

作者:唐业辉,华为 · 算法研究员
声明:本文已经授权,版权归原作者!
原文:https://zhuanlan.zhihu.com/p/697627446
传统多模态模型将视觉特征和输入文本拼接起来,作为大语言模型的输入。这种方式显著增加了语言模型的输入长度,大幅拖慢了语言模型的推理速度。大语言模型中的前馈神经模块(FFN)作为记忆单元来存储学到的知识,我们提出了一种视觉模态和语言模态融合的新范式,将视觉特征直接注入到FFN的参数中,基于记忆空间来实现多模态大模型的高效微调(MemVP)。相比LoRA、VL-Adapter等现有方法,训练&推理加速2倍,在下游任务依然可以取得更高精度。
123paper:Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning arxiv:https://arxiv.org/pdf/2405.05615 code:https://github.com/JieShibo/MemVP
` # 引言
随着视觉模型和大语言模型的发展,视觉-语言模型的 ...

基准测试能够帮助从业者衡量大语言模型的能力。为了加速大语言模型的开发,一个能够快速评估大语言模型解决实际问题潜力的基准测试非常受欢迎。现有的基准测试往往无法反映现实世界用户查询的分布,或者需要耗时的人工干预。
来自新加坡国立大学的倪瑾杰博士,在最新的研究成果中提出了一种基于真实数据构建的大型语言模型基准测试方法:MixEval。该方法弥补了可靠但昂贵的真实世界查询与快速但有偏差的实验室评估之间的差距。通过利用从网络上挖掘的用户查询,将其与现有基准测试中的类似查询匹配,MixEval
紧密地反映了真实用户查询的分布。
广泛的分析表明,与现有的基准测试相比,作为一个静态基准测试,MixEval可以提供一个准确的评估,很好地与人类评级对齐(例如与Chatbot
Arena的相关性为0.96),只需在GPU上运行脚本,如MMLU,无需缓慢且成本高昂的人类偏好数据收集。同时,倪瑾杰博士还提供了对MixEval和其他流行的大型语言模型基准测试的全面鸟瞰分析,以研究它们的内在属性和关系,这可能进一步加深社区对大型语言模型评估的理解。
5月24日晚7点,青稞社区组织【青稞Talk】第七期,新加 ...

3D Gaussian
Splatting(3DGS)是一种用于三维场景表示和视图合成的技术。它结合了基于原语的表示方法和体素(volumetric)表示方法的优点,以提高渲染的质量和效率。其核心优势在于它能够以一种高效且连续的方式来表示复杂的三维场景,并且可以通过现代GPU硬件实现快速渲染。
来自华南理工大学几何感知与智能实验室的梁智灏博士,在最新的研究成果中,提出了一种针对逆渲染问题的
3DGS 框架 GS-IR。GS-IR
结合基于物理的渲染使得3DGS重打光任务变为可能。与使用隐式神经表示和体渲染(例如NeRF)的先前工作相比,GS-IR
通过从多视角图像中估计场景几何、表面材质和环境照明,解决了表达力低下和计算复杂性高的问题。
123paper:GS-IR: 3D Gaussian Splatting for Inverse RenderingarXiv:https://arxiv.org/abs/2311.16473code:https://github.com/lzhnb/GS-IR
同时,针对 3DGS 中的走样问题,梁智灏博士也实现了 3DGS
的反走样:Anal ...

作者:孟繁续,北京大学博士生 ,研究方向
LLM(大型语言模型)和模型压缩
主页:fxmeng.github.io
声明:原文已经授权,版权归原作者!
原文:https://zhuanlan.zhihu.com/p/636784644
LLaMA-3又出来了,综合表现非常惊艳,我在实际测试中能力也比LLaMA-2-7B,Mistral-7B和Gemma-7B效果好。模型还是直接复用之前的代码,不过最小的8B模型也用上了GQA了,实测速度挺快。手头的llama-2可以丢了,可以拥抱llama-3了。
llama2
出来了,并且开源可商用,这下开源社区又要变天了。快速看一下官网以及paper,看看llamav2相比v1有什么更新吧:
预训练语料从1->2 Trillion tokens
context window 长度从2048->4096
收集了100k人类标注数据进行SFT
收集了1M人类偏好数据进行RLHF
在reasoning, coding, proficiency, and knowledge
tests上表现超越MPT和Falcon
和falcon一样,使 ...
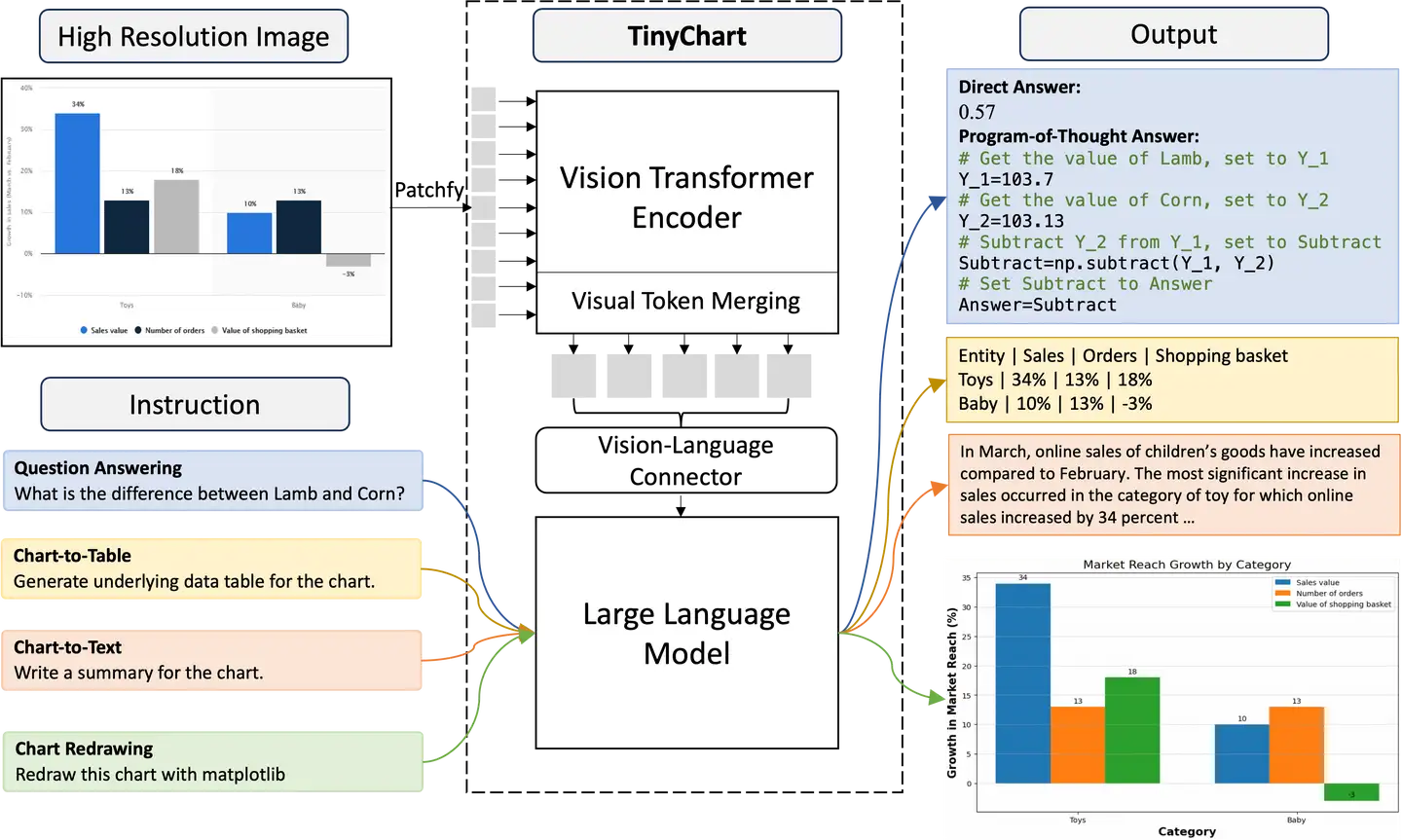
作者:Anwen
Hu,人大博士毕业生,阿里巴巴通义实验室高级算法工程师
声明:原文已经授权,版权归原作者!
原文:https://zhuanlan.zhihu.com/p/696540858
作为一种重要的信息来源,图表(Chart)能够直观地展示数据关系,被广泛地应用于信息传播、商业预测和学术研究中
[1]。
随着互联网数据的激增,自动化图表理解受到广泛关注,近期诸如GPT-4V、QwenVL-Max和Gemini-Ultra等通用闭源多模态大模型都展现出一定的图表理解能力,开源模型Chartllama
[2]、ChartAst
[3]等也在图表问题回答、图表总结和图表转换等任务上取得强大的性能。
然而,目前开源的图表理解模型有以下三个局限:
模型参数规模庞大,难以部署到应用中。例如Chartllama包含13B参数,无法直接部署到单张小于26
GB显存的消费级显卡上 [4]。
模型容易出现数值错误,尤其是回答涉及数值计算的问题时
[3]。
模型无法高效处理高清图片,而许多关键信息(比如OCR文本)往往需要在较高分辨率下才清晰可见。并且,考虑到标准视觉Transformer会 ...
方向:
多模态/计算机视觉/生成模型/自动驾驶/可信机器学习/高效机器学习
招收职位:
博士、实习生
联系教授:
Dr. Zhengzhong Tu (vztu.github.io)
🏫 学校介绍
德克萨斯A&M大学(Texas A&M
University,TAMU)是一所世界顶尖的公立研究型大学,建立于1876年,世界百强名校,得州第一所公立大学。TAMU是北美顶尖研究型大学联盟美国大学协会(AAU)成员,全美第六大公立高校。该校与得克萨斯大学奥斯汀分校(本人母校)并称德州两大旗舰学府。2024
U.S. News美国最佳大学排名47名(比去年前进20名!)。
作为一所传统理工科强校,TAMU在工程领域享有盛誉,并在2024 U.S.
NEWS最佳工程学院排名中位列前十。TAMU计算机科学与工程系在国际学术界和工业界受到广泛认可,在CSRankings排名(2014-2024)中位列全美第32位,在2024
U.S.
NEWS最佳计算机科学排名中位列第45位、计算机工程位列第20位。迄今为止,学校共有诺贝尔奖获得者9位、国家科学勋章获得者3位、普利策奖获得者1位、 ...

现有的视觉-语言-动作(VLA)模型主要基于二维输入,未能有效整合三维物理世界,且在行动预测上忽视了动态场景与动作间的关系。相比之下,人类能够借助内在的3D世界模型来模拟未来事件,从而更好地规划行动。
为此,UMass Amherst、上海交大联合提出了一种新型的3D视觉-语言-行动生成世界模型
3D-VLA。3D-VLA
是一个基于三维大型语言模型(3D-LLM),并且能够连接三维感知、推理和动作预测的世界模型。
此外,为了将生成能力注入模型,他们还训练了一系列具身扩散模型,并将它们与LLM对齐,以预测目标图像和点云。此外,为了训练我们的3D-VLA,通过从现有机器人数据集中提取大量3D相关信息,他们策划了一个大规模的3D具身指令数据集。在数据集上的实验表明,3D
VLA在具身环境中显著改善了推理、多模
态生成和规划能力,展示了其在实际应用中的潜力。
123paper:3D-VLA: A 3D Vision-Language-Action Generative World ModelarXiv:https://arxiv.org/abs/2403.09631code:https:/ ...
作者:张俊林,新浪微博新技术研发负责人
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://www.zhihu.com/question/653373334/answer/3471466524
LLAMA-3的发布是大模型开源届的大事,蹭下热度,在这里谈下有关LLAMA-3、大模型开源与闭源以及合成数据的一些个人看法。
一.LLAMA-3的基本情况
模型结构与LLAMA-2相比没有大的变动,主要变化一点在于Token词典从LLAMA-2的32K拓展到了128K,以增加编码效率;另外一点是引入了Grouped
Query Attention
(GQA),这可以减少推理过程中的KV缓存大小,增加推理效率;还有一点是输入上下文长度从4K拓展到了8K,这个长度相比竞品来说仍然有点短。
最重要的改变是训练数据量的极大扩充,从LLAMA-2的2T
Tokens,扩展了大约8倍到了15T
Tokens,其中代码数据扩充了4倍,这导致LLAMA-3在代码能力和逻辑推理能力的大幅度提升。15
T token数据那是相当之大了,传闻中GPT 4是用了13T的Token数据。
LLA ...

尽管 VLM 取得了进步,促进了基本的视觉对话和推理,但与 GPT-4
和 Gemini 等高级模型相比,性能差距仍然存在。那如何在学术环境中以可接受的成本推动VLMs接近成熟模型呢?
来自香港中文大学的贾佳亚团队新提出了多模态大模型 Mini-Gemini,堪比
GPT-4 + DALL-E 3 王炸组合。
在这项工作中,研究者主要探究了目前多模态模型的潜力,并从三个方面进行提升:
对高清细节信息的挖掘
多模态模型训练数据的质量
与生成模型的结合
具体来说,研究者通过引入双分支视觉编码器,在保持 LLM
计算效率的情况下拓展对高清图像的理解。并通过优化训练数据的方式来提升多模态模型的性能和对生成任务的支持,从而在保证多模态模型基础性能的同时实现图像理解、推理和生成的统一。实验表明在多种
zero-shot 的榜单上超越现有开源甚至闭源商业模型,并能够支持从 2B 至 34B
的多种大语言基座模型。 12345Github 地址:https://github.com/dvlab-research/MiniGemini Demo 地址: http://103.170.5.190: ...

大型语言模型(LLM)和视觉语言模型(VLM)在理解和生成语言方面表现出色,但它们并不以
3D 物理世界为基础,更不用说在更丰富的 3D 具身环境中探索和互动了。
加州大学洛杉矶分校的洪艺宁博士及来自 MIT-IBM Watson AI Lab
等研究人员在最新的成果中开发了 3D
具身基础模型,致力于构建能够主动探索和与 3D
物理世界互动。这些模型促进了与3D空间的动态互动,融入了空间关系、可利用性、物理、布局、多感官学习等基本具身智能概念。
在 NeurIPS 2023 的 Spotlight 成果 3D-LLM 中,她们将 3D
世界注入大型语言模型中,用 3D 点云及其特征作为输入,并执行各种 3D
相关任务,包括字幕、密集字幕、3D 问答、任务分解、3D 基础、3D
辅助对话、导航等。
123paper:3D-LLM: Injecting the 3D World into Large Language ModelsarXiv:https://arxiv.org/abs/2307.12981code:https://github.com/UMass-Foundation ...
