

这篇超长的文章(部分是评论,部分是探索)是关于 GPT-5
的。但它的内容远不止于此。它讲述了我们对下一代人工智能模型的期望。它讲述了即将出现的令人兴奋的新功能(如推理和代理)。它讲述了
GPT-5 技术和 GPT-5 产品。它讲述了 OpenAI
面临的竞争业务压力以及其工程师面临的技术限制。它讲述了所有这些事情——这就是为什么它有
14,000 个字那么长。
你现在想知道,既然你已经听说了有关 GPT-5
的泄密和谣言,为什么还要花一个小时阅读这篇迷你书大小的文章。答案是:如果没有背景,零散的信息是无用的;只有当你把所有信息都放在一个地方时,大局才会清晰。就是这样。
在我们开始之前,我们先简单介绍一下 OpenAI
的成功历程,以及为什么人们对 GPT-5
的巨大期待会给他们带来压力。四年前,也就是 2020 年,GPT-3震惊了科技界。谷歌、Meta
和微软等公司纷纷挑战 OpenAI 的领先地位。他们确实这么做了(例如LaMDA、OPT、MT-NLG),但仅仅几年后。到
2023 年初,在 ChatGPT 取得成功(引起 OpenAI
的广泛关注)之后,他们准备发布GPT-4 ...

AWQ 是由 MIT
韩松教授团队推出的一种针对大型语言模型(LLMs)的高效且精确的低位权重量化(INT3/4)方法,通过仅保护1%的显著权重就可以大大减少量化误差,且支持指令调整模型和多模态语言模型。代码已经开源!
123Paper:AWQ: Activation-aware Weight Quantization for LLM Compression and AccelerationAbs:https://arxiv.org/abs/2306.00978Code:https://github.com/mit-han-lab/llm-awq
为了识别显著的权重通道,应参考激活分布,而不是权重。为了避免硬件低效的混合精度量化,通过数学推导得出,放大显著通道可以减少量化误差。AWQ采用等效变换来放大显著权重通道以保护它们。该比例通过离线收集激活统计数据确定。AWQ不依赖任何反向传播或重构,因此可以泛化到不同的领域和模态,而不会过拟合校准集。
AWQ 在桌面和移动 GPU 上比 Huggingface 的 FP16
实现快3倍以上。它还实现了在移动 GPU 上部署 70B Llama ...

随着大语言模型的兴起,多模态大模型也取得了显著进步,推动了复杂的视觉语言对话和交互,弥合了文本与视觉信息之间的鸿沟。然而,现有的开源模型与商用闭源模型(如GPT-4o和Gemini
1.5 Pro)之间的能力差距仍然显著。
InternVL
2.0,中文名称为"书生·万象”,是“开源社区最强多模态大模型”。其涵盖图像,视频,文字,语音、三维点云等5种模态,首创渐进式对齐训练,实现了首个与大语言模型对齐的视觉基础模型,通过模型”从小到大”、数据”从粗到精"的渐进式的训练策略,以1/5成本完成了大模型的训练。
InternVL 2.0
在有限资源下展现出卓越的性能表现,横扫国内外开源大模型,媲美国际顶尖商业模型,同时也是国内首个在MMMU(多学科问答)上突破60的模型。它在数学、图表分析、OCR等任务中,更是取得了可比肩GPT-4o、Gemini
1.5 Pro等闭源商用大模型的性能。
数值对比表
8月6日晚7点,青稞Talk第18期,香港中文大学博士后、上海人工智能实验室青年科学家、“书生”系列视觉基础模型核心开发者王文海,将直播分享《InternVL
2.0:通过渐进式策略扩展 ...

生成图文并茂的多模态故事已成为一个具有广泛应用前景的任务。然而,这一任务带来了巨大的挑战,因为它需要模型理解文本和图像之间复杂的相互关系,并具备生成长序列连贯且情境相关的文本和视觉内容的能力。
来自香港科技大学(广州)、腾讯的研究者提出了SEED-Story,这是一种利用多模态大语言模型(MLLM)生成长序列多模态故事的新方法。该模型基于MLLM强大的理解能力,预测文本token和视觉token,这些token随后通过visual
de-tokenizer处理,生成具有一致角色和风格的图像。推理阶段,研究者们提出了多模态注意力汇聚机制,使得能够高效自回归地生成长达25个序列(训练时仅为10个序列)的故事。
此外,研究者们还推出了一个名为StoryStream的大规模高分辨率数据集,用于训练模型并在各个方面定量评估多模态故事生成任务。
123Paper:SEED-Story: Multimodal Long Story Generation with Large Language ModelarXiv:https://arxiv.org/abs/2407.08683Code:htt ...

在自然图像与视频目标检测与识别领域,传统方法通常在预定义类别的数据集上训练,无法识别数据集中未出现的目标类别,缺乏零样本检测能力,识别能力有限。
来自Tencent AI Lab、ARC Lab、Tencent PCG 以及华中科技大学的研究者们在
CVPR 2024
上提出了基于视觉语言建模的开放词汇YOLO-World模型,并探索针对YOLO检测器的大规模数据预训练方法,赋予
YOLO
模型零样本检测能力与语言理解能力,在推理速度和零样本检测精度上均领先先前工作。
YOLO-World模型目前已经在腾讯内部多项业务中落地,并与海外多家公司达成商业合作。
7月23日晚7点,青稞Talk第16期,华中科技大学博士生程天恒,将直播分享《YOLO-World:基于视觉语言模型的实时开放词汇物体检测》。
Talk信息
主讲嘉宾
程天恒,华中科技大学博士生;2019年获得华中科技大学(HUST)电子信息与通信专业的学士学位;研究兴趣包括计算机视觉、通用物体检测与分割以及多模态视觉模型,在人工智能与计算机视觉的顶级会议上发表学术论文11篇。
主题
YOLO-World:基于视觉 ...

迈向实用多模态大模型的路上存在许多阻碍,MiniCPM-V
是面向图文理解的端侧多模态大模型系列。该系列模型通过 MiniCPM 高效
scaling law、VisCPM 跨语言泛化、RLHF-V 和 RLAIF-V
可信行为学习、LLaVA-UHD 高清图编码等技术在端侧实现了接近 GPT-4V
级别的效果。
1Code:https://github.com/OpenBMB/MiniCPM-V/tree/main
目前该系列最值得关注的模型包括:
MiniCPM-Llama3-V 2.5:MiniCPM-V
系列里最新版本模型,基于 SigLip-400M 和 Llama3-8B-Instruct
构建,总参数量8B,多模态综合性能超越 GPT-4V-1106、Gemini
Pro、Claude 3、Qwen-VL-Max 等商用闭源模型,OCR
能力及指令跟随能力进一步提升,并支持超过30种语言的多模态交互。通过系统使用模型量化、CPU、NPU、编译优化等高效推理技术,MiniCPM-Llama3-V
2.5 可以实现高效的终端设备部署。
MiniCPM-V 2.0:Min ...

多模态大语言模型(MLLM)是目前的热门研究领域。随着AI手机的迅速发展,手机自动化操作更是成为了
AI
时代各大手机厂商的重要应用。然而,受限于有限的数据和特定的屏幕感知方式,现有的
MLLM 在手机 UI 感知、理解和操作上的表现不足以实现自动化操作。
Mobile-Agent是阿里通义实验室所推出的自动化移动设备操作助手,一句话指令就能让手机自动完成特定任务。其V1版本于年初发布,凭借强大的自动化手机操作能力,引起了AI界和手机厂商的广泛关注,仅5个月的时间就已在Github上收获了2,000个Star。
Mobile-Agent-V1
基于纯视觉方案,通过视觉==感知==工具和操作工具实现智能体在手机上的操作,而不依赖其他系统级别的UI文件。借助智能体中枢模型强大的操作能力,Mobile-Agent无需训练和探索,能够实现即插即用。
而最新推出的 Mobile-Agent-v2 版本,在 V1
的基础上继续保留了纯视觉方案,并基于多模态Agent架构构建,可以实现更强的任务拆解、跨应用操作和多语言能力。
12345Abs:[1]https://arxiv.org/abs ...
大家好,这里是减论8分钟极减专栏系列,《从分布到生成》专题第三集。本集信息量极大,观点视角极度新颖炸裂,请大家屏住呼吸,别眨眼,且听我慢慢道来。
在“从分布到生成(一、二)”中,我们已经带领大家极减地理解了什么是图像的分布P(X),以及如何使用映射来采样生成复杂分布的样本。还不清楚的小伙伴可以移步一、二系列内容进行学习。
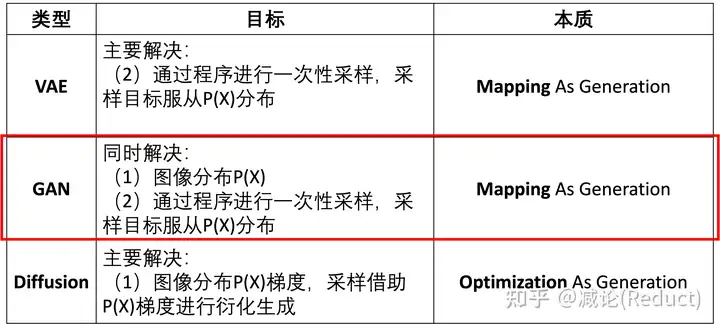
图一:GAN同时解决2个目标
本次专题第三集,我们来尝试回答GAN是如何同时解决那两个采样难题的(图一红框所示),即:
• 如何找到图像分布P(X)?
• 如何通过程序进行一次性采样,采样目标服从P(X)分布?
此前我们提到过,图像分布P(X)非常复杂,精确地求出每个P(X=…) =
…的概率数值通常是不现实的,另外很精确其实也没有太大的必要。那么我们把思路做一下简化:
假设我们已经知道了P(X),并且是用神经网络D(X,w’)来逼近表示的,其中w’是该神经网络固定的参数。我们每输入一个张量实例X,都能通过D(X,w’)得到其准确的概率数值:P(X)
= D(X,w’),如图二所示:
图二:用一个已知的神经网络D完美逼近表示真实图像分布P
那么,当我们 ...
大家好,这里是减论系列专栏,《从分布到生成》专题第二集。
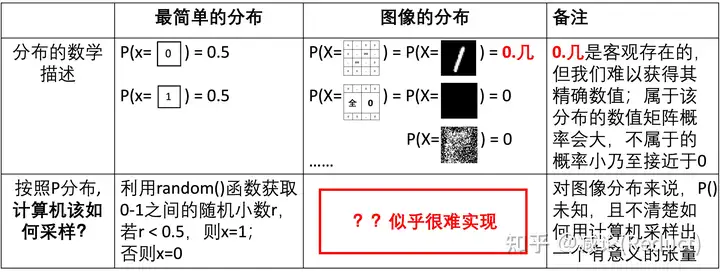
图一:分布描述与采样的类比
上回说到,如图一所示,简单的分布例如伯努利分布、均匀分布、高斯分布都可以借助程序语言中的random(),
normal()等基础的伪随机函数进行计算机采样模拟。然而,服从特定的分布P(X)的图像(例如0-9黑白数字图像)却似乎很难借助计算机的某个函数采样实现,这个难点体现在2个方面:
我们很难知道具体的图像分布P(X);
即使我们知道了图像分布P(X)精确值,如何通过程序进行一次性采样并能服从P(X)也不清楚。
为了解决从某个特定分布P(X)进行图像采样的任务(即图像生成任务),业界进行了长期的努力并衍生出3大主要流派:VAE(变分自编码器)、GAN(对抗生成网络)和Diffusion(扩散模型)。在图二中,我们将这三个流派与上述两个难点进行关联,看看各自都是从哪个难点入手进行解决的。
图二:VAE,
GAN与Diffusion解决目标及本质对比
接下来的事情就比较有趣了。
从本质上来看:
VAE尝试重点解决第二个难点(2),通过程序进行一次性采样,采样目标服从P(X)分布,具体是 ...

LLaMA Factory
是一个高效、易用、可扩展的开源大模型高效训练框架,在GitHub开源社区获得超过25000关注,得到多家国内外企业的关注或落地应用。
123Paper:LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language ModelsAbs:http://arxiv.org/abs/2403.13372Code:https://github.com/hiyouga/LLaMA-Factory
项目特色
多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi
等等。
集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO
训练、DPO 训练、KTO 训练、ORPO 训练等等。
多种精度:16 比特全参数微调、冻结微调、LoRA
微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA
微调。
先进算法:GaLore、BAdam、DoRA、 ...
