

作者:朱小霖,SDE @Tencent WeChat AI, focusing on MLSys
声明:本文只做分享,版权归原作者,侵权私信删除! 原文:https://zhuanlan.zhihu.com/p/718486708
年初的时候,我尝试去结合了 ring attention 和 flash
attention,并设计了 zigzag ring
attention:
理论上来看,zigzag ring attention 基本做到了线性扩展 context length
的最优解,即:
每张卡上的显存占用不随 context length 扩展;
每张卡基本平分计算与通信;
通信可以和计算 overlap。
然而,当我去把 zigzag ring attention 和 flash attention
结合的时候,遇到了如下的现实问题:
精度损失
因为 ring attention 需要对在 flash attention
的输出进行迭代计算,我们要把 flash attention 输出的 bf16 结果相加。而
bf16 作为一种有效位数极少的数据格式,随便就 ...

作者:季宇(mackler@知乎),行云集成电路的创始人
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://zhuanlan.zhihu.com/p/718191220
最近关于AI泡沫的声音此起彼伏,NVIDIA的股价也跟着此起彼伏,看好和唱衰的都彼此站在长期预期和营收现状的角度争论不休好不热闹。大家说的都有道理,行业周期肯定会有,大模型也确实带来了巨大的想象空间。但有一个假设其实是问题的核心,但双方似乎都默认就应该是这样,那就是支撑大模型的计算机系统的成本就应该这么贵,无非是这么贵的成本到底还有没有大规模商业化机会的争论。
当然这种问题本身也是目前争议最大的话题,和以往一样,很多人都会讲的观点就也不再赘述,我的观点往往非常激进,也希望给大家带来不一样的视角,各位看官酌情食用。
AI大型机才是核心问题
AI大型机是我造的词,能更贴切地描述今天大家所使用的价格高昂的GPU服务器对行业产生的冲击。今天的AI产业以及GPU服务器和历史上的IBM大型机做过类比,IBM大型机可以小规模商业化,但无法支撑PC产业、互联网产业这种级别的繁荣。今天AI泡沫的争论,本质上是类 ...
作者:阿桂,13年软件行业老登,数字孪生,PMP,CSPO
声明:本文已经授权,版权归原作者
原文:https://zhuanlan.zhihu.com/p/717687637
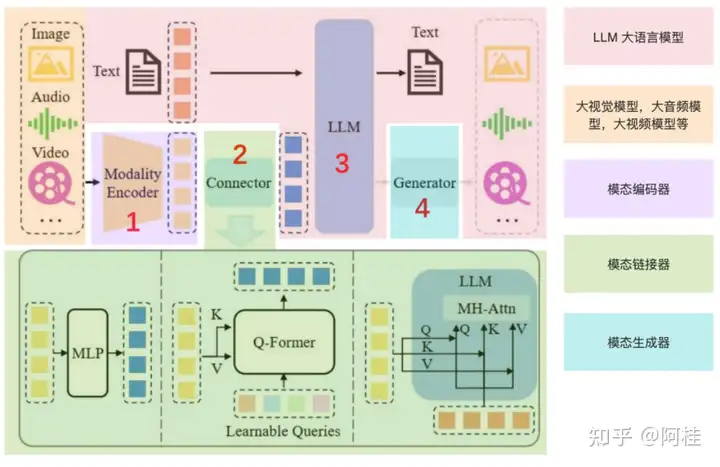
1. 什么是MLLM多模态大语言模型
1.1 先来思考一个问题
如果上传了一张图片,并向大模型提问。“图片中绿色框框中的人是谁?”
大模型回答:“那是波多野吉衣老师”
请问,大模型是怎么做到的?
我们用常规的思路来想一下,难道是:
第一步:先对图片进行目标检测,先把绿色框的内容剪切出来;
第二步:在剪切后的图片中,把人脸标记出来,并读取其landmark转为向量;
第三步:在人脸向量库中进行比对,以便于确定其身份。
整套流程下来,需要用到目标检测,人脸识别,向量存储与比对。最重要的是,还得让人脸识别模型“阅片无数”不然他是不会认识波多野结衣老师的。
但其实,多模态大模型并不是这样处理的。所谓的多模态其实可以理解就是多种数据类型,包括但不限于图片,视频,音频等。它的工作模式并不是将原来的CV模型和NLP模型,通过MultiStage的方式简单粗暴的组合在一起。而是一个端到端的思维。
1.2 为什么会有多模态 ...

支持自由格式的图文输入已然成为前沿多模态大模型的关键能力,然而如何高效地处理随之而来的长视觉内容同时准确建模图文交错输入成为了关键挑战。
mPLUG-Owl3是阿里通义实验室mPLUG团队最新推出的通用多模态大模型,专门用来理解多图、长视频。其引入了一种全新的Hyper-Attention替代了传统的多模态序列拼接的范式,以达到成倍的效率提升。
Hyper-Attention能准确地建模任意图文交错格式下的多模态语义。这使得mPLUG-Owl3相比同尺寸模型不仅具备更低开销,在单图、多图和视频的测评中都能取得state-of-the-art的性能表现,并且在超长视觉内容输入的场景中具有显著的领先优势。
1234567Paper:mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language ModelsAbs:https://arxiv.org/abs/2408.04840Code:https://github.com/X-PLUG/mPLUG-Owl/tree/main/m ...

摘要
本文讨论了尽管大型语言模型(LLM)在处理大量上下文窗口方面取得了进展,但检索增强生成(RAG)与长上下文LLM的持续相关性和潜在整合。
截至2024年7月,语言模型领域已经经历了显著的发展,大型语言模型(LLM)现在能够处理超过128K标记的上下文窗口。这一进展引发了学术界关于检索增强生成(RAG)系统未来的讨论。一些研究人员认为,像Claude
2、Gemini
1.5和Llama-3这样的长上下文LLM的能力可能会使RAG变得过时。然而,另一些研究人员则认为RAG仍然具有价值,尤其是在利基领域和成本效率方面。文章回顾了直观比较和学术研究,指出尽管长上下文LLM在某些基准测试中优于RAG,但在特定领域的准确性和成本效益方面,RAG增强型模型表现更为出色。提出了一种结合RAG与长上下文LLM的混合方法,作为利用两者优势的潜在解决方案。结论建议,RAG和长上下文LLM的协同组合可能是AI应用中最有效的前进路径。
观点
RAG(Retrieval-Augmented
Generation,检索增强生成)并未过时;它在专业领域知识和成本敏感的应用中仍然具有优势。
长上下文LLM(L ...
作者:阿秋Rachel,构建domain big picture
原文:https://zhuanlan.zhihu.com/p/716112475
目前利用多模态大模型进行图像生成主要有以下两种形式:
LLM作为condtioner
利用MLLM依据用户输入的text
prompt来生成条件信息,条件信息被注入到下游生成模型进行更精细化的生成控制。这种形式通常需要外接一个额外专门的多模态生成模型,例如Stable
Diffusion、DALLE-3、GLIGEN等。
条件信息的形式通常是文本,通过利用MLLM对用户输入的text
prompt进行润色,润色后输出的新的text
prompt作为diffusion的文本条件,来生成更加复杂精美的图片。或者通过利用MLLM依据用户输入的text
prompt生成layout信息,其中layout以文本形式指明物体类别和以bounding
box形式指明物体位置。
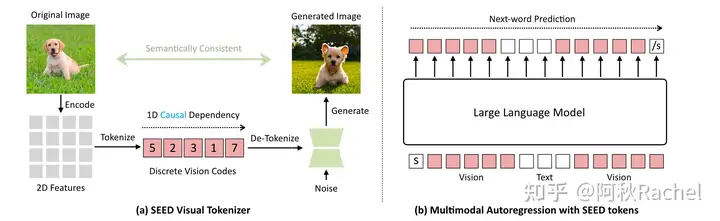
LLM作为generator
利用LLM不断生成image
token完成生成的过程,根据近年的发展,我将其简单分为下面三类。
visual autoregress ...

SGLang 是 LMSYS Org 团队于今年 1 月份正式推出的一个用于 LLM 和 VLM
的通用服务引擎,且完全开源,采用 Apache 2.0 许可授权。它由纯 Python
编写,核心调度器只用了不到 4K 行代码就实现了,已被 LMSYS Chatbot Arena
用于支持部分模型、Databricks、几家初创公司和研究机构,产生了数万亿
token,实现了更快的迭代。
在最新的 SGLang Runtime v0.2 中,其性能更加惊艳。在运行 Llama 3.1
405B 时,它的吞吐量和延迟表现都优于 vLLM 和 TensorRT-LLM,甚至能达到
TensorRT-LLM 的 2.1 倍,vLLm 的 3.8 倍。目前已在 GitHub 上已经收获了超过
4.7k 的 star 量。
此次更新的效果就连 Lepton AI 联合创始人兼 CEO
贾扬清都评价说:我一直被我的博士母校加州大学伯克利分校惊艳,因为它不断交付最先进的人工智能和系统协同设计成果。去年我们看到了
SGLang 的使用,现在它变得更好了。迫不及待地想在产品中部署并尝试新的
SGL ...

来源: 孙鹏飞,南京大学 · 计算机科学与技术 原文:https://zhuanlan.zhihu.com/p/716317173
在实际工作中,经常有人问,7B、14B或70B的模型需要多大的显存才能推理?如果微调他们又需要多大的显存呢?为了回答这个问题整理一份训练或推理需要显存的计算方式。如果大家对具体细节不感兴趣,可以直接参考经验法则评估推理或训练所需要的资源。更简单的方式可以通过这个工具或者huggface官网计算推理/训练需要的显存工具在线评估。
数据精度
开始介绍之前,先说一个重要的概念——数据精度。数据精度指的是信息表示的精细程度,在计算机中是由数据类型和其位数决定的。如果想要计算显存,从“原子”层面来看,就需要知道我们的使用数据的精度,因为精度代表了数据存储的方式,决定了一个数据占多少bit。
目前,精度主要有以下几种:
4 Bytes: FP32 / float32 / 32-bit
2 Bytes: FP16 / float16 / bfloat16 / 16-bit
1 Byte: int8 / 8-bit
0.5 Bytes: int4 / 4-bit
...

对于行业大模型来说,仅仅拥有强大的基座大模型是远远不够的。而通过对一个基座模型使用行业数据进行LoRA微调,可以得到多个小型LoRA适配器作为微调结果。这些适配器的参数虽然非常小(例如只有基础模型参数的1%),但却能更好的适用于特定行业。然而在部署上,又会面临一个新的问题:一个base
model+几千个lora,怎么serving?
S-LoRA解决的就是如何在单台机器上部署数千个同源的LoRA
adapter。当然前提是这些LoRA adapter都是来自同一个base
model的权重。针对从同一基础模型用LoRA微调出来的多个adapter结果,S-Lora的提出者提出了一套高效部署方案。通过扩展Batching策略,PageAttention内存管理策略和并行策略,实现单个GPU服务上千个LoRA
adapter的效果。
123Paper:S-LoRA: Serving Thousands of Concurrent LoRA AdaptersAbs:https://arxiv.org/pdf/2311.03285.pdfCode:https://github.com/S- ...

作者:绝密伏击,奇虎360 算法资深专家
原文:https://zhuanlan.zhihu.com/p/712441972
OpenAI
的神秘项目“草莓”是什么?
近期,继去年备受瞩目的神秘项目「Q*」之后,OpenAI 再次传来新动向。
据路透社报道,OpenAI
内部正秘密研发一个代号为「草莓(Strawberry)」的新人工智能模型项目。
此前,该模型的细节从未被外界知晓,而 OpenAI
正致力于证明这一新型模型能够展现出高级推理能力。
路透社在五月份获取了一份 OpenAI
的内部文件副本,其中详细阐述了团队对「草莓」的研究计划。
然而,即便是 OpenAI
内部员工,对于「草莓」的工作原理也知之甚少,其保密程度之高可见一斑。
值得注意的是,还记得去年报道的 Q* 吗?
当时有媒体报道称,OpenAI CEO Sam Altman 未及时向董事会披露 Q*
的进展,这一事件被视为引发 OpenAI
“内部纷争”的重要导火索。更令人担忧的是,OpenAI内部人士曾担忧 Q*
的重大突破可能威胁到全人类。
而据路透社报道,Q* 实则是「草莓」项目的前身,在去年的报道中 ...
