度器只用了不到 4K 行代码就实现了,已被 LMSYS Chatbot Arena
用于支持部分模型、Databricks、几家初创公司和研究机构,产生了数万亿
token,实现了更快的迭代。
1https://github.com/sgl-project/sglang
FlashInfer 是一个由 UW、CMU 和 OctoAI
的研究者们开源的一个大型语言模型库,可提供 LLM GPU 内核(例如
FlashAttention、SparseAttention、PageAttention、Sampling等)的高性能实现,提供了PyTorch
API用于快速开发,以及header-only的C++
API,可以方便地集成到LLM服务引擎中。FlashInfer已被多个LLM服务框架所集成,包括
MLC-LLM (用于CUDA后端)和 SGLang。
1https://github.com/flashinfer-a ...
作者:yearn,微软亚洲研究院 · Research Intern 主页:https://yfzhang114.github.io/
原文:https://zhuanlan.zhihu.com/p/731680062
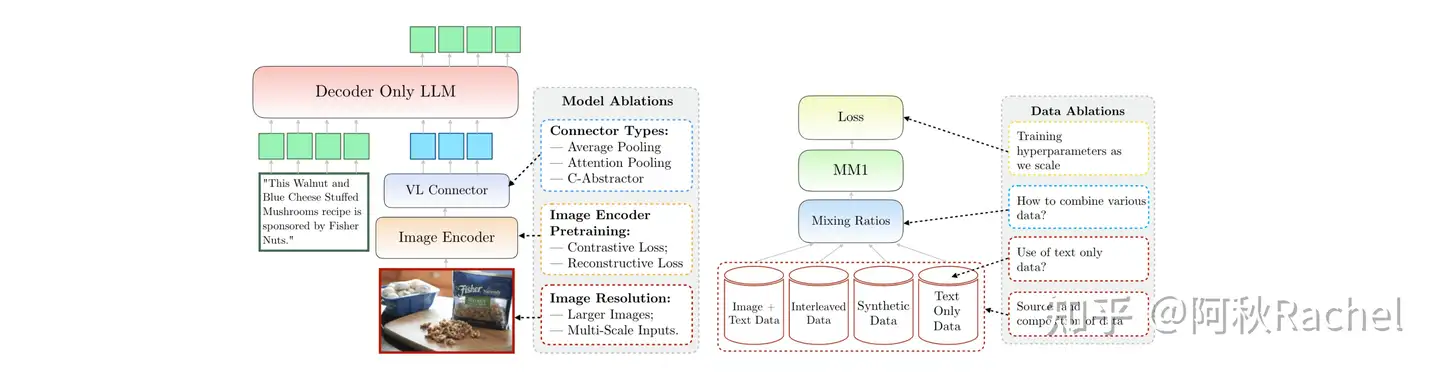
视觉-语言模型(Vision-Language Models,
VLMs)领域正迅速发展,但在数据、架构和训练方法等关键方面还未达成共识。本文旨在为构建VLM提供指南,概述当前的最先进方法,指出各自的优缺点,解决该领域的主要挑战,并为未被充分探索的研究领域提供有前途的研究方向。
1Abs:https://www.arxiv.org/pdf/2408.12637
主要贡献
系统性综述:提供了对当前最先进VLM方法的全面概述,探讨了不同方法的优缺点,提出了未来的研究方向。
实践指导:详细阐述了构建Idefics3-8B模型的实际步骤,这是一种强大的VLM,显著优于其前身Idefics2-8B。
数据集贡献:创建了Docmatix数据集,用于提升文档理解能力。该数据集包含240倍于之前开放数据集的规模,共计2.4百万张图片和9.5百万对问答对,从1.3百万个PDF文档中 ...

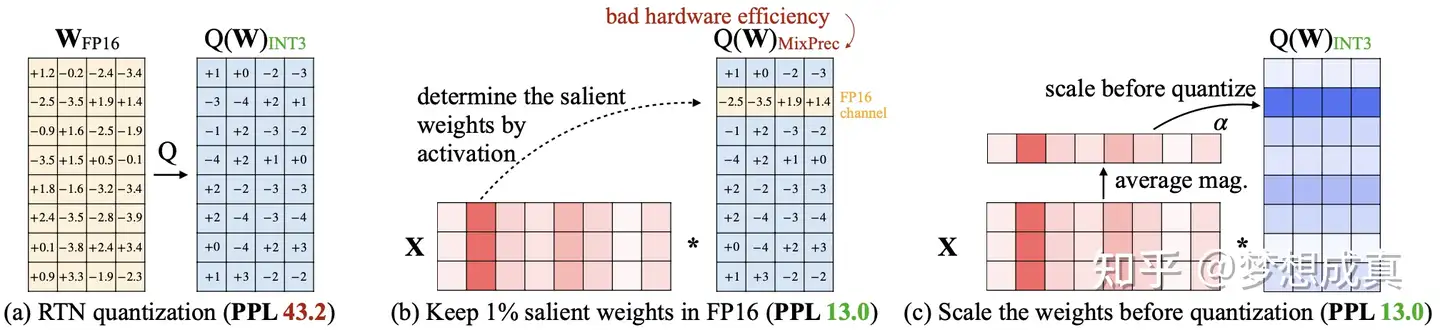
大语言模型(LLM)的最新进展以其卓越的涌现能力和推理能力推动我们走向通用人工智能。然而,大量的计算和内存要求限制了广泛采用。量化是一种关键的压缩技术,可以通过压缩和加速
LLM
来有效缓解这些需求,尽管存在潜在的准确性风险。许多研究的目的是尽量减少与量化相关的精度损失。然而,它们的量化配置各不相同,无法公平比较。
来自北航、商汤、南洋理工等团队联合推出的大模型压缩工具与基准LLMC,一个即插即用的压缩工具包,以公平、系统地探索量化的影响。
LLMC 集成了数十种算法、模型和硬件,提供了从整数到浮点量化、从 LLM
到视觉语言(VLM)模型、从固定位到混合精度、从量化到稀疏化的高度可扩展性。
在这个多功能工具包的支持下,LLMC
基准测试涵盖了三个关键方面:校准数据、算法(三种策略)和数据格式,为用户的进一步研究和实践指导提供了新颖的见解和详细的分析。在使用
LLMC 对Llama 3.1进行量化压缩后,可以使得一张80G A100即可完成 Llama 3.1
405B 的校准和评估,从而实现以超低成本进行量化。
LLMC已开源,欢迎大家Star!
1https://github. ...
作者:知返 原文:https://zhuanlan.zhihu.com/p/764498716 >>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
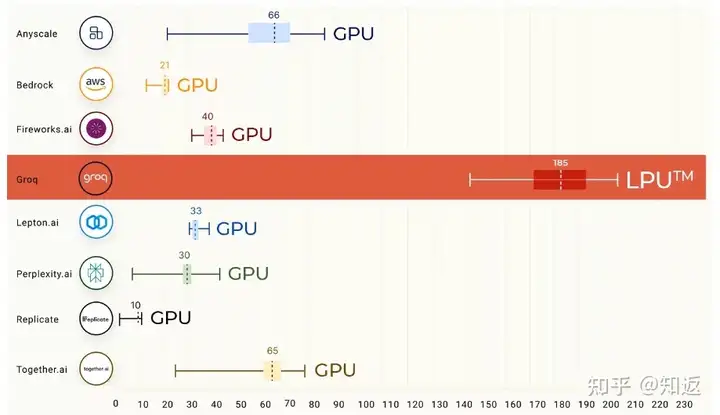
在今年年初写的一篇文章里面,我曾经分析过当时大热的Groq LPU
加速器的LLM推理性能,现在看来里面分析的方法论稍微有些稚嫩,不过大体结论都还是对的。
如果你还不了解Groq当时搞了什么大新闻,可以再回顾一下下面这张图。在LLAMA2
70B模型下,Groq LPU以接近200Token/s
的单用户推理性能冠绝群雄。注意,这是单用户的吞吐,而不是整个系统通过组大Batch打满算力带宽得到的吞吐。可以换算一下每token的延迟(TBT)可以打到5ms左右。作为对比,通常GPU推理实例能达到的TBT一般在15-50ms。
Groq LPU 单用户推理性能
在文章的结尾我做了几个预测与分析,一方面是当时看来,低延迟推理的商业模式还没有没有跑通,低延迟推理意味着什么还是个大大的问号。二是显然LPU的分布式SRAM卡+确定性互联和调度的方案只能算是“青春版”解法,这个赛道上一定会有晶圆级大SRAM加速器玩 ...
作者:阿秋Rachel 原文:https://zhuanlan.zhihu.com/p/722324120
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
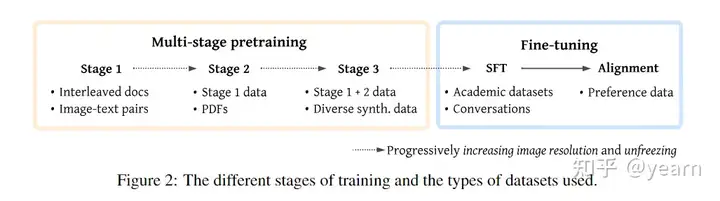
多模态大模型预训练探究主要指的是在视觉指令微调前的训练阶段,让模型学会理解图像及其视觉概念,在多个模态上进行joint
modeling的过程。
本文主要内容来自下列文章,探索了视觉语言预训练阶段如何设计更有利于下游任务。
VILA: On Pre-training for
Visual Language Models
MM1: Methods, Analysis
& Insights from Multimodal LLM Pre-training
NVLM: Open Frontier-Class
Multimodal LLMs
VILA
结论
好的预训练阶段可以让模型具有多图推理能力、更强的in-context
learning能力、更广泛的世界知识。
预训练时冻结LLMs就可以实现不错的zero-shot能力,但是在in-context
learning能力上会有所下降。
...
作者:梦想成真,阿里巴巴集团算法工程师 原文:https://zhuanlan.zhihu.com/p/688736901
前言
LLM参数一般都是1.5B,3B,7B,13B甚至更大,远大于CV的主流模型。并且随着ChatGPT爆火,基本上现在的LLM都是围绕decoder-only的next
token
prediction形式,推理预测方式相对比较固定,本文是从一个初学者角度,介绍LLM
若干推理加速方式。
总览
总的来说,我的调研中,有如下几种方式可以提高LLM推理的速度
量化
模型结构改进
Dynamic batch
投机(Speculative) 推理
量化
几乎在每一个LLM的公开repo中都能看到作者团队release了不同大小的量化模型,这是因为量化是一种非常有效的加速LLM推理,并且减少显存占用的方式。
数值类型
讲量化之前,有必要带大家重温一下数值类型。如果你觉得不重要,你完全可以跳过到下一个章节
,你只需要记住LLM的训练和推理要尽量使用BF16,而不是FP16,HF16,FP32就行了。
这里主要区分** FP32 、FP16
和BF16**。这些是L ...
作者:mackler,Computer Architect/Minecraft 原文:https://zhuanlan.zhihu.com/p/730982539
OpenAI
o1的推出带来了一波新的算法热潮,OpenAI官方也强推所谓新的深度思考的Scaling。虽然听起来用LLM和RL来进行隐式COT(也就是“思考”)咋一眼看上去很有道理。但真正支撑Scaling还是需要深入思考里面的很多基本假设,和我过去的文章一样,包含很多个人观点极强的暴论,各位看官酌情食用。
关于o1实现方式大家也已经猜测地八九不离十了,以下几个都可以参考参考
GitHub -
hijkzzz/Awesome-LLM-Strawberry 收录了不少相关论文
曹宇:OpenAI o1
self-play RL 技术路线推演
张俊林:Reverse-o1:OpenAI
o1原理逆向工程图解
无论如何,给LLM纠错的机会,对于效果的提升都是可以预期的。LLM生成token的过程中,生成的序列越长,产生错误token的概率自然也会越高,后面模型为了自洽往往会用一百个谎言来掩盖第一个谎言,最后就彻底逻辑失控 ...

作者: ybq,nlp码农,中国科学院大学 信号与信息处理硕士 原文: https://zhuanlan.zhihu.com/p/718354385
这篇文章介绍下如何从零到一进行 pretrain 工作。
类似的文章应该有很多,不同的地方可能在于,我并不会去分析 pretrain
阶段的核心技术,而是用比较朴素的语言来描述这个大工程的每一块砖瓦。我的介绍偏方法论一些,主要目的是普及每个环节有哪些必须要做的琐碎工作、有哪些坑、以及有哪些避坑技巧。为了避免老板开了我,文中有一些内容的具体做法不会展开细说,请大家见谅。作为替代,我会推荐一些比较好的开源做法。
背景篇
时至今日,dense 模型有 qwen,MOE 模型有 deepseek,小尺寸模型有
minicpm。无论是个人还是大厂,都很难训出同 size 下更优秀的模型,大模型
pretrain
阶段全面拥抱开源的日子感觉不太远了。那么,在这个时代大背景下,自研
pretrain 模型的意义又有哪些呢?
正经答案
各公司仅仅是开源了模型参数,但并没有开源训练框架、训练数据等更核心的内容,其实本质上还是闭源。在这种情况下,每一个 ...

青稞社区
青年AI研究员idea加油站,AI开发者的新能源充电桩!
青稞AI技术交流群
长案扫码添加青稞小助手
备注:姓名-学校/公司-学历/职位-研究领域(如:青稞-MIT-博士-LLM),即可申请加入青稞LLM/多模态/Agent/具身智能/面试/顶会等技术交流群:
加入青稞AI技术交流群,不仅能与来自MIT、港中文、CMU、UCLA、斯坦福、清华、阿里、腾讯等名校名企AI研究员/开发者一起进行技术交流,同时还有青年AI研究员/开发者的Talk分享、行业前沿资讯、顶会资源、招聘内推等。
社群列表
细分方向技术交流群
青稞|LLM技术交流群
青稞|多模态技术交流群
青稞|具身智能技术交流群
青稞|Agent技术交流群
青稞|Diffusion技术交流群
SGLang技术交流群
顶会投稿开会交流群
ICRA 投稿开会交流群 | 青稞
CVPR 投稿开会交流群 | 青稞
ICASSP 投稿开会交流群 | 青稞
NAACL 投稿开会交流群 | 青稞
ECCV 投稿开会交流群 | 青稞
AIGC/LLM面试交流群
青稞|AIGC&LLM面试招聘交流群
行业资讯群
...
