

# 自我介绍
大家好!我叫王欢,将于2024年夏季加入西湖大学任助理教授(Tenure-Track
Assistant Professor), ENCODE (Efficient Neural Computing and Design)
Lab PI。
此前我在浙大读完本科和硕士,在美国东北大学读完博士。在Google / Snap /
MERL / Alibaba等研究机构实习。我的研究方向是Efficient AI、Computer
Vision,更多信息欢迎参考我的个人主页。
https://huanwang.tech/
现招收 PhD students (2025 Fall) 和 RA、Visiting
Students(常年招收)。
学校简介
西湖大学是一所社会力量举办、国家重点支持的新型高等学校,前身为浙江西湖高等研究院,于2018
年正式获教育部批准设立。西湖的定位是成为小而精的研究型大学,目前有4个学院(理学院,工学院,生命科学学院,医学院)。工学院下有6个专业,我所在的是人工智能和数据科学(Artificial
Intelligence and Data Scien ...

AI
智能体是最近很火的一个话题。斯坦福大学吴恩达教授在一次演讲中表示:“基于
GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。AI
智能体工作流将在今年推动人工智能取得巨大进步,甚至可能超过下一代基础模型,这是一个值得所有人关注的趋势。”
其中,吴恩达教授还点赞了来自清华大学自然语言处理实验室、面壁智能的大模型驱动的全流程自动化软件开发框架
ChatDev(Chat-powered Software
Development):一个由多智能体协作运营的虚拟软件公司,在人类用户指定一个具体的任务需求后,不同角色的智能体将进行交互式协同,以生产一个完整软件(包括源代码、环境依赖说明书、用户手册等)。
这一技术为软件开发自动化提供了新的可能性,支持快捷高效且经济实惠的软件制作,未来将有效地将部分人力从传统软件开发的繁重劳动中解放出来。
123paper:Communicative Agents for Software Developmentarxiv:https://arxiv.org/abs/2307.07924code:https://github.com/O ...

基于扩散模型的三维纹理图生成方法在单个物体上已经取得了令人惊艳的成果,但场景级纹理图生成领域还有待探索,其难点在于其生成尺度远大于单个物体,对于生成的纹理细节以及风格一致性要求也更高。因而,现有的单个物体级三维纹理图生成方法难以被直接迁移到场景级目标上。
来自慕尼黑工业大学视觉计算实验室的陈振宇博士等人在最新的 CVPR
论文中,提出了一种基于二维扩散模型的场景级三维纹理图生成方法
SceneTex。与之前的基于 Inpainting 的三维纹理图生成方法不同的是,SceneTex
将整个纹理图生成过程转化为一个全局优化问题。SceneTex
的算法核心在提出了一个多分辨率的纹理图特征场,以用于在多尺度上隐式编码场景外观信息。
为了进一步提高场景中每一个物体的外观一致性,以及整个场景风格的一致性,SceneTex提出了一个基于跨注意力机制的纹理图解码器,有效地在生成过程中避免了物体自遮挡问题,并极大程度地提高了场景纹理图的生成质量。该项目已在GitHub开源。
123paper:SceneTex: High-Quality Texture Synthesis for Indoor Sc ...

作者:张俊林,新浪微博新技术研发负责人
声明:本文只做分享,版权归原作者,侵权私信删除
原文链接:https://zhuanlan.zhihu.com/p/687928845 |
https://zhuanlan.zhihu.com/p/684089478
Sora生成的视频效果好吗?确实好。Sora算得上AGI发展历程上的里程碑吗?我个人觉得算。我们知道它效果好就行了,有必要知道Sora到底是怎么做的吗?我觉得最好是每个人能有知情的选择权,任何想知道的人都能够知道,这种状态比较好。那我们知道Sora到底是怎么做出来的吗?不知道。
马斯克讽刺OpenAI是CloseAI,为示道不同,转头就把Grok开源了。且不论Grok效果是否足够好,马斯克此举是否有表演成分,能开源出来这行为就值得称赞。OpenAI树大招风,目前被树立成技术封闭的头号代表,想想花了上亿美金做出来的大模型,凭啥要开源?不开源确实也正常。所谓“开源固然可赞,闭源亦可理解”。
但是,我个人一年多来的感觉,OpenAI技术强归强,然而有逐渐把技术神秘化的倾向,如果不信您可以去读一下Altman的各种访谈。在这个AI技术 ...

作者:Anwen Hu,人大博士毕业生,阿里巴巴通义实验室高级算法工程师
原文链接:https://zhuanlan.zhihu.com/p/687993277
多模态大模型 Multimodal LLM (MLLM)
相关研究致力于实现通用的图片理解,其中类别多样、文字丰富且排版复杂的文档图片一直是阻碍多模态大模型实现通用的痛点。当前爆火的多模态大模型QwenVL-Max,
Gemini, Cloude3,
GPT4V都具备很强的文档图片理解能力,然而开源模型在这个方向上的进展缓慢,距离这些闭源大模型具有很大差距
(例如DocVQA上开源7B SOTA 66.5,而Gemini Pro 1.5为86.5)。
mPLUG-DocOwl 1.5
是阿里巴巴mPLUG团队在多模态文档图片理解领域的最新开源工作,在10个文档理解benchmark上达到最优效果,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果。
123paper:mPLUG-DocOwl 1.5: Unified Structure Learning f ...

作者:潘梓正,莫纳什大学博士生 主页:zizhengpan.github.io
原文链接:https://zhuanlan.zhihu.com/p/685943779
最近看到有些问题[1]说为什么Transformer中的FFN一直没有大的改动。21年刚入学做ViT的时候就想这个问题,现在读博生涯也快结束了,刚好看到这个问题,打算稍微写写,
也算是对这个地方做一个小总结吧。
1. Transformer与FFN
Transformer的基本单位就是一层block这里,一个block包含 MSA +
FFN,目前公认的说法是,
• Attention 作为token-mixer做spatial interaction。
• FFN
(又称MLP)在后面作为channel-mixer进一步增强representation。
从2017至今,过去绝大部分Transformer优化,尤其是针对NLP
tasks的Efficient Transformer都是在Attention上的,因为文本有显著的long
sequence问题。安利一个很好的总结Efficient Transforme ...

最近,无论是 OpenAI 的 Sora 模型,还是 Stability AI 的 Stable
Diffusion 3 ,都让我们看到了生成模型方面的突破。这也让我们不禁思考:AIGC
领域的微积分时刻是否已经到来?
3月2日晚8点,青稞社区策划推出【青稞Panel】第一期,并邀请到DeepFaceLab(累计60,000
+⭐️)作者小黑兔、InstantID(huggingface
space周榜第一)作者王浩帆、剑桥大学计算机系在读博士Andi Zhang和VBench
第一作者、南洋理工大学MMLab在读博士黄子琪参与,共同探讨《Sora迷思,AIGC的微积分时刻?》。
alt text
参与嘉宾
王浩帆,CMU(卡耐基梅隆)硕士毕业,InstantX成员,代表工作InstantID(huggingface
space周榜第一,Yann Lecun转发点赞),Score-CAM(累计1000+ google
citation),发表过 NeurIPS、CVPR、ICCV、3DV 等多个领域顶级会议。
Andi
Zhang,剑桥大学计算机数学双硕士,剑桥大学计算机系博士生 ...
作者:李博杰, Logenic AI
联合创始人、中科大与MSRA联培计算机博士、华为天才少年
个人主页:https://01.me/
原文链接:https://zhuanlan.zhihu.com/p/681283469
(本文是 2024 年 1 月 6 日笔者在知乎首届 AI
先行者沙龙上的演讲实录)
非常荣幸能够认识大家,非常荣幸能够来知乎 AI
的先行者沙龙来做分享,我是李博杰,Logenic AI 联合创始人。我们知道目前 AI
Agent 非常火,比如说参加路演 70 多个项目,一半多都是跟 AI Agents
相关的项目, AI Agents
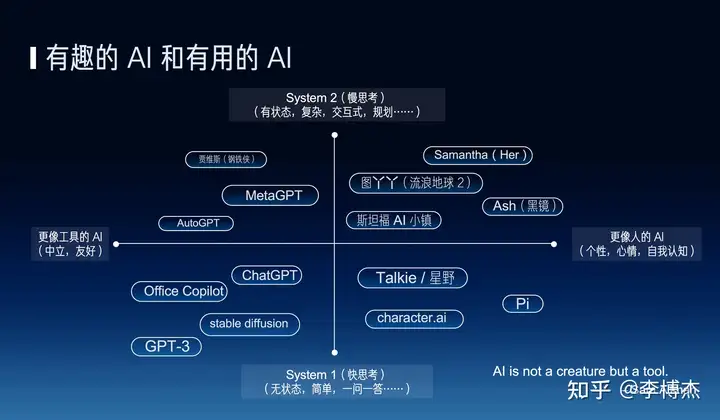
的未来会是什么样子呢?它未来应该是更有趣还是更有用呢?
我们知道 AI 的发展目前一直有两个方向,一个是有趣的 AI,一个是更像人的
AI,另外一个方向就是更有用的 AI,也就是 AI
应该更像人还是更像工具呢?其实是有很多争议的。比如说 OpenAI 的 CEO Sam
Altman 他就说 AI
应该是一个工具,它不应该是一个生命,但是我们现在所做的事正好相反,我们现在是让
AI 其实更像人,其实很多科幻电影里的 AI ...

阿里巴巴通义实验室
自然语言智能团队介绍
阿里巴巴通义实验室,自然语言智能团队主要负责通义系列大模型研究与产品落地。其中我们智能对话与服务技术团队,以大模型研究和应用为中心,以AI智能体为核心交互形态,推进大模型的大规模商业化应用,主要技术包括:
(1)AI Agents
(2)个性化大模型
(3)多模态等
过去三年发表40+篇国际顶会论文,包括ICML、EMNLP、ACL、CVPR等各领域顶会;主要技术研究方向包括:
1、通义星尘-个性化大模型,类CharacterAI角色扮演应用,打造更好的AI情感陪伴智能体应用;
2、ModelScope-Agent,开源的可定制化的通用Agent框架和Agent智能体大模型;
3、多模态mPLUG大模型系列,包括mPLUG、mPLUG-2、mPLUG-owl等工作。
团队Github:
https://github.com/X-PLUG
招聘岗位
Research Intern /
算法专家(P6/P7)
坐标:杭州、北京 类型:实习/社招
岗位职责
1、负责Agent框架和Agent底座的优化,包括但不限于multi-agent应用,pl ...

周末加班干活了~
img
1234Project page: https://humanaigc.github.io/animate-anyone/Code: https://github.com/HumanAIGC/AnimateAnyoneArxiv: https://arxiv.org/pdf/2311.17117.pdfYoutube Video: https://www.youtube.com/watch?v=8PCn5hLKNu4
前言
Animate Anyone是阿里巴巴通义实验室XR
Lab最新推出的成果,只需要单张图片和Openpose动作就可以让图片动起来并保持稳定性。
具体来说,Animate Anyone是基于Diffusion model
(扩散模型结构)来进行pose2video的生成,通过如2D
openpose的姿态骨架skeleton,来引导(guide)网络生成和参考图像reference
image一致的角度动态效果。
Animate
Anyone也是第一个在Pose2Video领域生成角色动画达到80分成绩的方法。Twitter上各 ...
