
作者:葡萄是猫 原文:https://zhuanlan.zhihu.com/p/8776092026
>>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
简要
为提升MLLM对图像、视频的理解能力,最有效的方式就是提升visual
token的个数,随之而来的则是训练、推理耗时的增加。因此,对视觉token进行压缩以提取最有用的信息至关重要。下文基于个人理解,进行梳理。
已知技术方案概览:
1.线性映射:采用多层MLP进行压缩,如Qwen2-VL中
2.下采样:采用Pooling(可以是不同的pool采样方式),如LLaVA-OneVision
3.Pixel-Shuffle:用通道换空间,如InternVL1.1及后续系列
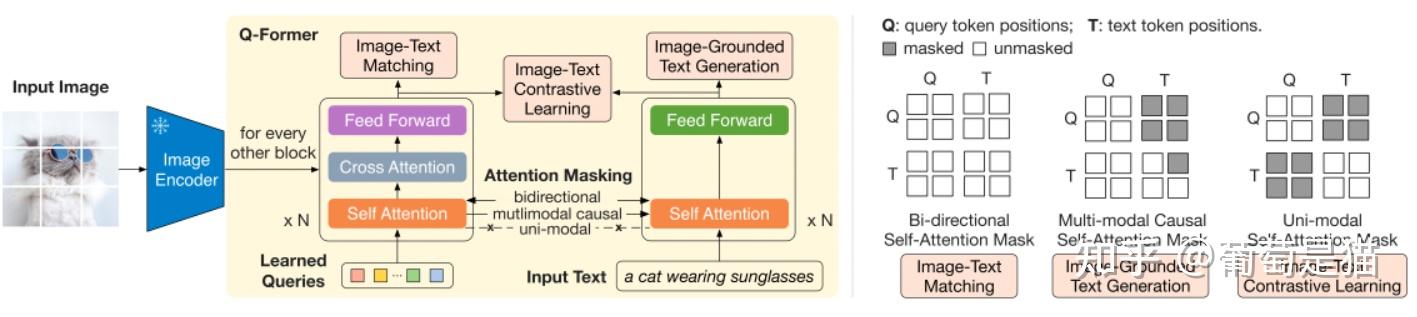
4.Q-former:新增learned
query实现视觉token压缩,如Flamingo、BLIP2
5.模型动态压缩:利用模型指导视觉token采样,如FocusLLaVA、MustDrop
6.注意力改造:改造注意力机制,不直接压缩token,但仍能达到提升推理速度的目的,如mPlug-owl3
其中,线性映射、下采 ...
作者:janbox 原文:https://zhuanlan.zhihu.com/p/6345302826 >>加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
一、基本步骤
训练llm,基本分为三步:pretrain -> sft(chat model) ->
dpo/RLHF(helpful & Safety). 辅助的环节:数据处理,评估
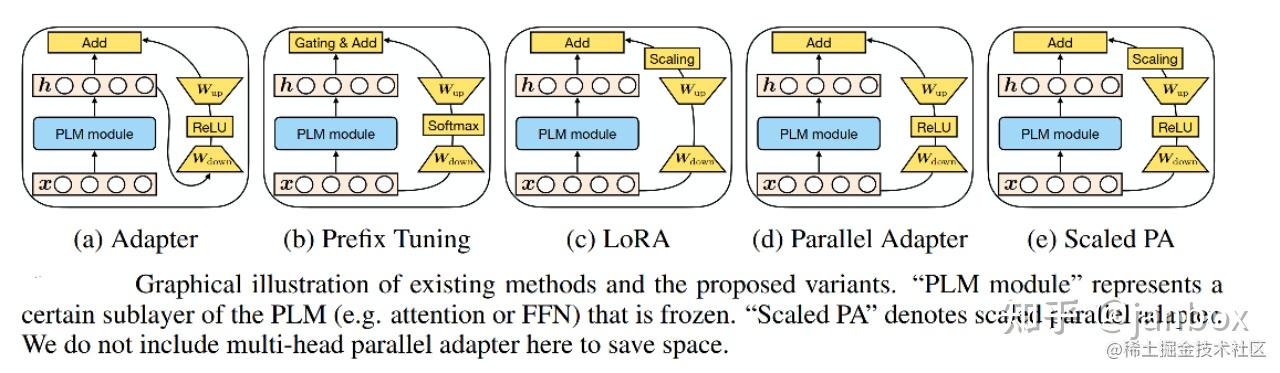
二、模型结构
目前比较成熟,一般采用 gpt架构,Llama/Llama2 -
Transformer-Decoder结构 - PreLayerNorm-RMSNorm 12Paper:Root Mean Square Layer NormalizationAbs:https://proceedings.neurips.cc/paper_files/paper/2019/file/1e8a19426224ca89e83cef47f1e7f53b-Paper.pdf
ROPE旋转位置编码(替换绝对/相对位置编码)
SwiGLU激活函数(替换ReLU) 12Paper:GLU Variants ...

近年来,大型视觉-语言模型(VLMs)的发展(如GPT-4V和GPT-4o)在推动能够在用户界面(UI)中运行的智能代理系统方面展现出了巨大潜力。然而,这些多模态模型在现实应用中的全部潜力仍未得到充分挖掘,尤其是在仅依赖视觉输入,作为通用代理跨越多种操作系统和应用程序执行任务时。一项主要的限制因素是缺乏一种强大的屏幕解析技术,该技术需要能够:
1)可靠地识别用户界面中的可交互图标;
2)理解截图中各元素的语义,并能将目标操作准确地与屏幕上的对应区域关联起来。
为此,微软研究院的研究员们开源了
OmniParser,一个紧凑的屏幕解析模块,能够将用户界面截图转化为大语言模型可以看懂的“结构化元素”。比如识别屏幕上所有可交互的图标和按钮,并用框框标出来,给每个框框一个独一无二的ID;用文字描述每个图标的功能,比如“设置”、“最小化”。识别屏幕上的文字,并提取出来等等。
OmniParser
可以与多种模型配合使用,以创建能够在用户界面上执行操作的智能代理,比如
Phi-3.5-V、Llama-3.2-V 等。OmniParser
可以作为一种通用且易于使用的工具,能够在 PC
和 ...
作者:AI椰青 原文:https://zhuanlan.zhihu.com/p/7827587018
1 引言
视觉语言模型(Vision Language Models,
VLMs)是一类生成模型,能够同时从图像和文本中学习以解决多种任务。
视觉语言模型被广义定义为能够从图像和文本中学习的多模态模型。这类生成模型以图像和文本为输入,生成文本(或图像)作为输出。大型视觉语言模型在零样本学习中表现出色,具有良好的泛化能力,并能够处理多种类型的图像,包括文档、网页等
。Vision Language Models
Explained
近年来,已有大量关于 VLMs 的综述文章 An Introduction to
Vision-Language Modeling,Vision-Language Models for Vision Tasks: A
Survey。因此,本博文将跳过基础介绍,直接聚焦于 2024
年的最新研究趋势。
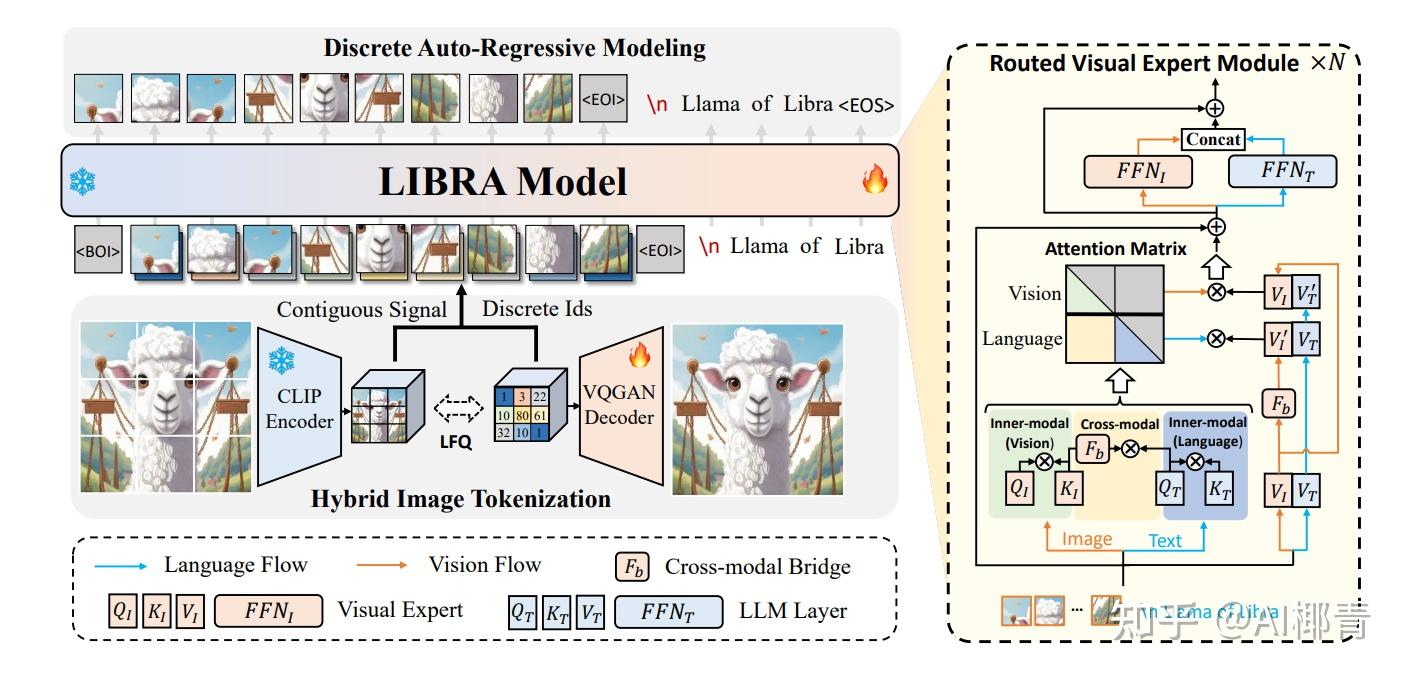
2 多模态设计
一般而言,视觉语言模型(VLMs)有两种主要的设计类型 lecture14-Vision_Language_Model.pdf:
类型
A: ...
前言
豆包Marscode是字节旗下的一款智能开发工具,基于「字节跳动豆包大模型」打造,拥有「云端
IDE」和「编程助手」两大产品形态,不仅支持代码补全、错误修复、AI刷题等能力,还能够帮助开发者在编程的各个阶段提供协助支持,对秋招春招的小伙伴来说,
算法机测是一个必不可少的环节, 有了Marscode, 贪玩的你,
再也不用担心刷leetcode时没有思路的时候,
在网上乱翻资料了。Marscode可以帮助我们节省下时间来摸鱼(学习)。
Marscode的编程助手支持超过100种编程语言,兼容VSCode和JetBrains代码编辑器,使得开发者可以在自己熟悉的开发环境中无缝使用Marscode的功能。此外,Marscode还具备代码解释能力,能够理解项目仓库,帮助用户准确解释代码从而快速上手开发。在修改或重构代码时,Marscode支持基于编辑行为预测下一个改动点,并给出推荐,协助完成编码过程。
起步
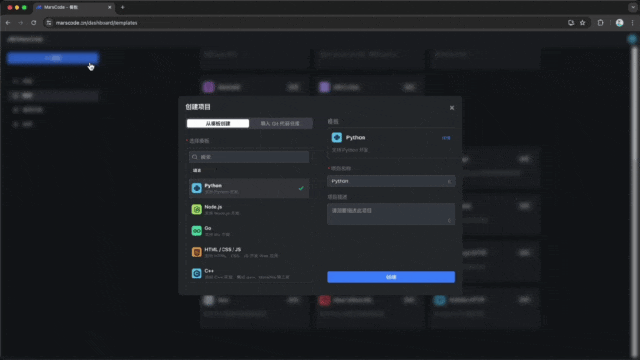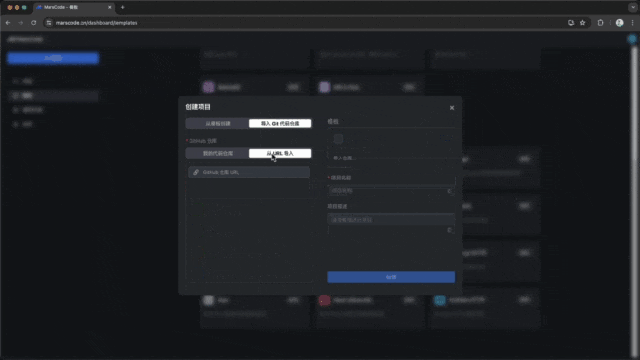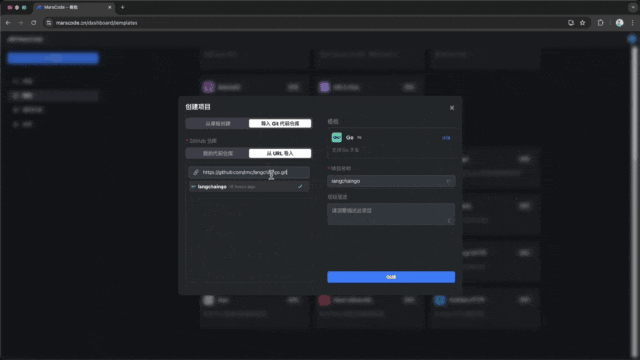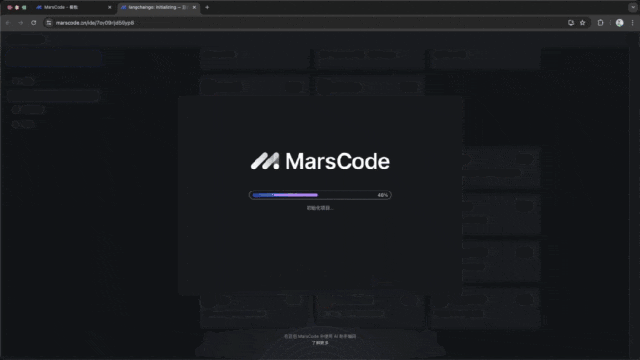
注册&登录
首先需要访问Marscode官网进行注册和登录。值得一提的是,Marscode支持使用抖音或稀土掘金账号快捷登录,这一点对于习惯使用这些平台的用户来说非常方便。
...

VILA 是 NVIDIA Research
提出的一种视觉语言基础模型,它通过在预训练阶段对大型语言模型(LLM)进行增强,使其能够处理和理解视觉信息。其核心思路是将图像和文本数据进行联合建模,通过控制比较和数据增强,提升模型在视觉语言任务上的性能。
https://github.com/NVlabs/VILA
在 VILA
的基础上,还延伸出了集成视频、图像、语言理解和生成的基础模型VILA-U、支持
1024 帧长视频训练和推理的 LongVILA,以及 World Model Benchmark
等工作。
https://github.com/mit-han-lab/vila-u
LongVILA
https://github.com/NVlabs/VILA/blob/main/LongVILA.md
同时,在最新推出的 \(VILA^2\)
中,采用三阶段训练范式:align-pretrain-SFT。该方法引入了一种新颖的增强训练方案,首先在自举循环中进行自我增强
VLM 训练,然后进行专家增强,以利用 SFT
期间获得的技能。这种方法通过改进视觉语义和减少幻 ...
作者:lym
原文:https://www.zhihu.com/question/588325646/answer/3422090041
>> 加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
如果可以用prompt解决,尽量用prompt解决,因为训练(精调)的模型往往通用能力会下降,训练和长期部署成本都比较高,这个成本也包括时间成本。
基于prompt确实不行(情况包括格式输出不稳定、格式输出基本不对、任务不完全会、任务完全不会等情况,难度逐渐加大),选择上SFT微调。
业务场景基本用不到强化学习,强化解决的是最后一公里的问题,可以理解为有两种非常接近的输出(这两种输出都非常接近目标输出,此时已经解决了90%的问题),强化学习会对相同的输入,打压其中一种不希望的输出,同时增强另一种更接近目标的希望的输出(从DPO
loss就可以看出)。强化是用来应对细微输出差异的,并且业务场景优先用DPO,DPO只需要pair对数据,更好构造。PPO的reward
model几乎没有开源的,需要的数据更多,超参也更多,除非是逻辑或代码场景,在文本场景中,DPO效果是 ...

作者:陈陈,TSAIL: 强化学习+生成模型 原文:https://zhuanlan.zhihu.com/p/693746297
>>加入青稞AI技术交流群,与青年研究员/开发者交流最新AI技术
20号下午两位THUNLP的同学(淦渠和立凡)分别给我发了这篇arxiv,询问和上次讨论时谈到的一个理论的联系。简单看了文章后发现几乎完全撞了车。好吧严格讲也不算撞,这篇文章的理论去年十月我大概想明白推导完,但实在想不清楚有啥合适的应用因而给放弃掉了。现在也只能感慨之余写个解读了。
12From r to Q∗: Your Language Model is Secretly a Q-Functionhttps://arxiv.org/pdf/2404.12358.pdf
为什么写这个解读:
本文几乎是DPO的原班人马搞的,新来的Joey
Hejna是X-QL(本文部分核心理论)一作。这篇文章并没有提出一个新的算法,或者是在一个新的任务上刷了SOTA,主要是对DPO算法给出了一个理论解释,统一了处理LLM强化学习任务的两个视角,即序列决策还是单步决策。用强化学习的语言就是说de ...

作者:曹宇,阿里巴巴集团 · 大模型 原文:https://zhuanlan.zhihu.com/p/718913850
>>加入青稞AI技术交流群,与青年研究员/开发者交流最新AI技术
DPO 的论文引用最近已经破千了(现在是1600+),成了斯坦福的Chelsea
Finn组的机器人超猛PhD学生R.M.
Rafailov的第一被引论文。又由于第二梯队的大模型频繁提及DPO的变种,DPO+RM的用法未来估计机器人界的思潮对于LLM的正向影响不会削弱。
按照我平时使用的体验,我们可以将当前的主要头部三强划分为第一梯队,头部开源三强划分成为第二梯队,再加上我一直比较关心的应用侧玩家Apple:
模型
对齐算法
使用 Reward Model
多阶段对齐
Claude Sonnet 3.5
RL PPO
是
未知
OpenAI GPT-4o
RL PPO
是
未知
Gemini Pro
RL REINFORCE
是
是
Deepseek-V2
RL GRPO
是
是
Llama3.1
DPO+RM
是
是
Qwen2
DPO+RM
是
...
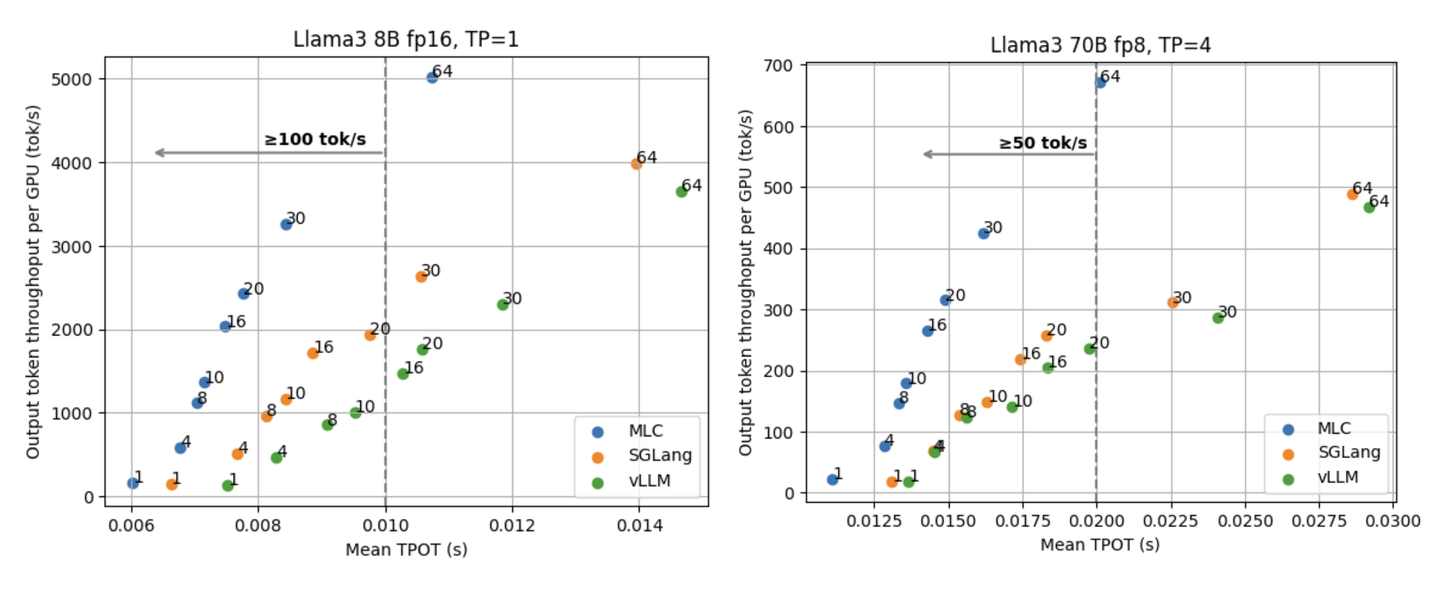
作者:赖睿航,CMU CS Ph.D.(已授权) 原文:https://zhuanlan.zhihu.com/p/903143931
>>加入青稞AI技术交流群,与青年研究员/开发者交流最新AI技术
今年六月初,我们 MLC 团队发布了支持全平台部署的大模型推理引擎
MLCEngine。通过机器学习编译、全平台通用的推理 runtime 和统一的 OpenAI
API 接口,MLCEngine
支持从云端服务器到本地设备的全平台大语言模型部署。
引擎的推理性能长久以来以来都是我们开发 MLCEngine
过程中关注的一大重点。过去这两个多月里,MLC 社区一直在努力提升 MLCEngine
在云端 serving
场景下的性能。我们想通过这篇文章和小伙伴们分享这段时间我们取得的一些成果和经验。
在这篇文章里我们会重点探讨低延迟高吞吐量 (low-latency
high-throughput) 的 LLM 推理。在有非常多优秀的工作聚焦于提升
LLM 引擎总吞吐量的同时,大家能够注意到延迟这一指标对于 LLM
引擎的重要性正在日益增长,而延迟也是大家在使用各大 API ...
